추천 시스템 맛보기 - AWS SageMaker를 중심으로
죽는 줄 알았습니다.
김우경
2020-01-28
목차
1. INTRO
2. CHAPTER 1
1. The Recommendation Problem
2. 명시적 점수(Explicit Rating)
3. 암묵적 피드백(Implicit Feedback)
4. 브랜디 서비스 속 명시적 점수와 암묵적 피드백
3. CHAPTER 2
1. 예제 실습
4. CONCLUSION
INTRO
지난 10월, 브랜디 랩스에 ‘개발 1팀의 AWS Personalize 도전기’ 를 게재하면서 하나의 미션을 받았습니다. 바로 AWS SageMaker(이하 SageMaker)를 이용해 추천 알고리즘을 다뤄보는 것이었는데요. 데이터베이스를 모르면 AWS RDS를 사용하기 어렵듯이, 머신러닝에 대해 모르는 상태에서는 SageMaker를 다루기가 매우 어려웠습니다.
이번 시간에는 AWS Machine Learning Blog에 올라와 있는 포스트 예제를 통해 SageMaker로 추천 알고리즘을 훈련, 배포를 한 경험을 공유하고자 합니다. CHAPTER 1 에서는 머신러닝의 기본적인 개념을 간단히 정리하고, CHAPTER 2 에는 예제 실습을 해보도록 하겠습니다. 머신러닝에 대해 기본 지식이 있으신 독자분은 CHAPTER 2 로 바로 넘어가시면 됩니다.
(참고. CHAPTER2 에서는 예제에 대한 간단한 설명으로 진행되며 코드 전체에 대한 설명은 진행되지 않습니다.)
CHAPTER 1.
The Recommendation Problem
추천시스템은 사용자가 항목에 대해 평가한 과거 선호도(ex. 리뷰, 찜)를 기반으로 아직 사용하지 않은 항목에 대해 사용자의 평가를 예측하는 문제입니다. 사용자 u 가 항목 i 를 얼마나 좋아할 것인지 나타내는 값을 등급 Rui 라고 했을 때 등급 값은 평점 데이터처럼 1에서 5사이의 실수형 등급 값일 수도 있고, 클릭 여부를 나타내는 이진 등급 값일 수도 있습니다. 이 때 평점 데이터는 명시적 점수(Explicit Rating), 클릭 여부 데이터는 암묵적 피드백(Implicit Feedback)이라고 합니다.
성능이 좋은 추천시스템을 구현하기 위해서는 해결하고자 하는 문제를 제대로 이해해야 하고, 명시적 점수 및 암묵적 피드백에 대한 선택을 해야 합니다.
명시적 점수(Explicit Rating)
후기 평점과 같이 이미 만들어진 점수 범위 안에서 사용자가 직접적으로 점수척도에 관여하는 것입니다. 추천 시스템에 대한 초기 연구들이 명시적 점수에 기반하여 많이 진행되었습니다. 그러나 명시적 점수는 객관적으로 척도를 판단하기 어려운 변수를 가지고 있습니다.
예를 들어 마음에 드는 옷을 구매했다고 판단했을 때 대부분의 사용자는 별4개 또는 5개의 후한 점수를 부여합니다. 그러나 그저 그런 옷이라고 판단되었을 경우 별1개도 아까워서 아예 점수를 매기지 않을 수도 있습니다. 즉, 상품에 대한 구매 데이터 대비 평가 데이터는 매우 희박합니다. 이것을 머신러닝에서 희소 데이터 또는 희소하다(Sparse) 라고 표현합니다.
암묵적 피드백(Implicit Feedback)
구매여부/조회여부처럼 명시적으로 표현할 수 없는 데이터들을 의미합니다. 명시적 점수에 비해 선호도를 제대로 표현할 수 없다는 단점이 있지만, 이는 암묵적 점수를 어떻게 해석하느냐에 따라 어느 정도 극복이 가능합니다.
