AWS CloudWatch를 이용한 로그 모니터링 시스템 구축
AWS CloudWatch를 이용해 로그 모니터링 구축해보기
장현준 팀장
2019-10-02
Overview
안녕하세요, 개발3팀입니다!!
현재 우리 R&D본부는 다수의 서비스를 운영하고 있습니다.
그중에 저희 개발3팀도 여러개의 서비스를 운영을 하고 있습니다. 다수의 서비스를 운영 하다보면 수없이 많은 일들이 펼쳐집니다.
우리는 각각의 상황들을 분석하고 적절히 대응 해야할 필요가 있죠.
이러한 일들을 수행하는데에 있어 로그 모니터링 시스템이 큰 도움이 됩니다.
이제까지 우리는 기존의 로그 모니터링 방식에 불편함을 느끼고 있었습니다.
다수의 분리된 서비스들의 로그를 한 곳에서 보고도 싶었고, 각종 로그들을 한 눈에 보기 편하게 볼 수 있기를 원하였습니다. 그래서 우리는 우리의 입맛에 맞는 새로운 시스템을 구성하기로 했습니다.
아직은 프로젝트 초기인지라 많은 보완이 필요한 단계이지만, 지금까지의 개발 과정들을 공유하고자 합니다 :D
요구사항
이 프로젝트의 초기 요구사항은 이러했습니다.
