단일 TABLE을 SELECT하자!
올바른 SELECT문만 있다면 막힌 업무가 술술
한석종 팀장
2018-03-27
Overview
DB를 다뤄봤다면 SELECT문도 아실 겁니다. 가장 먼저 접하는 명령어 중에 하나이기도 하죠. 보통은 아래처럼 사용합니다.
SELECT문
SELECT
*
FROM 테이블명
;
명령을 주면 지정한 테이블에 저장된 모든 내용을 검색합니다. 이번 글에서는 테이블을 만들고 SELECT하는 과정을 다뤄보겠습니다. DB는 MySQL 5.6을 기준으로 하고, Tool은 MySQLWorkbench를 사용하겠습니다.
Query, 너란 녀석
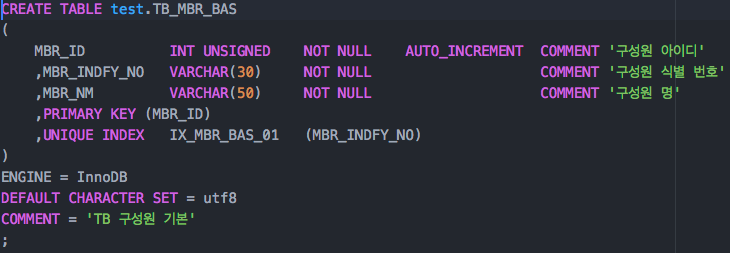
테이블은 위와 같이 생성할 수 있습니다. 위의 내용은 MySQLWorkbench를 이용해 Model을 표시하면 아래와 같습니다.
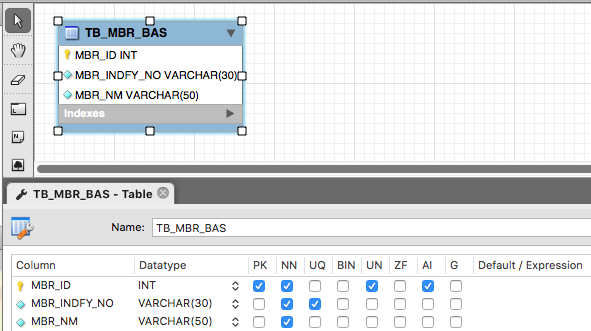
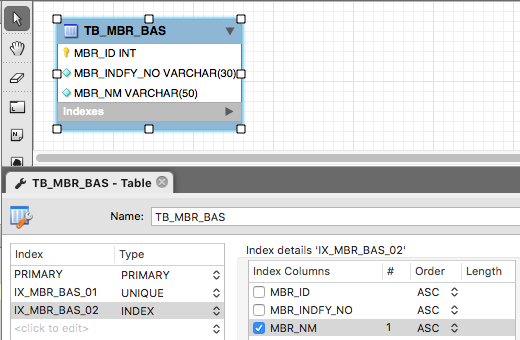
구성원의 정보를 저장하도록 했고, 컬럼마다 의미를 갖게 됩니다.
- MBR_ID (구성원 아이디) : DB에서 구성원을 식별하는 아이디
- MBR_INDFY_NO (구성원 식별 번호) : 구성원을 실제 구별하는 번호로 과거에는 주민등록번호가 많이 사용되었고, 요즘은 e-mail 이 많이 사용됩니다.
- MBR_NM (구성원 명) : 구성원의 이름
테스트 데이터를 입력해 실행하면 어떤 결과가 나오는지 보겠습니다.

가장 기본적인 SELECT문 실행계획을 보면 아래와 같이 나옵니다.

