주니어 개발자가 외칩니다, "Hello, System Architecture!"
시스템 아키텍쳐 A to Z
오연주
2018-08-03
Overview
주니어 개발자는 시스템 아키텍처(System Architecture) 또는 시스템 디자인(System Design)이라는 단어에 덜컥 겁부터 먹습니다. 지금 진행하고 있는 개발에만 집중하다 보니 큰 그림을 놓치고 있는 게 아닐까 란 생각이 들었죠. 조금 더 큰 그림을 보고자 공부를 시작했습니다. 문득 같은 생각을 하는 주니어 개발자 분들도 많을 것 같다고 생각했어요.
그래서 이번 글은 시스템 아키텍처에 ㅇ_ㅇ? 뀨? 하는 표정을 짓는 주니어 개발자들을 위해 썼습니다.
상상의 나래: 가상의 패션 e커머스
상상의 나래를 펼쳐봅시다. 패션 e커머스 서비스를 이용하는 김유저 씨가 구매한 옷이 마음에 들어 상품 리뷰를 남기고 싶어한다고요.

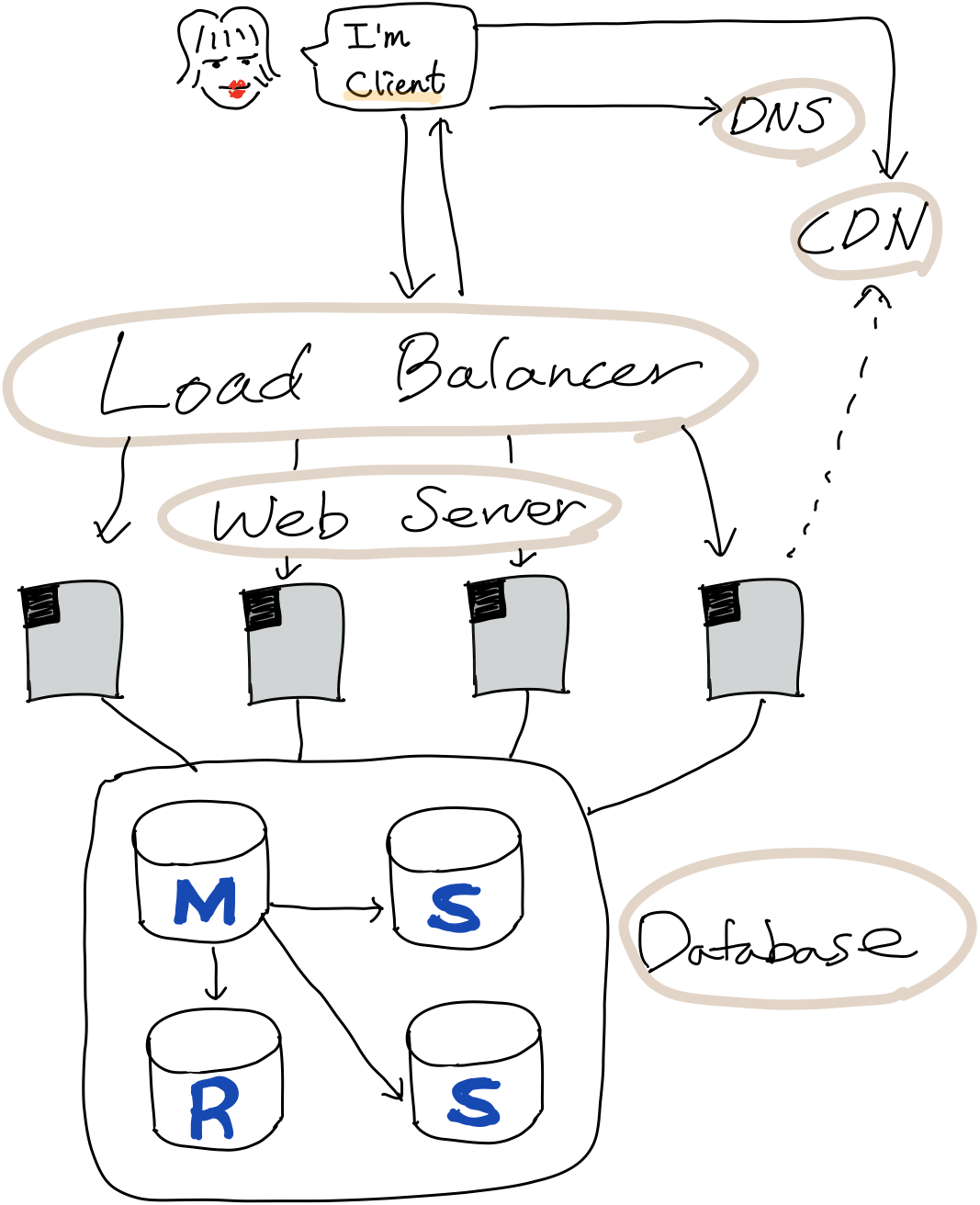
김유저 씨는 본인의 착용 사진과 텍스트 리뷰를 작성하고 ‘리뷰 등록하기’ 버튼에 엔터를 탁! 누를 겁니다. 그런데 말이죠. 김유저 씨는 요청하고 싶은 웹서버의 IP 주소를 모르기 때문에 요청을 보낼 수가 없습니다.