- 이 로그 시스템의 도입으로 인해 서비스의 소스 구조가 많은 영향을 받는 것을 원치 않았습니다.
- 현재 사용중인 기술들(AWS, Python, Vue.js 등) 과의 궁합이 잘 맞아야 했습니다.
- 당연하게도 우리가 원하는 정보들이 적절한 시각적 형태로 표현되어야 했습니다.
이외의 세부적인 요건들은 프로젝트를 진행하며 추가해 나가기로 했습니다.
먼저, 이미 개발되어있는 모니터링 툴들을 찾아보았고 그 중 참고할만한 서비스를 발견했습니다.

Log Reporting, Error Tracking 기능을 제공하는 서비스입니다. 다수의 유명한 기업들이 사용중입니다.
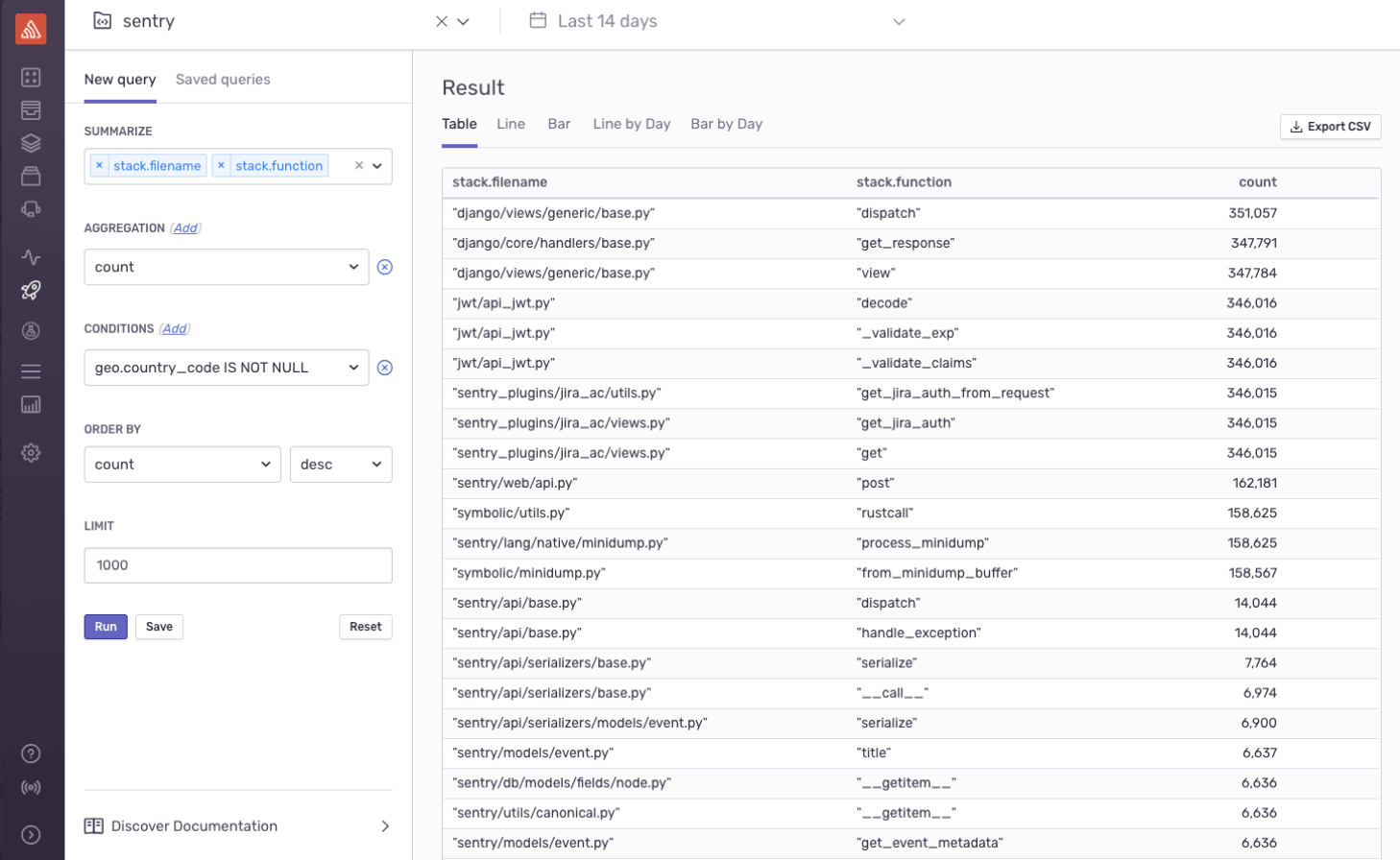
출처: sentry 공식 홈페이지
로그 검색기능이 꽤나 강력합니다. 검색 쿼리 작성이 가능하네요.
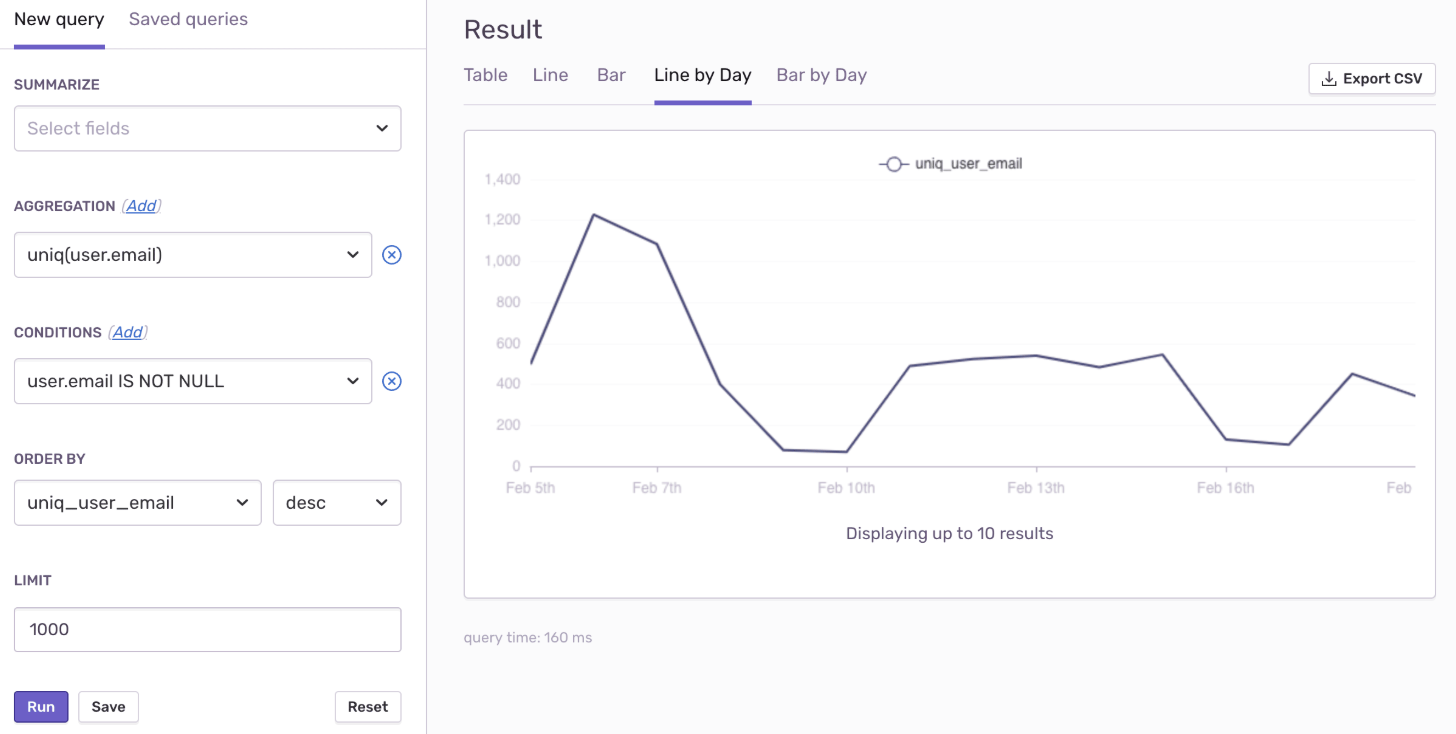
출처: sentry 공식 홈페이지
결과물을 다양한 형태의 그래프로 볼 수 있다는 점도 눈에 띕니다. CSV 파일로 추출도 가능합니다.
