순서대로 척척, ORDER BY
ORDER BY 조건 처리 알아보기
한석종 팀장
2018-06-01
ORDER BY 는 원하는 순서대로 자료를 출력하고 싶을 때 사용합니다. 편의를 위해 이전 글의 예제에서 MBR_NM 의 INDEX 인 IX_MBR_BAS_02 를 제거하고 진행하겠습니다. 이번 글에서는 이해-적용-출력-활용의 순서로 살펴볼게요.
이해: ORDER BY의 오름차순과 내림차순
SELECT
MBR_NM
FROM test.TB_MBR_BAS
ORDER BY
MBR_NM
;
기본적인 ORDER BY는 위와 같이 사용합니다. 오름차순과 내림차순으로도 정렬할 수 있습니다. 오름차순일 때는 컬럼 뒤에 옵션을 넣지 않거나 ASC를 사용하고, 반대로 내림차순일 때는 DESC를 사용하면 됩니다.
[오름차순]
ORDER BY
MBR_NM
ORDER BY
MBR_NM ASC
[내림차순]
ORDER BY
MBR_NM DESC
위의 Query(오름차순) 의 실행계획을 보면 아래와 같이 표시됩니다.

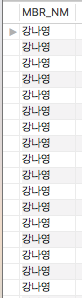
결과는 다음과 같습니다. (수행시간 3초)
내림차순 Query의 실행 계획을 보면 아래와 같이 표시됩니다.

결과는 다음과 같습니다. (수행시간 3초)
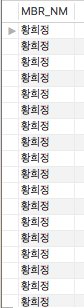
오름차순과 내림차순 정렬 Query를 보면 실행계획은 같고 결과는 다르게 나타납니다.
실행계획을 보면 이렇게 표시됩니다.
- table : TB_MBR_BAS
- type : ALL
- Extra : using filesort
Extra의 using filesort는 DBMS에서 정렬을 한다는 의미로 퀵소트 알고리즘을 사용합니다. 실행계획의 내용을 풀어보면 “TB_MBR_BAS 을 전부(ALL) 읽은 후 정렬한다(using filesort)” 정도로 보면 됩니다.
적용: INDEX와 정렬의 관계
이번에는 삭제했던 MBR_NM의 INDEX인 IX_MBR_BAS_02를 다시 생성하고 수행해보겠습니다.
CREATE INDEX IX_MBR_BAS_02 ON test.TB_MBR_BAS (MBR_NM);
SELECT
MBR_NM
FROM test.TB_MBR_BAS
ORDER BY
MBR_NM
;
INDEX를 생성하고 실행계획을 보면 아래와 같이 표시됩니다.

실행계획을 보면 몇 가지 달라진 게 눈에 띕니다.
1. type : ALL -> index
2. key : 없음 -> IX_MBR_BAS_02
3. Extra : using filesort -> Using index <br> 특히 Extra는 using filesort에서 Using index 로 바뀐 것을 알 수 있습니다. using filesort가 정렬을 한다는 것인데, 정렬을 하지 않고 어떻게 정렬해서 보여준다는 것일까요?<br><br>
INDEX를 이해하면 바로 알 수 있습니다. 일반적인 INDEX는 기본이 BTree INDEX 입니다. MySQL의 BTree INDEX는 오름차순 정렬 상태로 저장되어 있습니다. 이미 정렬한 상태로 저장되어 있는 INDEX를 사용하기 때문에 Query를 수행할 때 다시 정렬할 필요가 없죠. 그래서 using filesort가 나타나지 않는 겁니다.
출력: Query 실행
다음으로 성이 김 씨인 사람들의 이름을 순서대로 출력해보겠습니다. 여기서는 두 가지 Query를 이용해 비교해보겠습니다.
예시 1)
SELECT
MBR_NM
FROM test.TB_MBR_BAS
WHERE MBR_NM LIKE '김%'
ORDER BY
MBR_NM
;
예시 2)
SELECT
MBR_NM
FROM test.TB_MBR_BAS
WHERE SUBSTR(MBR_NM,1,1) = '김'
ORDER BY
MBR_NM
;
예시를 보면 WHERE 절이 다릅니다. 예시1은 “MBR_NM이 ‘김’으로 시작하는 것을 오름차순 정렬해 보여주라는 것”이고, 예시2는 “MBR_NM의 첫 번째 글자가 ‘김’인 것을 오름차순 정렬해 보여주라는 것”입니다.
이제 두 개의 Query 실행계획을 비교해보겠습니다.
예시 1)

예시 2)