내 정체를 알려줘: DNS (Domain Name System)

그래서, DNS(Domain Name System)에게 물어봅니다. 서버의 도메인 이름으로부터 해당 서버의 IP 주소를 알려주는 것이 바로 DNS입니다. 도메인 이름에 대한 질의를 하고, 만일 해당 도메인 이름이 DNS에 ‘A Record’ 형태로 등록이 되어 있다면 도메인 이름에 해당하는 IP 주소를 응답으로 돌려줍니다.
서비스에서 자체 DNS 시스템을 가지고 있을 수 있습니다. 예를 들어 Route 53, Cloud Flare같은 서비스가 있습니다. 그렇다면 또 한 가지 의문이 생깁니다. 왜 서비스는 시스템적 부담을 안고서 자체 DNS 서버를 구축하고 있는 걸까요? 그 이유로 두 가지를 꼽을 수 있습니다.
첫 번째로는 신뢰도가 높습니다. 직접 DNS Record를 관리 및 운영하기 때문입니다. 두 번째로는 보안이 우수합니다. 만약 공개하고 싶지 않은 IP 주소, 예를 들어 Database IP 주소 같은 건 공개하지 않습니다. 1)
작업장소: Web Server
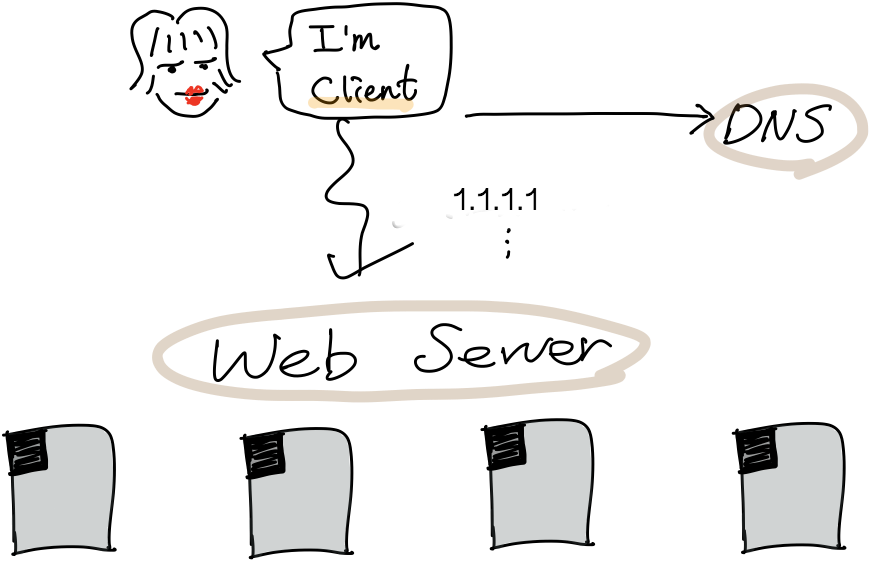
이제 웹서버의 IP 주소를 알았으니 통신을 시도합니다. 웹서버는 웹서비스에서 필요로 하는 다양한 요청과 그에 대한 응답을 제공합니다. 클라이언트가 리뷰에 대한 사진과 텍스트를 등록하고 싶다면 웹서버에게 등록하라는 요청을 보내야 합니다.