이처럼 기존의 모니터링 서비스를 도입하시는 것도 좋은 선택지입니다. 비용이나 그 외 여러가지 측면들을 잘 고려 해보시기 바랍니다. sentry에 대한 자세한 정보는 공식 홈페이지를 참고하시면 됩니다.
세부 요구사항 정의
이러한 기능들 중 가장 우선시되어 필수로 제공해야할 기능들을 추려본 결과, 몇 가지 세부 요구사항들을 정의할 수 있었습니다.
- 프로젝트, 운영환경별로 검색이 가능해야 했습니다.
- 여러가지 필터 기능들 중 우선 날짜, 로그레벨별 검색 기능만 제공하기로 했습니다.
- 그래프, 푸시 알림 등의 기능은 추후 요건으로 남겨두고 일단 로그 정보들을 단순 텍스트로 보여주기로 했습니다.
- 추가로, 서비스의 부하를 줄이기 위해 로그 수집은 로그 건별이 아닌 유저 요청 건별 또는 페이지 이동마다 이루어지도록 구현하기로 했습니다.
그리고 수집되어야 할 정보들을 정의했습니다.
- 서비스 관련 정보 : 서비스명, 운영환경
- 로그 관련 정보 : 레벨, 타입, 코드
- HTTP 통신 관련 정보 : HTTP 메소드, 상태 코드
- 이벤트 발생 관련 정보 : 발생 시각, URL, 위치
- 기타 : 사용자 정보, 메시지, Stack Trace, 기타 정보
기술 검토
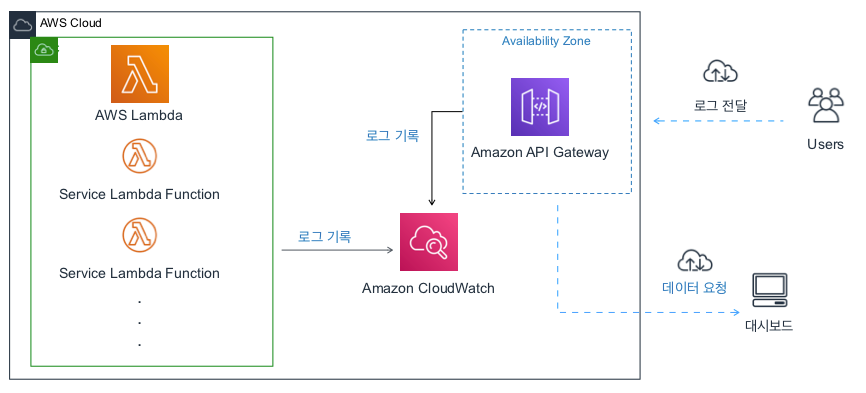
이제 요구사항이 어느정도 정리되었으니 구현 기술을 검토할 차례입니다. 여러가지 선택지를 고려한 결과 기존 서비스에서 AWS를 사용하고 있어, AWS CloudWatch를 사용하면 궁합이 잘 맞겠다는 결론이 나왔습니다.
여러 서비스에서 수집된 로그 정보를 CloudWatch에 담고, 이 정보들을 웹 대시보드 형태로 제공하기로 했습니다.