예를 들어 특정 상품을 찜 했으면 1, 아니면 0 으로 구분하는 것이 아니라 추천했으나 찜 하지 않았다면 -1, 추천되지 않았다면 0, 찜을 했다면 1 그리고 구매까지 했다면 2점을 부여하는 식으로 레이팅을 달리하는 것입니다. 암묵적 피드백은 명시적 점수 대비 데이터 수집이 쉬우며 이를 밀집 데이터 또는 밀집하다(Dense) 라고 표현합니다.
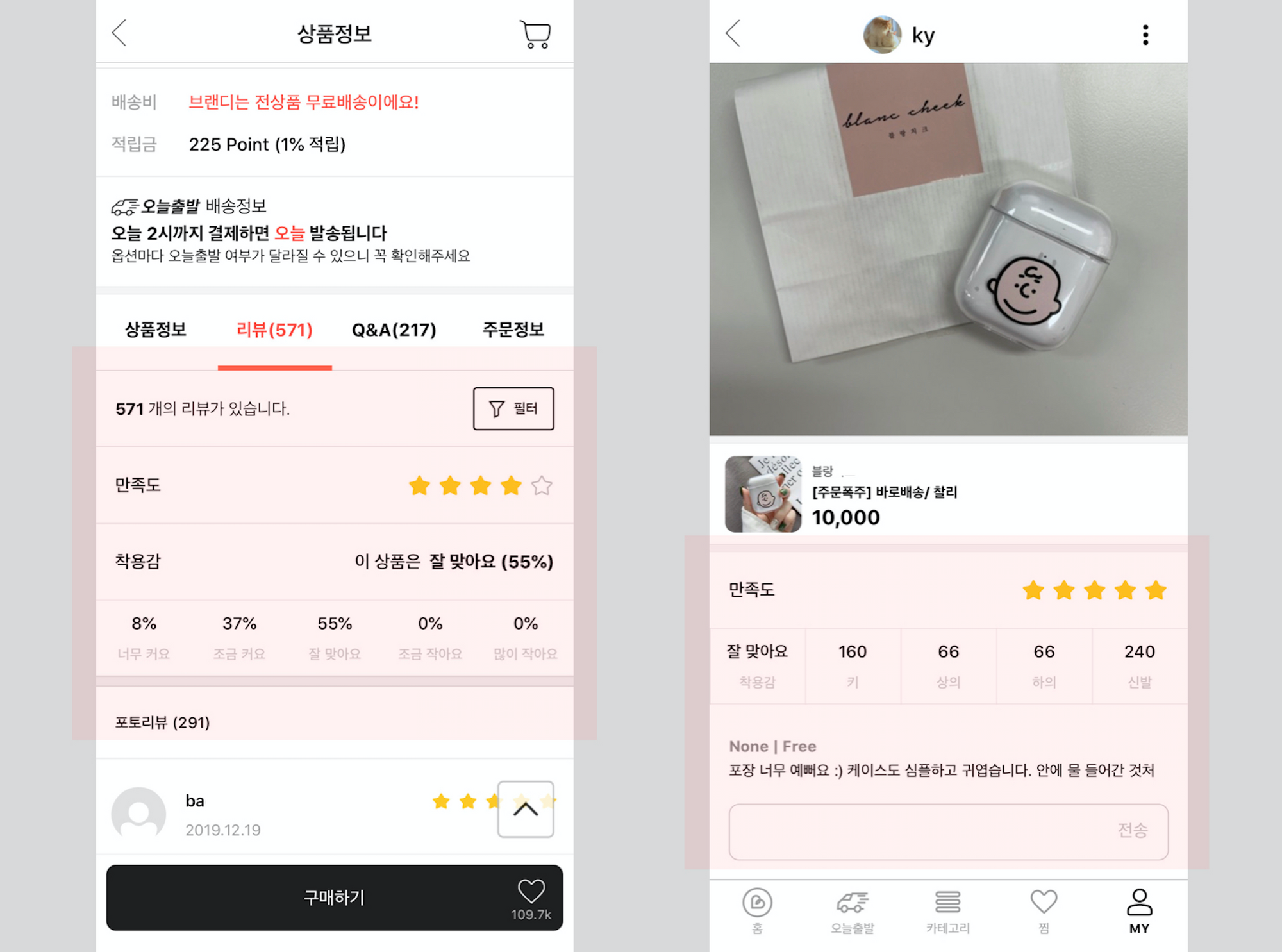
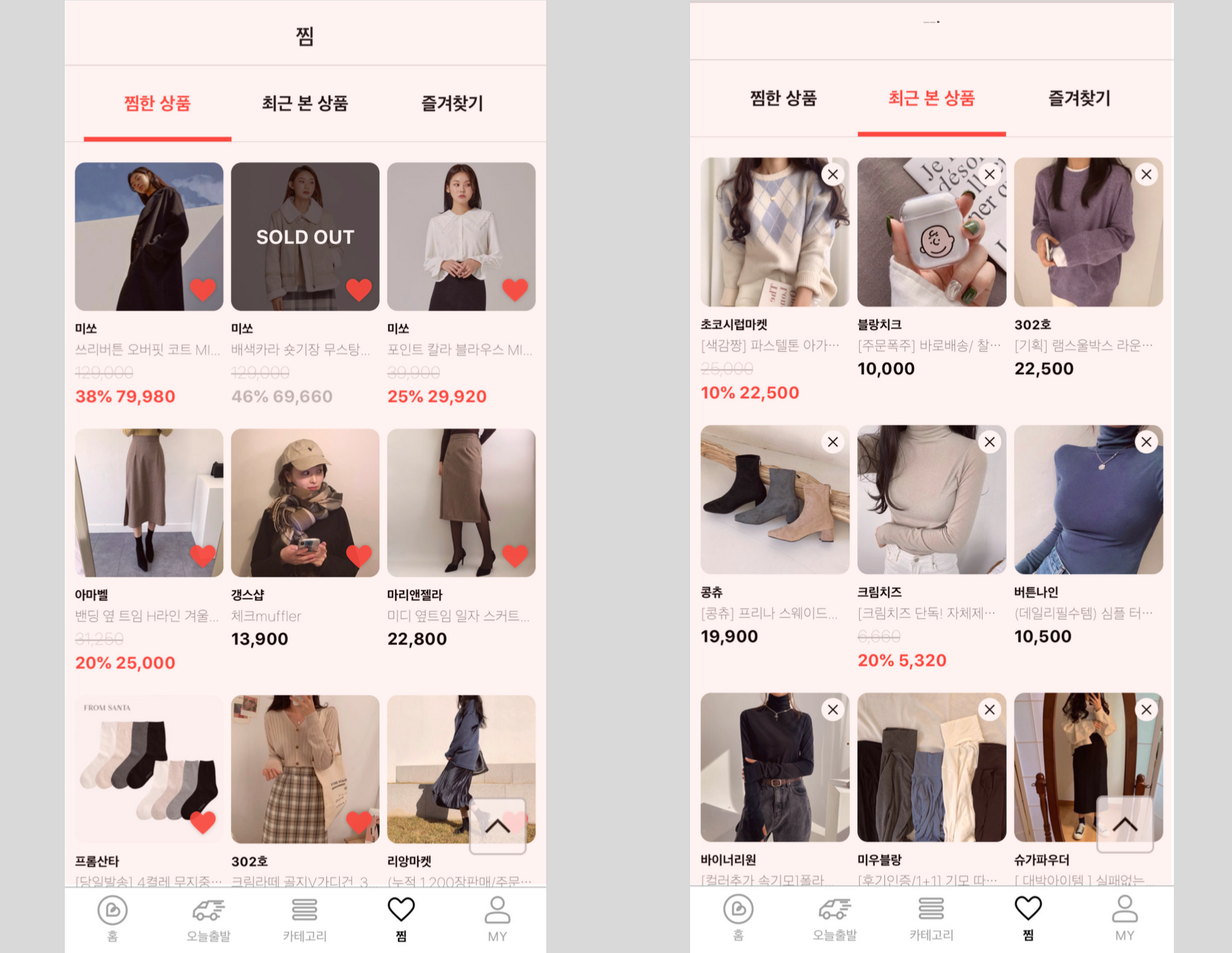
브랜디 서비스 속 명시적 점수와 암묵적 피드백 🧐
CHAPTER 2.