웹서버에서 요청을 받으면 사용자가 요구한 대로 사진과 텍스트를 등록하고, 그에 대한 결과 정보를 응답으로 보내줄 것입니다. 웹서버 내부에서는 그 과정에 필요한 연산을 수행합니다. 서버 개발자는 이 연산에 대한 코드를 작성하고요.
센스가 없는 서버:API (Application Programing Interface)
서버는 사람이 아닙니다. 센스나 재치가 없죠. 미리 정의되지 않은 요청은 대응하지 못합니다. (어버버버버 퉤! Error 404!) 그래서 약속한 요청을 보내면 약속한 방식으로 응답해줄게라고 명세를 제공합니다.
약속한 요청으로 데이터를 보내면 원하는 요청에서 데이터를 정제해 잘 처리했는지, 또는 처리된 데이터를 약속한 방식(예를 들어, JSON 방식)으로 내보내죠. 웹서버는 정의된 API에 맞춰 요청과 응답을 합니다.
그런데 웹서버가 수많은 요청을 받고 응답하면 과부하가 일어날 수도 있습니다. 사용자 수가 어마어마한 규모로 늘어나서 서버가 펑! 하고 터진다면, 김유저 씨는 서비스를 더 이상 이용할 수 없을 겁니다. 이용하고 싶지도 않을 겁니다!
따라서, 서버가 감당하는 요청을 나누기 위해 같은 역할을 하는 서버 장비 수를 늘릴 수도 있습니다. 그러면 요청이 각기 다른 웹서버 장비에 분산되어 한 번에 감당할 수 있는 요청 수가 더욱 많아집니다.
이 구역의 매니저는 나야: Load Balancer
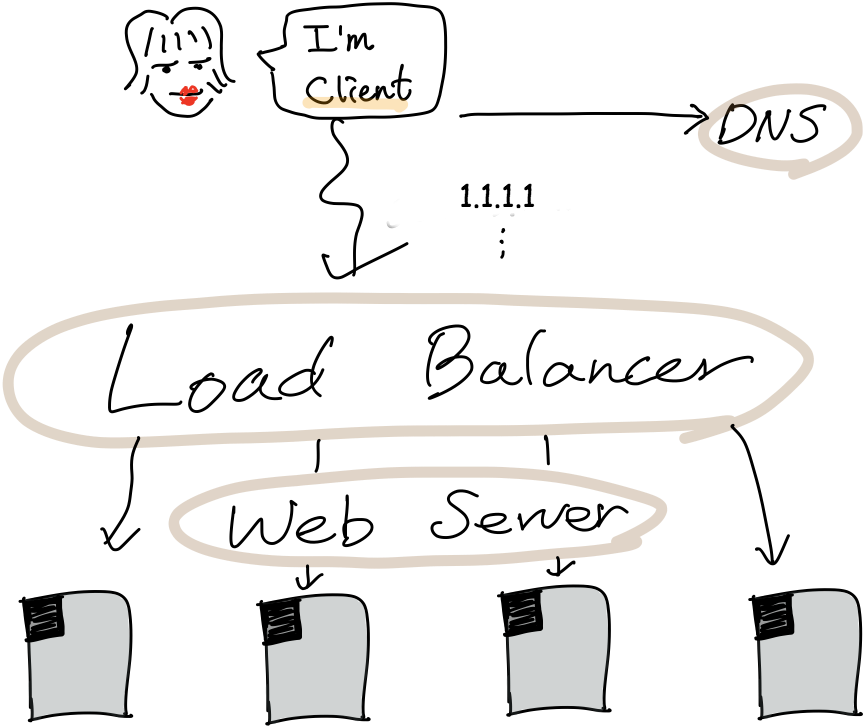
그림처럼 서버가 4대 존재하는 상황이라면, 서버 4대에 일을 적절히 분배해주는 역할이 필요합니다. 그것이 로드 밸런서(Load Balancer)입니다. 로드 밸런서가 서버에게 일을 나누는 방법론은 여러 가지가 있습니다.
