IndexedDB 를 활용한 풀필먼트 시스템 고도화
이종민
2021-04-19
Overview
현재 브랜디에서 헬피셀러들에게 제공하고 있는 풀필먼트 시스템 내, IndexedDB 가 적용된 부분을 일부 소개하고 추가로 적용하면 좋을 부분이 있는지 검토해봤습니다.
Contents
- IndexedDB 란
- 풀필먼트 시스템에 적용된 IndexedDB
- 추가 적용에 대한 검토
- 마무리
1. IndexedDB 란
IndexedDB에 대한 소개는 MDN(링크)에 잘 되어있습니다. 간단히 설명하면 트랜잭션을 사용하는 JavaScript 기반의 객체지향 데이터베이스로, 사용자의 브라우저 안에 데이터를 영구적으로 저장하게 해주는 방법 중 하나입니다. 주요 특징은 아래와 같고, 자세한 설명은 MDN을 참조해보시면 좋을 것 같습니다.
- 키(key)-값(value) 한 쌍을 저장하며, 빠른 검색을 위해 저장된 계산뿐만 아니라 객체의 속성을 사용하는 인덱스를 만들 수 있습니다.
- 데이터베이스에 적용하는 모든 변경은 트랜잭션 안에서 일어나며, 동일 출처정책을 따라 한 도메인의 데이터에 접근하는 동안 다른 도메인의 데이터에 접근할 수 없습니다.
- 대부분 비동기 방식의 API로 이루어져 있으며, 이에 따라 값을 반환하는 방식이 아닌 콜백함수를 전달해야합니다.
2. 풀필먼트 시스템에 적용된 IndexedDB
풀필먼트 시스템에 적용된 IndexedDB 중 두 가지 정도를 소개해 보고자 합니다.
합포 기능에 적용된 IndexedDB
풀필먼트 시스템 내에는 합포라는 기능이 있습니다. 고객의 주문이 들어오면, 현재 보유하고 있는 상품의 재고에 따라 각 주문에 재고를 할당합니다. 그러고 나서, 할당된 주문을 서비스 내에서 잡은 기준대로 합포를 진행합니다.
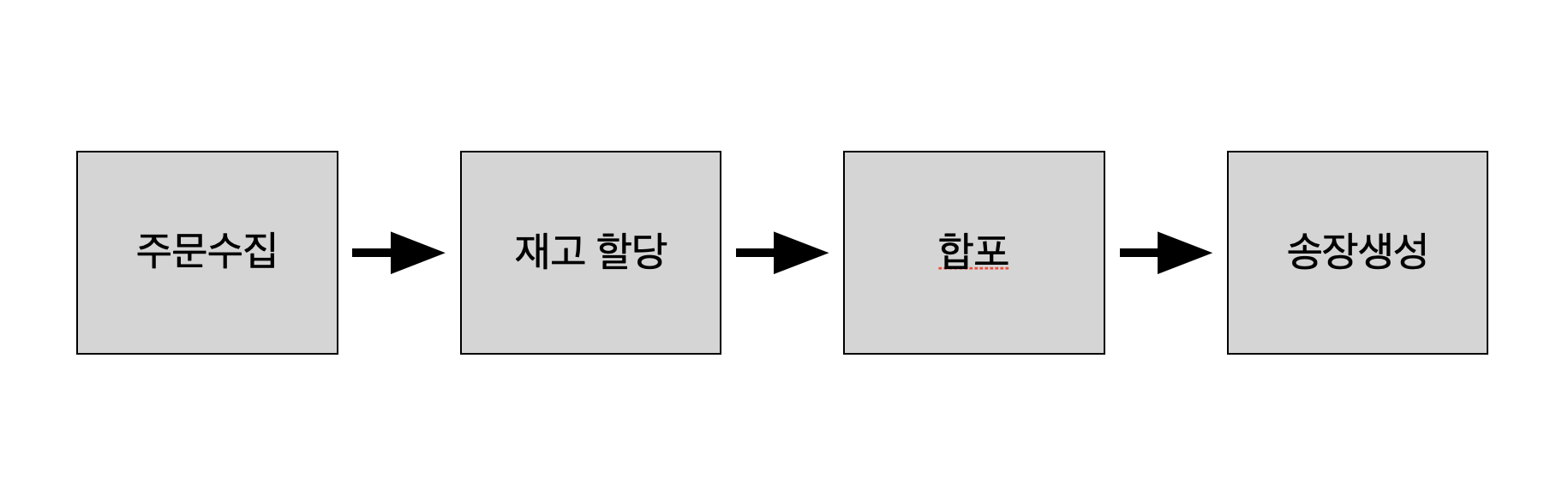
합포라는 개념이 생소 하실수도 있습니다. 예를 들어 A 주문 건과 B 주문 건이 각기 다르게 접수 되었는데, 서비스 내에서 잡은 기준(ex. 주문자명, 연락처, 주소가 동일)에 부합한다면 하나의 포장으로 묶어 배송을 진행한다는 개념입니다. 이렇게 적합한 합포가 이루어지면, 고객 입장에서는 배송을 한 번에 받아볼 수 있어서 좋고, 회사 입장에서는 불필요한 물류비가 들지 않아 서로 윈윈할 수 있습니다.