여기서 주의 깊게 봐야 할 컬럼은 type입니다. 다른 컬럼들은 TB_MBR_BAS의 테이블을 조회하면서 IX_MBR_BAS_02 INDEX만을 사용해 보여주겠다는 내용을 갖고 있습니다. IX_MBR_MAS_02 INDEX가 MBR_NM으로 정렬되어 있기 때문에 using filesort가 나타나지 않은 것입니다. 그렇다면 type에 range와 index는 어떤 차이가 있는 것일까요?
range : where 조건에 조회하는 범위가 지정된 경우 나타납니다.
예시1은 TB_MBR_BAS를 조회하는데 IX_MBR_BAS_02 INDEX의 MBR_NM에서 ‘김’이 시작되는 위치부터 끝나는 위치까지 조회해 보여주라는 의미입니다. IX_MBR_BAS_02 INDEX를 이용해 ‘김’이 시작되는 위치로 바로 접근할 수 있는 것이 핵심입니다.
index : index를 처음부터 끝까지 읽는다는 의미입니다.
예시2는 TB_MBR_BAS를 조회하는데 IX_MBR_BAS_02 INDEX를 순서대로 읽어서 MBR_NM의 첫 글자가 ‘김’인 것을 보여주라는 의미입니다.
두 개의 차이점을 꼽자면, range는 원하는 범위로 바로 접근해 값을 가져올 수 있는 것이고, index는 처음부터 끝까지 읽어서 그 값이 조건에 맞을 경우 가져오라는 것입니다. 따라서 예시1이 휠씬 성능이 뛰어난 Query라고 볼 수 있습니다. 결과는 모두 아래와 같이 출력됩니다.
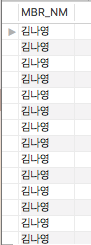
수행시간은 차이를 보였습니다. 예시1은 0.0041초, 예시2는 0.5초였는데요. 예시에서는 건수가 적기 때문에 큰 차이가 없는 것처럼 보이지만, 자료가 10배 또는 100배 많아진다고 생각해보세요. 엄청난 차이겠죠.
활용: Query를 만들고 DISTINCT !
마지막으로 Query 하나를 만들어보겠습니다.
1) MBR_NM의 중복을 제거하고
2) 김 씨이면서
3) 이름이 ‘혜’로 시작하는 사람을 먼저 출력하고
4) 이외의 사람은 그 다음부터 오름차순으로 출력하려면 어떻게 만들어야 할까요?
중복을 제거할 때는 일반적으로 DISTINCT 와 GROUP BY 두 가지를 사용합니다. 이번 글에서는 DISTINCT를 사용하겠습니다. 다음으로는 오름차순 정렬할 때 김 씨를 먼저 출력하는 것인데 조건문을 사용하여 김 씨인 것과 아닌 것을 구별해 우선순위를 주겠습니다. 다른 것은 위의 Query를 이행하면 됩니다. 먼저 DISTINCT를 넣고 수행해 보겠습니다.
SELECT
DISTINCT
MBR_NM
FROM test.TB_MBR_BAS
ORDER BY
MBR_NM
;
실행계획은 다음과 같습니다.

DISTINCT를 수행하면 Extra가 나타나며 group by로 표시됩니다. 여기서는 IX_MBR_BAS_02를 이용하여 gorup by(중복제거)하여 보여준다는 의미입니다. 수행하면 다음과 같은 값이 나옵니다.
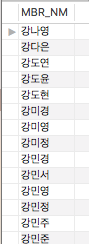
다음으로는 MBR_NM이 ‘김혜’로 시작하는 것을 먼저 보여주기 위해 ORDER BY 절에 CASE WHEN문을 사용하겠습니다.
SELECT
DISTINCT
MBR_NM
FROM test.TB_MBR_BAS
ORDER BY
CASE
WHEN MBR_NM LIKE '김혜%' THEN 0
ELSE 1
END
,MBR_NM
;
실행계획은 다음과 같습니다.

ORDER BY에 조건이 들어가면서 INDEX의 순서대로 정렬한 것을 그대로 보여줄 수 없기 때문에 Extra에 Using temporary, Using filesort가 나타납니다. Using temporary는 가상 테이블을 만들어 사용하는 것인데, 다시 말해 가상 테이블을 만들어 다시 정렬하는 것입니다. 이에 대한 출력값은 다음과 같습니다.
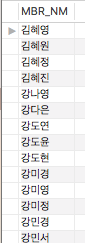
‘김혜’로 시작하는 사람이 먼저 나왔군요.
글을 마치며
지금까지 ORDER BY와 연관된 조건 처리를 알아봤습니다. 데이터를 더욱 체계적으로 나타내고 싶으신가요? ORDER BY를 이용해서 원하는 목적을 달성해보세요.
한석종 팀장 | 데이터A팀
hansj@brandi.co.kr