- Random: 랜덤으로 분배하기
- Least loaded: 가장 적은 양의 작업을 처리하고 있는 서버에게 요청을 할당하기
- Round Robin: 순서를 정하여 돌아가며 작업 분배하기
많이 쓰는 로드 밸런서의 종류는 Layer 4, Layer 7을 꼽을 수 있습니다.
- Layer 4 Load Balancer: 데이터의 내용을 보지 않고 IP주소 및 TCP/UDP 정보에 따라 단순히 분배를 해줍니다.
- Layer 7 Load Balancer: 서버가 하는 역할이 분리되어 있는 환경에서 데이터의 내용을 보고 각기 맞는 역할을 하는 서버에게 분배를 해줍니다.
로드 밸런서는 클라이언트가 요청을 보내야 할 서버를 골라야 하는 부담을 덜어주며, 로드 밸런서에게 할당된 vIP (가상 IP)로 요청을 보내기만 하면 로드 밸런서에서 알아서 작업을 나눠줍니다. 서버에서는 적절한 로드 밸런서를 사용하면 들어오는 요청이 여러 장비에 분산되어 처리량이 늘어나고 응답 시간이 줄어드는 효과를 기대할 수 있습니다.
컨텐츠 저장소: CDN(Content Delivery Network)
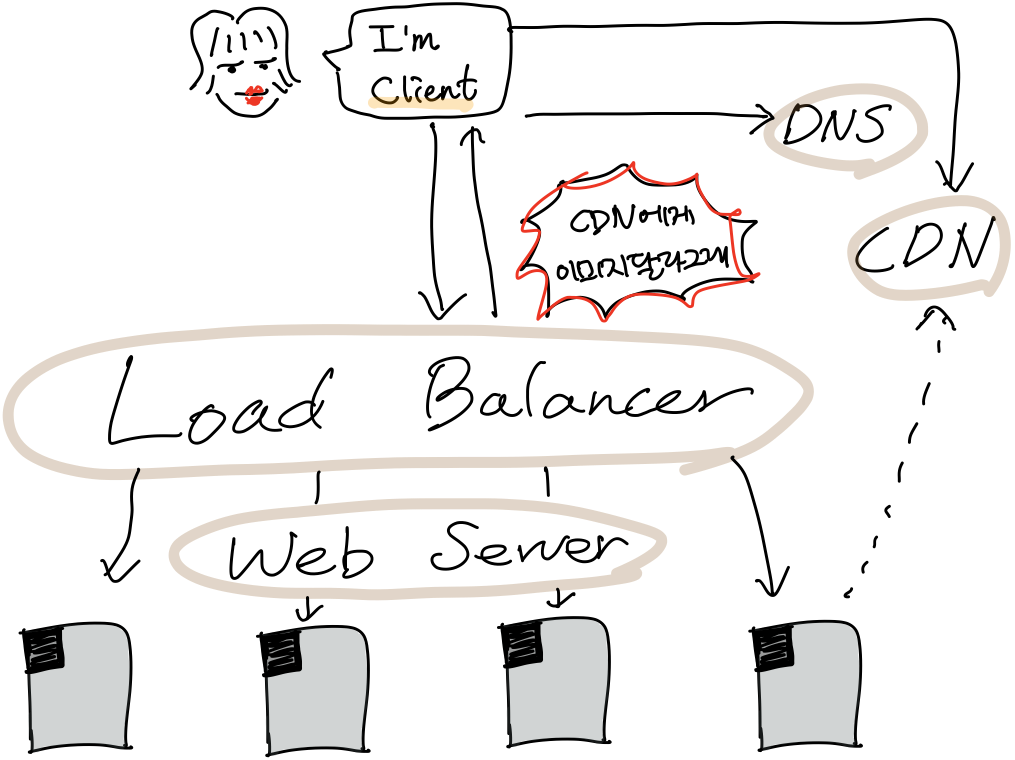
이제 웹서버가 클라이언트의 요청에 의해 웹페이지에 대한 응답 결과를 돌려줬습니다. 이때 클라이언트의 화면에 렌더링해야 하는 수많은 이미지가 필요합니다. 이 이미지들을 웹서버가 전부 주려면 데이터의 용량이 너무 크고, 무거워서 서버가 헥헥거리죠. (서버가 죽으면 어떻게 될까요? 클라이언트님이 경쟁사로 환승하겠죠.. 안 돼요..) 따라서 웹서버는 직접 이미지를 주는 대신 CDN(Content Delivery Network)에게 요청하라고 이야기합니다.