이번 시간에 다룰 예제는 Movielens 의 영화 평점 데이터 세트를 이용하여 FM 알고리즘으로 트레이닝 후 KNN 알고리즘에 맞게 변환하여 상위 N개의 영화를 추천해주는 내용입니다. 앞서 말했듯 평점 데이터는 명시적 점수이기 때문에 Matrix Factorization 알고리즘보다 Sparse Data에 적합한 FM 알고리즘을 사용하는 것이 좋습니다.
그럼 실전으로 바로 들어가볼까요? 🏃♀️
2-1. 먼저 필요한 모듈들을 import 합니다.
import sagemaker
import sagemaker.amazon.common as smac
import numpy as np
import pandas as pd
import boto3
import io
import os
from sagemaker import get_execution_role
from sagemaker.predictor import json_deserializer
from sagemaker.amazon.amazon_estimator import get_image_uri
from scipy.sparse import lil_matrix
2-2. Movielens 의 영화 평점 데이터 세트를 다운로드한 후 데이터 셔플 [1] 을 진행합니다.
# 데이터 세트 다운로드
!wget http://files.grouplens.org/datasets/movielens/ml-100k.zip
!unzip -o ml-100k.zip
# 데이터 셔플
!shuf ml-100k/ua.base -o ml-100k/ua.base.shuffled
[1] 트레이닝 결과가 ‘심한 불균형’을 보이지 않도록 처리하는 과정입니다. 예를 들어 영화에 대해 로맨스 카테고리 → 공포 카테고리 → 추리 카테고리 순서로 학습을 시키면, 맨 처음 학습된 로맨스 카테고리에 대해서만 최적 값을 배우게 되어 그 뒤로는 효율이 없는 학습을 진행하게 됩니다. 바로 이런 현상을 막기 위해 데이터를 무작위로 섞는 것입니다.
2-3. 트레이닝 데이터를 불러옵니다.
# 트레이닝 데이터를 Pandas DataFrame 에 담습니다.
user_movie_ratings_train = pd.read_csv(
'ua.base.shuffled',
sep='\t',
index_col=False,
names=['user_id' , 'movie_id' , 'rating'],
)
# 상위 5건 데이터를 출력시킵니다.
user_movie_ratings_train.head(5)
2-4. 테스트 데이터를 불러옵니다.
# 테스트 데이터를 Pandas DataFrame 에 담습니다.
user_movie_ratings_test = pd.read_csv(
'ua.test',
sep='\t',
index_col=False,
names=['user_id' , 'movie_id' , 'rating'],
)
# 상위 5건 데이터를 출력시킵니다.
user_movie_ratings_test.head(5)
2-5. FM 트레이닝 모델 [2] 을 준비합니다.
[2] 현재 AWS SageMaker에서 FM Algorithm 입력에 대해서는 Float32 텐서가 포함된 recordIO-protobuf 형식만 지원하고 있습니다. 왠지 어려워보이지만 Amazon SageMaker SDK 에서 변환기능을 제공해주기 때문에 전혀 걱정할 필요가 없습니다.
우리는 FM 모델로 One-hot encoded된 희소행렬(Sparse Matrix)을 만들 것이며, 4점 이상의 데이터만 고려할 것입니다.
결과적으로는 4점 이상만 1이고 나머지는 0인 희소행렬이 만들어 집니다.
def loadDataset(dataframe, lines, columns):
# (lines, columns) 모양의 빈 희소 행렬을 만들고 float32 타입으로 변환합니다.
X = lil_matrix((lines, columns)).astype('float32')
# 레이블의 여기에 저장됩니다.
Y = []
line=0
for index, row in dataframe.iterrows():
X[line,row['user_id']-1] = 1
X[line, nb_users+(row['product_id']-1)] = 1
# 4점 이상의 데이터만 고려합니다.
if int(row['rating']) >= 4:
Y.append(1)
else:
Y.append(0)
line=line+1
Y=np.array(Y).astype('float32')
return X,Y
nb_users = train_set['user_id'].max()
nb_products = train_set['product_id'].max()
nb_features = nb_users + nb_products
nb_ratings_test = len(user_product_ratings_test.index)
nb_ratings_train = len(user_product_ratings_train.index)
print ('# of users: ', nb_users)
print ('# of products: ', nb_products)
print ('Features (# of users + # of movies): ', nb_features)
print ('\nLoadDataset...')