이제 기능에 대해 설명을 드리자면, 기존에 합포 처리 로직은 아래와 같이 처리되었습니다.

할당된 주문 건을 조회해 온 후, 전체 데이터를 스캔하며 현재 확인 중인 주문 건과 다른 주문 건의 특정 조건이 합포 조건에 맞는지 확인하는 프로세스를 거쳤습니다.
초반에 베타 서비스를 진행할 때는 연동되는 주문 건이 많지 않아 무리 없이 처리가 되었는데, 점차 연동하는 셀러와 주문 건이 늘어나면서 브라우저가 말 그대로 뻗는 현상이 발생했습니다. 10만건의 합포 대상 데이터가 있다고 가정하면, 이 데이터를 계속 반복해서 조회하면서, 조건에 맞는 다른 주문 건이 있는지 찾아야 했기에 브라우저에 무리가 간 것이죠.
이때 IndexedDB 가 등장합니다. IndexedDB 는 이름에서 볼 수 있듯이 키 값들을 인덱싱하여 DB 에 저장할 수 있는데요. 이렇게 하면 예시처럼 ‘주문자명+연락처+주소’ 등의 방식으로 인덱스를 조합하여 IndexedDB 에 담아둘 수 있게 되었습니다. 이렇게 복합 인덱스를 사용하면 검색을 할 때 더 효율적으로 동작합니다.

이후에는 조회에 강점을 가진 NoSQL 답게 이전과는 비교할 수 없을 정도의 속도를 내며 합포 로직을 처리할 수 있게 되었습니다.
재고 일괄 조정 기능에 적용된 IndexedDB
풀필먼트 시스템의 또 다른 기능 중의 하나인 재고 일괄 조정 기능에도 IndexedDB 가 녹아들어있습니다.
재고 일괄 조정 기능은 한 번에 다량의 상품에 대한 재고를 조정할 때 사용하는 기능인데요. 다루고 있는 상품이 많다 보니 대용량 처리에 대비할 필요가 있었습니다.
담긴 데이터의 양에 따라 길게는 수분에서 수십 분까지 처리 시간이 소요가 되는데, 중간에 네트워크 오류 등의 이유로 프로세스가 중단된다면 아주 난감한 상황이 펼쳐질 수 있었습니다. 로그를 통해 중단된 지점을 확인하는 방법도 있겠지만, 이보다는 따로 기록을 보관해두고 있다가 중단된 지점부터 다시 시작할 수 있게 해주는 로직을 구현해 더욱 편의를 주었습니다.
단순히 한 row 씩 꺼내 쓰기 때문에 indexing 의 장점을 활용하진 않지만, local storage 는 용량의 문제로 담기가 어렵고, API 를 통해 DB 에 기록을 담자니 과해 보였습니다.