CDN은 일반적으로 용량이 큰 컨텐츠 데이터(이미지, 비디오, 자바스크립트 라이브러리 등)를 빠른 속도로 제공하기 위해 사용자와 가까운 곳에 분산되어 있는 데이터 저장 서버입니다. 클라이언트는 용량이 큰 컨텐츠 데이터를 가까운 CDN에 요청해 멀리 있는 웹서버에서 직접 받는 것보다 빠르게 받을 수 있습니다.
CDN이 동작하는 방식에는 크게 Push CDN, Pull CDN이 있습니다.
- Push CDN: 서버에서 컨텐츠가 업로드되거나, 변경되었을 때 모두 반영하는 방식
- Pull CDN: 클라이언트가 요청할 때마다 컨텐츠가 CDN에 새로 저장되는 방식
두 방식 모두 장단점이 있습니다. Push CDN은 모든 컨텐츠를 갖고 있기에 웹서버에 요청할 일이 없지만 유지하는데 필요한 용량과 비용이 많이 필요하겠죠? Pull CDN은 클라이언트가 요청한 컨텐츠가 있으면 바로 응답하지만 그렇지 않을 땐 데이터를 웹서버로부터 가져와야 하기 때문에 서버에 요청하는 부담이 존재합니다. 컨텐츠명은 그대로인데 내용만 변경되었다면 인지하지 못하고 옛버전의 컨텐츠를 제공하죠.
그래서 Pull CDN에 들어가는 컨텐츠는 TTL(Time To Live)이 적용됩니다. TTL이란 유통기한이라고 생각하면 쉽습니다. 일정시간이 지나면 해당 데이터가 삭제되는 것이죠. 이런 방식이 적용된다면 Pull CDN의 최대 단점을 보완할 수 있습니다. 이렇게 보완이 되면 수정된 데이터에 대해서도 대응이 가능하며 서버의 용량 즉, 비용적 부담이 해소될 겁니다.
소중한 내 데이터: Database
서비스를 제공하다 보면 클라이언트의 소중한 정보, 이력, 상품 가격, 상품 정보 등 다양한 데이터를 저장하고, 또 제공합니다. 하지만 수많은 데이터를 웹서버에 전부 저장하고 사용하기엔 데이터의 양이 너무 많아 저장 공간도 부족하고, 데이터를 원하는 모양에 맞게 정제하기가 어렵습니다. 그래서 데이터를 저장하는 데이터베이스 서버가 따로 존재합니다.
민감한 정보를 다루는 데이터베이스는 ACID라는 성질을 만족해야 하는데요.
- Atomicity(원자성): 데이터베이스에 적용되는 명령이 중간만 실행되지 않고 완전히 성공하거나 완전히 실패해야 한다는 것을 의미합니다. 반만 적용된 명령이 있다면 헷갈리겠죠.
- Consistency(일관성): 데이터베이스가 수행한 명령이 일관적으로 반영되어 있어야 한다는 의미입니다. 예를 들어 계좌에 돈을 입금했는데 잔고에 반영되지 않는다면 당황스러울 겁니다.
- Isolation(고립성): 데이터베이스가 수행하는 명령 도중 다른 명령이 끼어들지 못한다는 것을 의미합니다.
- Durability(지속성): 성공적으로 수행한 명령은 영원히 그 이후 상태로 남아있어야 한다는 걸 의미합니다. 갑자기 하루 뒤에 명령이 취소되거나 이전 상태로 롤백되면 안 됩니다.