실행 계획은 DB가 어떻게 Query를 수행할 건지 보여줍니다. Query가 복잡해지면 실행 계획을 보면서 Query가 올바르게 작성됐는지 확인하고 필요하다면 Query를 수정해야 합니다. DB를 시작할 때부터 실행 계획을 보는 습관을 기르는 게 중요한 이유입니다.
각 항목에 대한 설명
- id : SELECT 문에 있는 순차 식별자로 Query 를 구분하는 아이디
- select_type : SELECT의 유형
SIMPLE : Subquery나 union 이 없는 단순한 SELECT - table : 참조되는 테이블의 명칭
TB_MBR_BAS : 참조되는 테이블명 - type : 검색하는 방식
ALL : TABLE의 모든 ROW를 스캔
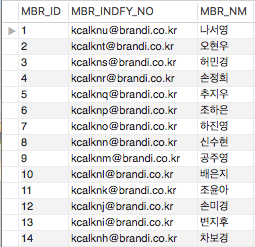
위의 이미지는 임의로 만든 자료를 이용해 Query를 실행한 결과입니다. 실행 계획은 TABLE : TB_MBR_BAS 를 TYPE : ALL 전체 검색한다고 나옵니다. 실행한 내용도 같습니다. 여기서 MBR_NM 이 “나서영”인 자료를 검색해볼까요.


WHERE 조건이 들어가자 실행 계획도 내용이 변경되었습니다. rows와 Extra에도 값이 있는데요. 두 항목을 잠시 짚고 넘어가겠습니다.
- rows : Query를 수행하기 위해 접근해야 하는 열의 수
- Extra : MySQL 이 Query 를 수행할때의 추가 정보
Using where : Query 수행시 TABLE에서 값을 가져와 조건을 필터링 함
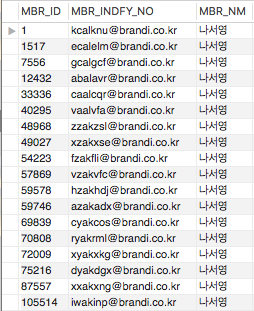
위의 결과처럼 전체를 검색해 필요한 자료만 추출하는 것을 FULL TABLE SCAN or FULL SCAN 이라고 합니다. 그러나 FULL SCAN은 성능이 좋지 않기 때문에 우선 꼭 필요한 Query인지 검토해야 합니다. 보통 MBR_NM에 INDEX를 추가해서 해결하는데요. INDEX를 추가해서 같은 Query를 수행하면 실행 계획은 어떻게 달라질까요.


분명 같은 Query였는데 INDEX에 따라 실행 계획이 변경된 걸 알 수 있습니다. INDEX를 추가해도 수행한 결과는 같지만 검색 속도에 많은 차이가 있습니다.
각 항목에 대한 설명
- type - ref : 인덱스로 자료를 검색하는 것으로 현재는 매칭(=) 자료 검색을 나타냄
- possible_keys : 현재 조건에 사용가능한 INDEX를 나타냄(인덱스가 N개일 수 있음)
IX_MBR_BAS_02 : 현재 조건에 사용 가능한 INDEX - key : Query 수행시 사용될 INDEX (possible_keys 가 N 개일 경우 USE INDEX, FORCE INDEX, IGNORE INDEX 로 원하는 INDEX 로 바꾸어 수행할수 있음)
- key_len : 수행되는 INDEX 컬럼의 최대 BYTE 수를 나타냄
- 152 : 수행되는 INDEX 컬럼의 BYTE 수가 152
- ref : INDEX 컬럼과 비교되는 상수 여부 or JOIN 시 선행 컬럼
constant : 상수 조건으로 INDEX 수행 - rows : 678 : 678 rows 접근하여 값을 찾음
- Extra : using index condition : INDEX 조건에 대하여 스토리지 엔진이 처리(MySQL의 구성에서 스토리지 엔진과 MySQL 엔진이 통신을 주고 받는데 스토리지 엔진에서 처리 하여 속도가 향상됨)
Conclusion
INDEX가 없으면 결과가 나오기까지 5초 정도 걸리지만, 반대로 INDEX가 있으면 1초 안에 결과가 나옵니다. 별거 아닌 것 같아 보이지만 실무에서는 엄청난 차이입니다. Query를 작성할 때 실행 계획을 확인하고 조금이라도 빨리 결과가 나올 수 있도록 하는 것이 중요하기 때문이죠. 다음 글에서는 단일 TABLE 을 SELECT하는 것을 주제로 이야기를 나눠보겠습니다. 무사히 SELECT하길 바라며.
한석종 팀장 | 데이터A팀
hansj@brandi.co.kr