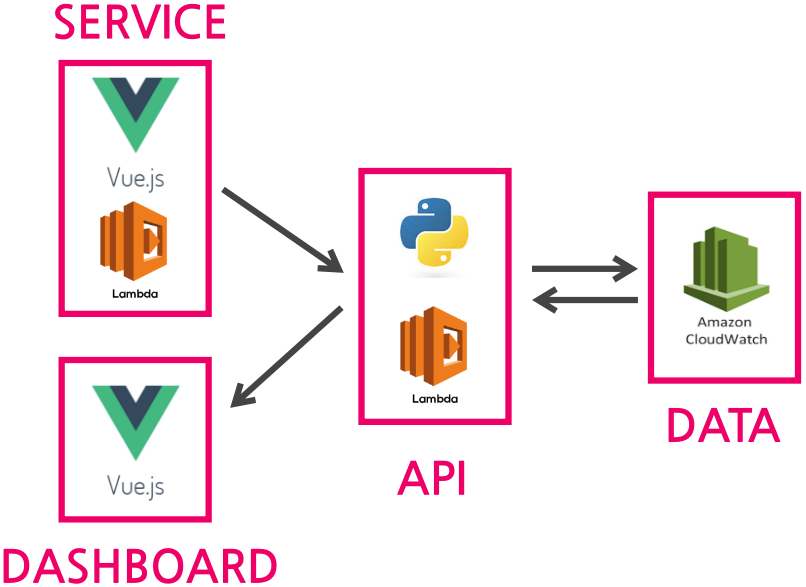
CodeStar로 생성된 Lambda API 프로젝트들은 CloudWatch 연동이 이미 되어 있으니 로그 수집에는 문제가 없었고, 웹 프론트에서 발생하는 로그 정보들을 CloudWatch에 저장하는 역할과 저장된 정보들을 대시보드로 전송해줄 역할을 담당할 API 서버는 AWS Lambda 기반의 Python으로 구현하기로 했습니다.
마지막으로 웹 대시보드 구현은 가장 익숙한 기술인 Vue.js를 채택했습니다.
구현
AWS CloudWatch
AWS CloudWatch는 로그 그룹과 로그 스트림이라는 개념으로 로그 정보를 관리합니다. 한 로그 그룹 내에 여러개의 로그 스트림이 저장되는 방식으로 운영되며, 로그 보존 정책과 접근 정책을 로그 그룹별로 설정이 가능합니다.
CodeStar로 생성한 Lambda API 프로젝트들은 자동으로 설정되는 그룹/스트림 관리 정책을 그대로 따라가기로 하였습니다. 웹 프론트 프로젝트의 경우 로그 그룹은 프로젝트/운영환경별로, 로그 스트림은 발생시각에 따라 시간별로 생성해 관리하기로 결정했습니다.
API

API는 Python용 AWS SDK인 boto3를 이용해 어렵지 않게 구현할 수 있었습니다. 로그 그룹과 스트림, 로그 정보들을 다루는 다양한 기능을 제공하고 있습니다. 구현에 대한 자세한 내용은 다루지 않겠습니다. boto3 공식 문서를 참고하시면 됩니다.
Vue.js
다음은 Vue.js 서비스에서 API로 로그 정보를 전송하는 부분입니다. 우리는 세가지 유형의 로그 수집을 구현했습니다.
- window.onerror
- Vue ErrorHandler
- 기타 사용자 정의 로그
1, 2번의 경우, 핸들러가 반환한 인자들에서 발생 위치와 Stack Trace 정보를 알아낼 수 있었지만 3번의 경우 Vue 객체에서 직접 컴포넌트 명을 가져올 필요가 있었습니다.