Replication (복제 / 이중화)
큰 시스템에서는 똑같은 데이터베이스가 여럿 존재한다고 하는데요. 그렇다면 왜 비용적인 부담을 안으면서까지 복제 데이터베이스를 구축해놓는 걸까요? 만약에 데이터베이스가 정상적으로 동작하지 않는다면 클라이언트의 데이터를 변경하지 못하며, 클라이언트가 원하는 정보를 제공하지 못하는 불상사가 일어나게 됩니다. 글로만 써도 벌써 땀이 납니다. 그러므로 복제해놓은 데이터베이스를 얼른 마스터로 등업해 데이터 흐름에 차질이 없도록 대비해야 합니다.
만약 하나의 데이터베이스가 어떤 일을 수행할 때 다른 요청들은 계속 기다려야 합니다. 그렇다면 데이터를 변경하는 데이터베이스는 하나, 읽기만 하는 데이터베이스는 여러 대가 존재해도 되지 않을까요? 바로 여기서 Master-Slave의 개념이 탄생합니다.
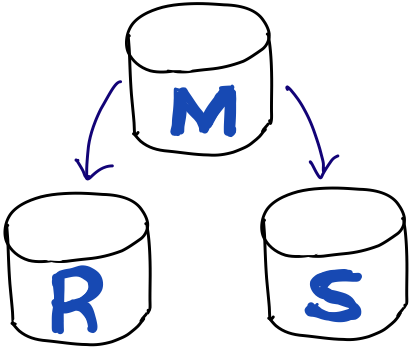
Master-Slave Replica (a.k.a 주인-노예)
요청을 분산하기 위해서 데이터베이스를 늘리다 보면 master-slave 토픽이 등장합니다.
- Mater: CRUD(Create, Read, Update, Delete)가 모두 가능
- Slave: R(Read)만 가능
Master가 데이터를 변경할 동안 읽기에 대한 요청은 Slave에게 보내집니다. 그렇게 하면 읽기 요청은 분산되어 훨씬 더 수월하고 빠른 속도로 데이터 처리가 가능할 것입니다. 만약 Master가 변경된다면 아래 계급인 Slave, Replica 데이터베이스에게도 이 정보를 전해야 합니다. 다시 말해, 자신에게 들어온 요청(Query)을 동일하게 보내 빠른 시간 안에 동기화를 시켜주죠. 하지만 동기화도 시간이 걸리는 작업이므로 무한대로 Slave Replica를 늘려 확장하기는 어렵습니다.
Master-Master Replica
의문이 하나 생길 겁니다.
“여러 대의 Master를 두어서 변경도 가능하고, 읽기도 가능하게 하면 되지 않을까?”
앞서 언급했듯이 같은 데이터의 변경 가능한 데이터베이스는 하나여야 할 것입니다. 동시에 같은 데이터를 변경했을 때 갈등을 해소하기 위한 방법론은 존재하지만, 그 방식이 복잡하고 오래 걸립니다. 안정성도 낮아지고, 효율도 떨어집니다. 그래서 Master-Slave 아키텍처를 선호하는 것이죠.
Sharding
그러면 같은 데이터베이스 테이블을 동시에 변경하는 건 불가능한 걸까요? 그것을 해소하기 위해 샤딩(Sharding)이라는 방법론을 사용합니다. 샤딩된 테이블은 개념적으론 하나의 테이블처럼 보이지만 사실 그 내용물이 쪼개져 있습니다. 쪼개는 방법은 여러 가지 선택할 수 있습니다만, 분명한 건 겹치는 데이터 없이 쪼갠다는 것입니다. 그래서 같은 테이블이어도 쪼개져 있다면 그 테이블에 동시에 접근해 데이터를 변경할 수 있는 것이죠.