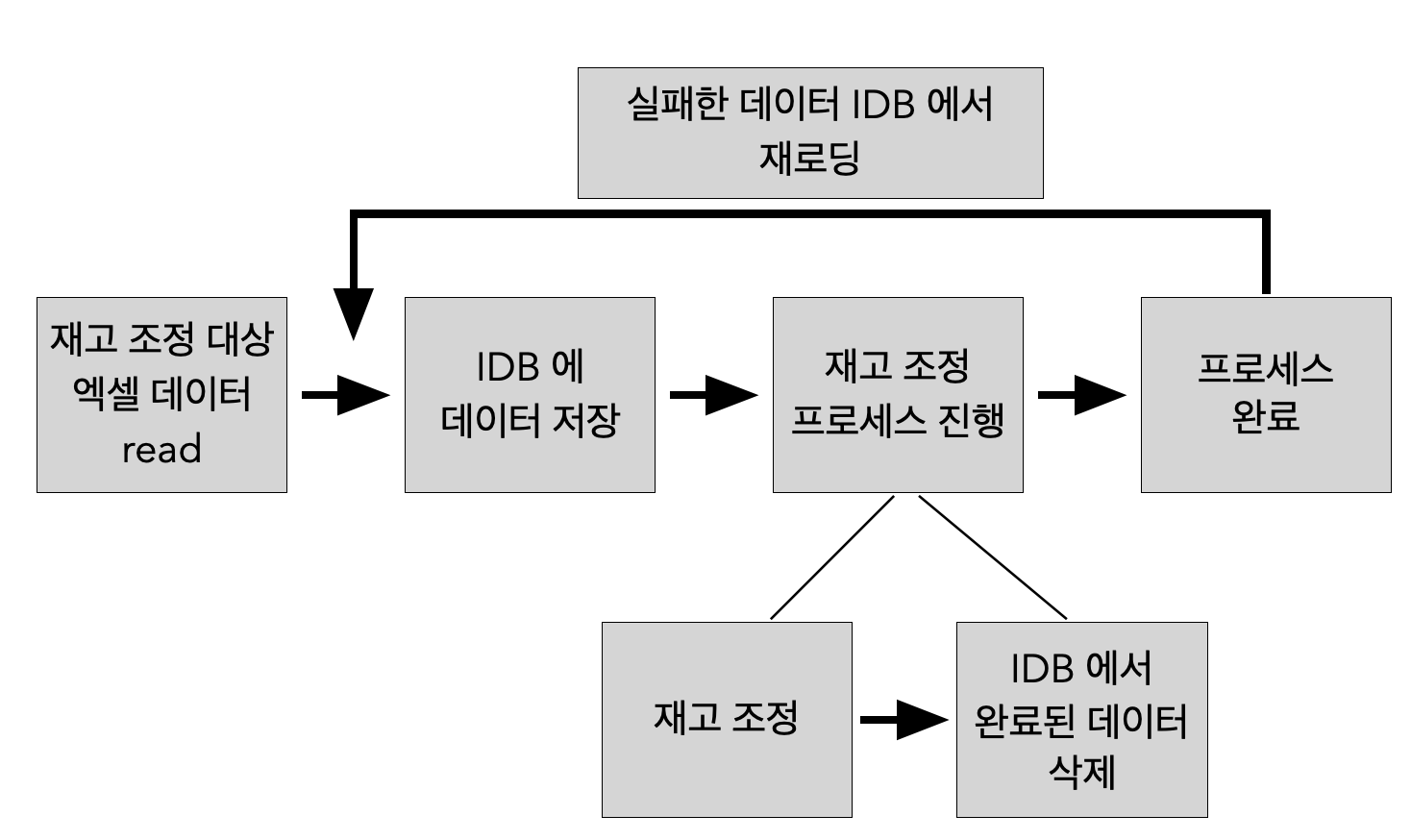
로직은 간단합니다.
재고를 일괄 조정할 데이터를 IndexedDB 에 담아두고, row 를 한 개씩 꺼내다가 재고 조정을 하고, 조정이 끝난 데이터는 IndexedDB 에서 삭제합니다. 그리고 모든 재고의 조정이 완료되면 IndexedDB 를 삭제합니다.