let that = this
let _getComponentName = (component) => {
let ary = component.$vnode.tag.split('-')
return ary[ary.length - 1]
}
let _getComponentTraceStack = () => {
let traceStack = []
let currentComponent = that
for (;;) {
let componentName = _getComponentName(currentComponent)
if (componentName === 'App') { break }
traceStack.push(componentName)
currentComponent = currentComponent.$parent
}
return traceStack
}
console.log(_getComponentName(this)) // 현재 컴포넌트
console.log(_getComponentTraceStack()) // 컴포넌트 계층
성능을 고려해, 이렇게 수집한 정보들은 전역 객체에 배열형태로 담아두었다가 beforeunload 윈도우 이벤트 발생시 한번에 전송하도록 구현했습니다. (beforeunload 이벤트에는 비동기식 요청이 동작하지 않습니다. 동기식으로 구현하시기 바랍니다)
Dashboard
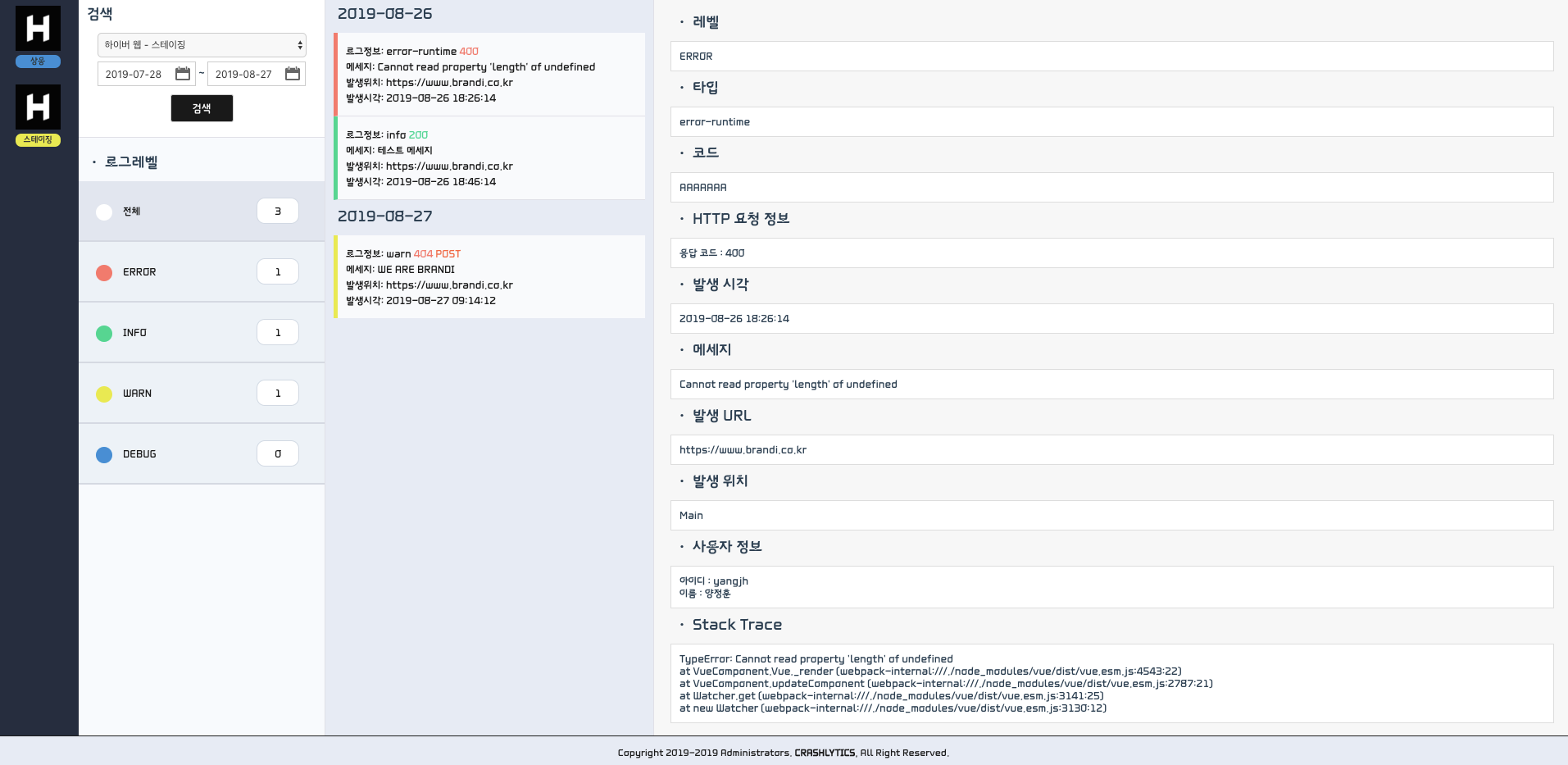
마지막으로 웹 대시보드입니다. 핵심적인 기능만 우선적으로 진행해 구현했습니다.

레이아웃 구성입니다. 이후의 추가 개발로 필터가 더 생겨난다면, 상단 GNB 영역을 만들어 프로젝트/운영환경과 같은 몇가지 필터를 이동시키는 것도 고려하고 있습니다. Sentry의 경우 프로젝트와 날짜 필터가 상단에 위치하고 있네요.