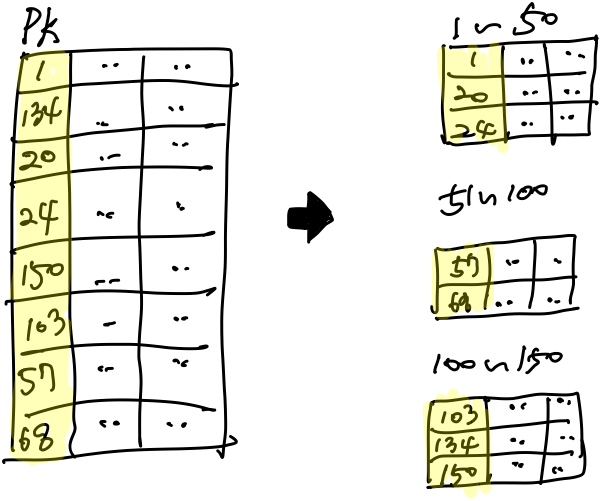
이외에 서비스별, 기능별로 쪼개어 데이터베이스를 관리하는 Federation 등 많은 데이터베이스 디자인 방법론이 존재합니다.
요점: 시스템 아키텍쳐에서 고려해야 할 성질
이렇게 간단한 시스템 아키텍처의 면면을 살펴봤습니다. 시스템 개발자라면 시스템을 디자인하면서 반드시 고려해야 할 성질들을 만날 텐데요. 위에서 소개한 내용들 역시 아래의 성질들을 충족하기 위해 탄생했다고 볼 수 있습니다.
- Scalability (확장성): 10만 명의 요청을 처리할 수 있는 시스템과 1000만 명의 요청을 처리할 수 있는 시스템은 다릅니다. 확장성을 고려한 시스템은 앞으로 클라이언트 수가 늘어났을 때 무리 없이 모든 요청을 처리할 수 있을 겁니다.
- Performance (성능): 속도와 정확성을 말합니다. 요청한 내용을 정확하고 빠르게 돌려주어야 합니다.
- Latency (응답 시간): 모든 요청은 클라이언트가 불편해하지 않을 정도로 빠른 시간 안에 돌려주어야 합니다.
- Throughput (처리량): 같은 시간 안에 더욱 많은 요청을 처리한다면 좋은 시스템입니다.
- Availability (접근성): 사용자가 언제든지 시스템에 요청을 보내서 응답을 받을 수 있어야 합니다. 비록 서버 장비 한두 대가 문제가 생겨 제 기능을 하지 못하더라도 사용자는 그 사실을 몰라야 합니다.
- Consistency (일관성): 사용자가 서버에 보낸 요청이 올바르게 반영되어야 하고, 일정한 결과를 돌려주어야 합니다. 요청을 보낼 때마다 불규칙한 결과를 돌려준다면 믿을 수 없는 서비스가 될 것입니다.
결론
발로 그렸나 싶을 정도의 그림과 기나긴 글을 마무리 지으며
주니어 개발자로서 시스템 아키텍처를 공부하면서 느낀 점이 있다면 시스템에 대한 완벽한 대응은 없으며, 모두 장단점이 존재한다는 것입니다. (이것을 보통 trade-off라고 표현합니다.)
하지만 설계하는 서비스를 잘 알고 서비스에서 무게를 둬야 할 부분을 파악한다면, 그에 맞는 시스템을 설계하고 디자인할 수 있을 겁니다. 김유저 씨도 만족시킬 수 있을 거고요. 꼬박 이틀을 밤새워서 쓴 글이 아직 시스템 아키텍처를 두려워하는 다른 주니어 개발자분들에게 도움이 되었으면 합니다.
이번에는 시스템에서 아주 기초적인 부분을 공부했으니 다음 글에선 MSA(MicroService Architecture)를 씹어봅시다! 겁이 나고 무서워도 외쳐보세요.
“Hello, System Architecture!”
이 세상 모든 주니어 개발자분들, 퐈잇팅입니다.
참고
1) 추가적인 이점에 대하여: 웹서버에서 요청을 보낼 때 database 도메인 네임으로 보낼 경우, 멀리 있는 공인 DNS 서버 (예를 들면 google public DNS server: 8.8.8.8)에 물어오는 것보다 자체 DNS 서버에 물어오는 것이 훨씬 더 빠른 속도로 응답을 받아올 수 있습니다.
오연주 | 데브옵스팀
ohyj@brandi.co.kr