만약 프로세스 진행 중 에러가 발생하면, 새로고침 후 IndexedDB 에 저장된 데이터를 불러 와서 다시 프로세스를 진행할 수 있도록 안내합니다.
3. 추가 적용에 대한 검토
송장출력 로직에 대한 IndexedDB 적용을 검토해봤습니다. 현재 송장출력 로직을 간단히 설명하자면 이렇습니다.
송장생성 로직이 진행되면, 송장 출력에 필요한 데이터를 DynamoDB 에 적재합니다.
송장출력 페이지에서는 이 DynamoDB 에 적재된 데이터를 조회해 온 후, 출력하고자 하는 송장을 선택해 실제 출력을 진행합니다.
이 과정에서 한 번에 출력하고자 하는 송장이 많을 때 문제가 발생할 수 있습니다. 사용자 편의상 한 번에 수만 건의 송장 정보를 한 번에 조회해 출력을 진행하는데, 출력 도중에 문제가 생기면 끊어진 부분부터 다시 출력하는데 애로사항이 있었습니다.
그래서 최초 출력 프로세스를 진행할 때 IndexedDB 에 출력용 데이터를 담아두고 하나씩 꺼내어 출력 하면서, 출력 요청이 끝나면 IndexedDB의 해당 row를 삭제하는 방식으로 구현해봤습니다.
IDB(IndexedDB)를 다루기 쉽게 해주는 라이브러리는 Dexie.js, PouchDB 등 여러가지가 있는데, 현재 저희 팀에서 사용하고 있는 Dexie.js 를 활용해서 IDB를 구현했습니다. 개발 환경은 Vue.js 입니다.
IDB 및 ObjectStore 생성
제일 먼저 할 일은 IDB 인스턴스를 생성하는 일 입니다. Vue 가 마운트되면 IDB 인스턴스가 생성되도록 합니다. Dexie.js 를 이용하면, 아래와 같이 IDB를 생성할 수 있습니다. 이후 버전을 명시하고, Object Store 를 선언하면 기초 세팅이 끝납니다.
mounted () {
// IDB 생성
this.IDB = new Dexie('invoice_print_list')
// Object Store 생성. 버전, Object Store명, keypath 등 설정
this.IDB.version(3).stores({
// tmp -> Object Store 명
// 'INVOICE_ORDER' 라는 unique index 를 사용하고,
// 'SENDER_ADDR1 + SENDER_ADDR2 + SENDER_NAME' 세개의 데이터를 합쳐 복합 인덱슬 사용
tmp : '&INVOICE_ORDER,[SENDER_ADDR1+SENDER_ADDR2+SENDER_NAME]',
})
}
Object Store 를 선언할 때, 위와 같이 key 와 index 를 함께 명시할 수 있습니다. 출력된 데이터를 삭제하는 기준을 송장 순번으로 할 것이기 때문에 unique index 로 ‘INVOICE_ORDER’를 사용했고, 이번에 사용을 하지는 않지만 ‘주소 + 수령자 명’을 의미하는 ‘SENDER_ADDR1 + SENDER_ADDR2 + SENDER_NAME’로 복합인덱스를 만들어봤습니다.
key 와 index 관련된 내용은 아래 페이지에 자세히 설명되어 있습니다.
https://dexie.org/docs/Version/Version.stores()
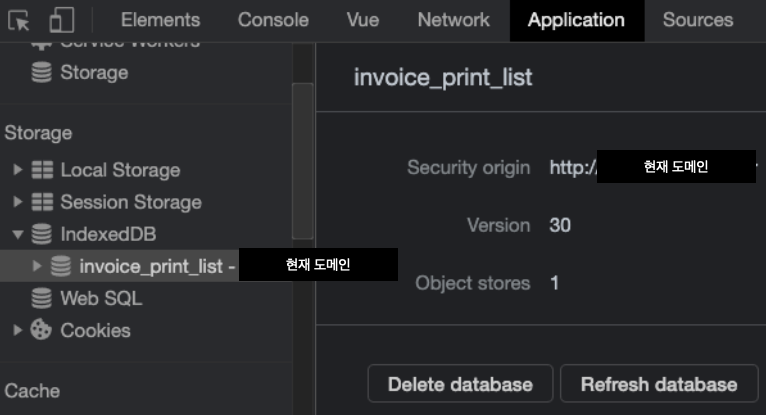
생성 후에 개발자도구에서 Application 탭에 가보시면 IndexedDB 에 ‘invoice_print_list’라는 DB가 생긴 것을 보실 수 있고, 그 안에는 ‘tmp’ 라는 Object Store 가 생긴 것을 보실 수 있습니다. 그리고 그 안에는 복합 인덱스 기준으로 만들어진 공간도 함께 보실 수 있습니다.