X_train, Y_train = loadDataset(user_product_ratings_train, nb_ratings_train, nb_features)
X_test, Y_test = loadDataset(user_product_ratings_test, nb_ratings_test, nb_features)
print ('Success')
assert X_train.shape == (nb_ratings_train, nb_features)
assert Y_train.shape == (nb_ratings_train, )
zero_labels = np.count_nonzero(Y_train)
print("Training labels: %d zeros, %d ones" % (zero_labels, nb_ratings_train-zero_labels))
assert X_test.shape == (nb_ratings_test, nb_features)
assert Y_test.shape == (nb_ratings_test, )
zero_labels = np.count_nonzero(Y_test)
print("Test labels: %d zeros, %d ones" % (zero_labels, nb_ratings_test-zero_labels))
위 코드를 차례로 실행한 후의 결과를 보시면 zero_labels가 월등히 많은 것을 확인할 수 있습니다.
Training labels: 3461 zeros, 538 ones
Test labels: 869 zeros, 133 ones
2-6. Protobuf 타입 [3] 으로 변환하여 S3로 업로드합니다.
[3] 앞서 말했듯, SageMaker에 내장된 FM 알고리즘은 protobuf 형식의 데이터만 입력받을 수 있습니다. 우리는 SageMaker SDK에서 제공하는 메소드를 가지고 protobuf로 변환, S3로 업로드할 것입니다.
def writeDatasetToProtobuf(X, bucket, prefix, key, d_type, Y=None):
buf = io.BytesIO()
if d_type == 'sparse':
smac.write_spmatrix_to_sparse_tensor(buf, X, labels=Y)
else:
smac.write_numpy_to_dense_tensor(buf, X, labels=Y)
buf.seek(0)
obj = '{}/{}'.format(prefix, key)
boto3.resource('s3').Bucket(bucket).Object(obj).upload_fileobj(buf)
return 's3://{}/{}'.format(bucket,obj)
# 업로드 할 경로를 지정합니다.
prefix = 'labs-fm'
train_key = 'train.protobuf'
train_prefix = '{}/{}'.format(prefix, 'train')
test_key = 'test.protobuf'
test_prefix = '{}/{}'.format(prefix, 'test')
output_prefix = 's3://{}/{}/output'.format(bucket, prefix)
fm_train_data_path = writeDatasetToProtobuf(X_train, bucket, train_prefix, train_key, 'sparse', Y_train)
fm_test_data_path = writeDatasetToProtobuf(X_test, bucket, test_prefix, test_key, 'sparse', Y_test)
print ('Training data S3 path: ',fm_train_data_path)
print ('Test data S3 path: ',fm_test_data_path)
print ('FM model output S3 path: {}'.format(output_prefix))
위 코드를 차례로 실행한 후 출력된 S3경로에 접근하면 아래와 같은 protobuf 파일이 생성된 것을 확인할 수 있습니다.

2-7. 준비된 모델을 트레이닝합니다.
# 트레이닝에 사용할 수 있는 인스턴스 타입은 정해져 있으며, 그 외 타입을 지정할 경우 ValidationException 가 발생합니다.
# 인스턴스 타입이 너무 작을 경우에는 OutOfMemoryError 가 발생하므로 준비된 모델의 크기를 고려하여 지정합니다.
instance_type='ml.m5.large'
fm = sagemaker.estimator.Estimator(
get_image_uri(boto3.Session().region_name, 'factorization-machines'),
get_execution_role(),
train_instance_count=1,
train_instance_type=instance_type,
output_path=output_prefix,
sagemaker_session=sagemaker.Session(),
)
# 필수로 적용해주어야 하는 하이퍼파라미터를 지정합니다.
fm.set_hyperparameters(
feature_dim=nb_features,
predictor_type='binary_classifier',
num_factors=64,
)
# 훈련을 시작합니다!
fm.fit(
{
'train': fm_train_data_path,
'test': fm_test_data_path
}
)
2-8. 이제 KNN 알고리즘에 맞춰 모델을 리패키징합니다.