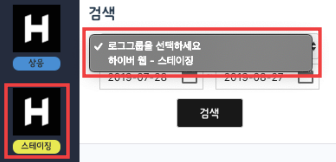
우선 좌측의 프로젝트/운영환경을 선택해 해당 프로젝트의 로그그룹 리스트를 API에서 불러옵니다. 위와 같은 웹 프론트 프로젝트가 아닌 람다 API 프로젝트의 경우 로그그룹이 핸들러별로 하나씩 생성되도록 되어 있습니다.
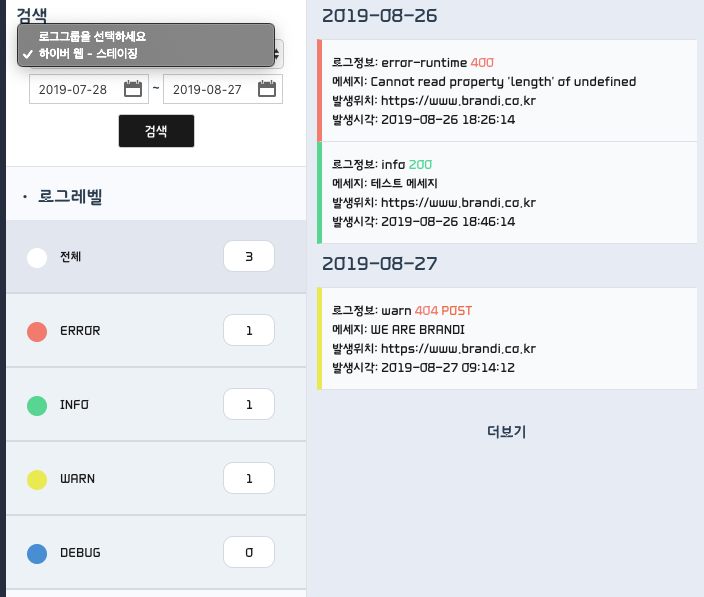
검색할 로그 그룹(하이버 웹 - 스테이징) 과 날짜를 선택해 로그 리스트를 검색합니다. 검색 후 로그레벨별 필터링이 가능합니다.

그리고 조회하고싶은 로그를 선택하면 우측에 상세 정보가 표시됩니다. 테스트 데이터라 유용한 정보가 많지는 않네요. 수집할 항목들도 더 고민이 필요할 것 같습니다.
추가 개발 요건
드디어 기본적인 기능을 제공하는 로그 대시보드가 완성되었네요! 작업을 진행하다보니 몇가지 좋은 아이디어가 떠올랐습니다. 이것들은 이후에 발전시켜나가는 식으로 진행하기로 했습니다.
- 민감한 정보들이 그대로 노출되는 곳이니, 검색엔진에서 수집되지 않도록 처리되어야 할 것 같습니다. 이 작업은 우선적으로 진행되어야겠네요.
- beforeunload 이벤트에 동기식으로 로그 전송 API를 호출하다보니 페이지이동이 느려지는 이슈가 발견되었습니다. 개선이 필요한 부분입니다.
- 어디까지 정보를 수집할 것인가, 어떤 정보를 담을 것인가의 문제는 지속적으로 고민하며 발전시켜 나가야겠습니다. 실제 운영을 통한 경험적인 부분이 녹아들어야 할 이슈입니다.
- 슬랙이나 메일 연동을 통한 푸시 알림 시스템은 이후 필수적으로 구현되어야 할 내용입니다.
- 그래프나 카드 형식으로 홈 화면을 구성하는 것도 좋아 보입니다. 첫 화면에서 서비스들의 개략적인 상태를 볼 수 있다면 좋겠죠. AWS CloudWatch 대시보드나 위에서 말씀드린 Sentry에서 좋은 아이디어를 얻을 수 있을 것 같네요.
- 모니터링 시스템 자체에서 에러가 발생할 경우 어떻게 확인할 것인가에 대한 부분도 고민해봐야 할 문제입니다.
Conclusion
서비스를 운영하며 발생하는 데이터를 어떻게 수집하고 관리, 분석하는가가 점점 더 중요한 이슈가 되어가고 있습니다. 그러한 정보들 하나하나가 서비스 품질을 향상시켜주는 아주 귀중한 자원이죠. 안정적이고 강력한 로그 모니터링 시스템은 쏟아져 나오는 정보들 가운데서 모래밭 속 진주를 찾아내는, 좋은 도구가 되어주지 않을까 싶습니다.
장현준 팀장 | 풀필먼트 개발팀
janghj@brandi.co.kr