이제 송장출력을 진행할 때, 출력을 진행하려는 데이터를 IDB 에 넣는 작업을 해보겠습니다.
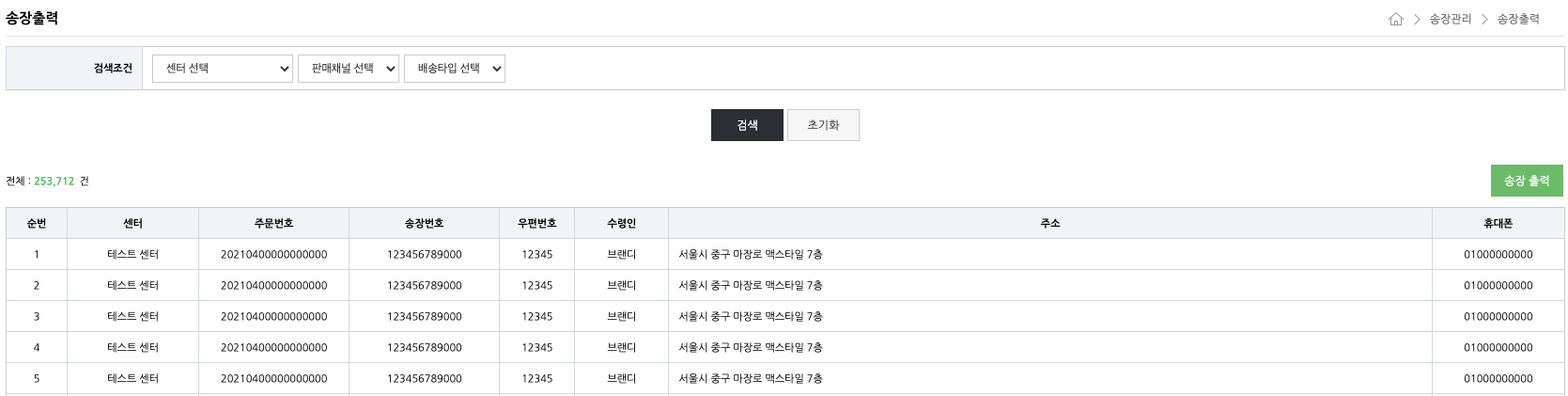
저희 시스템의 송장출력 페이지는 대략 아래와 같이 생겼는데요, 송장출력 버튼을 누르면 순번 기준으로 출력하고자 하는 범위를 선택하고 출력 프로세스를 진행합니다.
제가 선택한 방법은 출력하고자 하는 범위를 선택한 다음, 실제 출력 프로세스 진행으로 넘어가기 전에 IDB 에 데이터를 보존해 두는 방법입니다.
기존 IDB 데이터 삭제
출력 데이터를 저장하기에 앞서, 이전에 저장해두었던 송장 실패 리스트가 있다면 삭제합니다. 새로운 송장데이터를 조회 했다는 건 이전에 실패한 리스트를 다시 출력하지 않겠다는 의미이기 때문에, 데이터가 섞이지 않게 하기 위한 의도입니다. 참고로 대부분의 IDB API 는 Promise 객체를 반환하기 때문에, await 로 순서를 보장 받을 수 있습니다.
// 기존 DB 데이터 삭제
await Dexie.delete('invoice_print_list')
트랜잭션 열기 및 bulkPut
IDB를 사용하기 위해서는 먼저 IDB 를 열어두어야 합니다. open 이 되고 난 후에는 트랜잭션을 열어줍니다. 트랜잭션이 필수는 아니지만, 데이터 정합성을 보장받기 위해서 사용합니다.
트랜잭션 안에서 bulkPut 을 실행하고 완료되면 출력을 진행합니다. bulkPut 은 주어진 데이터를 한 번에 IDB 로 밀어넣는 역할을 합니다. 비슷한 메서드로 bulkAdd 가 있는데, bulkAdd 는 동일한 key 가 IDB 에 들어있으면 bulkError 를 반환하기에, 데이터를 덮어쓸 수 있는 bulkPut 을 사용했습니다. (사실 이 로직 전에 기존 IDB 데이터를 삭제하기 때문에 bulkAdd 를 사용해도 됩니다)
정상적으로 bulkPut 이 완료되면, 원본 데이터를 이용해 각각의 송장 데이터에 대한 출력을 진행합니다.
// IDB 열기
this.IDB.open().then(() => {
// 트랜잭션 열기
this.IDB.transaction('rw', this.IDB.tmp, async () => {
// transaction이 적용되는 zone
// bulkPut 실행
console.log('start bulkPut')
await this.IDB.tmp.bulkPut(splitData)
console.log('end bulkPut')
}).then(async () => {
console.log('start print process')
// 원본 데이터로 출력 진행
for (let i = 0; i < splitData.length; i++) {
// 프린터 출력 메서드
await this.printSendSample(splitData[i])
}
console.log('end print process')
}).catch((e) => console.log(e))
})
송장출력 프로세스는 console 을 찍어보는 것으로 대체했습니다. 각각의 출력 순번에 따른 출력 요청이 끝나면, 트랜잭션을 열고 해당 순번의 IDB row 를 삭제합니다.
// 송장출력 대용 프로세스
async printSendSample (printData) {
console.log(`INVOICE_ORDER ${printData.INVOICE_ORDER} data is printed`)
await this.IDB.transaction('rw', this.IDB.tmp, async () => {
await this.IDB.tmp.delete(printData.INVOICE_ORDER)
}).then(() => console.log(`INVOICE_ORDER ${printData.INVOICE_ORDER} data in IDB is deleted`))
.catch(() => console.log(`INVOICE_ORDER ${printData.INVOICE_ORDER} data deleting is failed`))
},
현재까지 작성된 코드를 실행하면 console 창에 아래와 같이 프로세스 로그가 남깁니다.
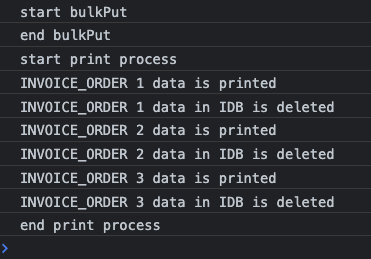
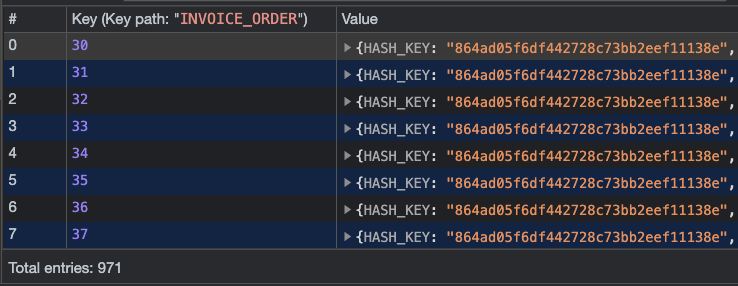
만약 출력이 진행되는 도중 프로세스가 멈추게 되면, 아래와 같이 Object Store 에 출력이 진행되지 않아 삭제되지 않은 데이터들을 볼 수 있습니다.
- Primary Key 기준으로 삽입된 Object Store(tmp)
- 복합 인덱스로 인덱싱 된 버전
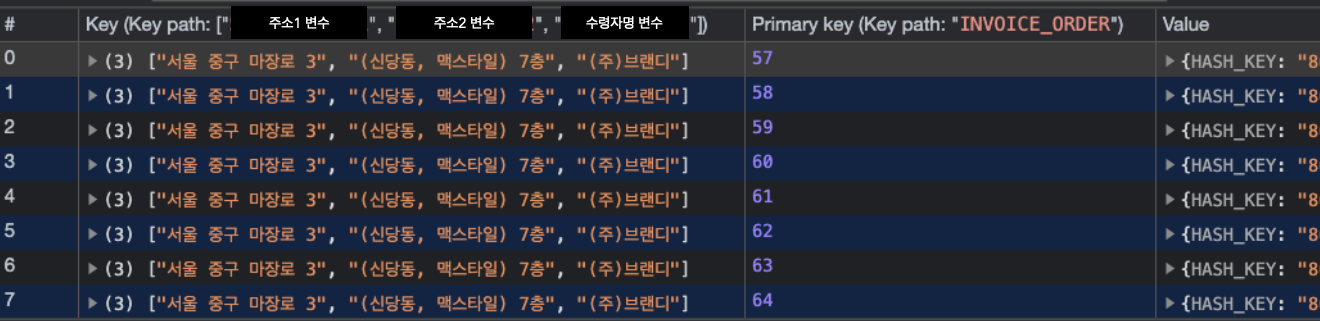
실패한 송장에 대한 출력 재시도
연 이제 실패한 송장들을 다시 출력해보려 합니다.
새로고침을 한 뒤에 IDB에 저장되어있는 출력되지 못한 송장 데이터들을 불러올 건데요. 제일 처음 작성했던 mounted 로직에 내용을 반영했습니다. Vue 가 마운트 됐을 때 IDB 에 저장된 송장 데이터가 있으면, 따로 조회하지 않아도 송장 리스트들을 조회 화면에 띄워주는 방식입니다.
toArray() 메서드를 이용하면 Object Store 에 있는 모든 데이터를 불러올 수 있고, 불러온 데이터를 Array 형태로 콜백함수에 넘겨줍니다. 이 Array 값을 조회 결과에 뿌려주는 invoiceList 에 넣어주면 프로세스는 끝이 납니다.
mounted () {
// IDB 생성
this.IDB = new Dexie('invoice_print_list')
// Object Store 생성. 버전, Object Store명, keypath 등 설정
this.IDB.version(3).stores({
tmp : '&INVOICE_ORDER,[SENDER_ADDR1+SENDER_ADDR2+SENDER_NAME]',
})
this.IDB.open().then(() => {
// IDB에 남아있는 출력 실패 송장 리스트를 재로딩
this.IDB.tmp.toArray().then(result => { // IDB 데이터를 Array 형태로 콜백 파라미터에 전달
if (result.length > 0) {
this.invoiceList = result
console.log('Reloading fail list is completed.')
}
})
})
}
4. 마무리
신입 개발자로서 처음 랩스 블로그를 작성하게 되니 부담감이 좀 있었는데, 쓰고 나니 배우는 부분도 많고 속도 후련합니다.
개인 블로그가 아니기에 주제를 정하고 글을 쓰는데도 어려움이 좀 있었습니다. 그런데 작성을 하다보니 작성하는 게 더 어렵더라고요. IndexedDB 를 차치하고도 비동기라는 개념을 활용하는 데 있어서 지식이 부족함을 많이 느꼈습니다. 덕분에 시간을 더 써가면서 개념을 이해하려고 했고 이제는 좀 더 비동기라는 개념에 가까워진 것 같습니다.
개인적으로 부족함이 아직 많다고 느끼게 된 계기가 되었지만, 다음에는 좀 더 발전한 지식과 글로 찾아오겠습니다.
참고자료
- MDN_IndexedDB - https://developer.mozilla.org/ko/docs/Web/API/IndexedDB_API
- Dexie.js (A Minimalistic Wrapper for IndexedDB) - https://dexie.org/
이종민 | 풀필먼트개발실 풀필먼트개발팀