# 모듈이 없을 경우에는 pip install 과정을 추가합니다.
import mxnet as mx
model_file_name = 'model.tar.gz'
model_full_path = fm.output_path +'/'+ fm.latest_training_job.job_name +'/output/'+model_file_name
print 'Model Path: ', model_full_path
# S3 버킷으로부터 FM 모델을 다운로드 합니다.
os.system('aws s3 cp '+model_full_path+ ' .')
# 모델을 추출하여 MXNet 으로 불러옵니다.
os.system('tar xzvf '+model_file_name)
os.system('unzip -o model_algo-1')
os.system('mv symbol.json model-symbol.json')
os.system('mv params model-0000.params')
m = mx.module.Module.load('./model', 0, False, label_names=['out_label'])
V = m._arg_params['v'].asnumpy()
w = m._arg_params['w1_weight'].asnumpy()
b = m._arg_params['w0_weight'].asnumpy()
# 아이템 잠재 매트릭스를 생성합니다.
knn_item_matrix = np.concatenate((V[nb_users:], w[nb_users:]), axis=1)
knn_train_label = np.arange(1,nb_movies+1)
# 사용자 잠재 매트릭스를 생성합니다.
ones = np.ones(nb_users).reshape((nb_users, 1))
knn_user_matrix = np.concatenate((V[:nb_users], ones), axis=1)
2-9. KNN 모델을 준비,배포한 후 배치 변환을 통해 추론 결과를 확인합니다.

CONCLUSION
SageMaker는 내장형 Jupyter Notebook 인스턴스를 제공해주기 때문에 서버 관리를 할 필요없이 쉽게 데이터를 분석할 수 있습니다. 뿐만 아니라 AWS SDK를 통해 모델을 쉽게 변환, 학습, 배포할 수 있으며 예제에서는 다루지 않았지만 예측 결과는 데이터베이스에 저장하여 캐싱할 수도 있습니다.
개인적으로 본 글을 준비하면서 머신러닝에 대한 기본적인 지식과 알고리즘에 대한 이해를 충분히 하지 못한 아쉬움이 있습니다. Movielens의 예제 샘플 데이터가 아닌 브랜디의 상품 리뷰 데이터를 다뤄보고 싶었지만, 트레이닝 모델이 MXnet 모듈에서 읽혀지지 않거나 원-핫 인코딩 과정에서 에러가 발생하는 부분을 해결하지 못하였습니다. 모델을 훈련, 배포하는 과정 또한 시간과 큰 비용이 발생하기 때문에 원인을 찾아가는 과정은 쉽지 않았습니다.
하지만 이번 시간을 통해 머신러닝에 조금 가까워진 것 같아 뿌듯합니다!
저는 앞으로 시간을 들여 기본기를 좀 더 다진 후 재도전 해보겠습니다. 🤛 화이팅!
참고 (2019년 12월 기준)
- 호스팅 서비스에서 모델을 배포할 때 인스턴스 타입을 ‘ml.t2.medium’ 이 아닌 다른 타입으로 설정하는 경우 자원 초과 에러가 발생하였다. ‘ml.t2.medium’ 으로는 자원이 부족하여 배포를 진행할 수 없었으며, AWS Support 로 문의해야 하는 것으로 확인하였다.
ResourceLimitExceeded: An error occurred (ResourceLimitExceeded) when calling the CreateEndpoint operation: The account-level service limit 'ml.m5.2xlarge for endpoint usage' is 0 Instances, with current utilization of 0 Instances and a request delta of 1 Instances. Please contact AWS support to request an increase for this limit.
-
참고문헌
[2] https://docs.aws.amazon.com/ko_kr/sagemaker/latest/dg/whatis.html
[3] https://zzaebok.github.io/machine_learning/factorization_machines/
김우경 | 커머스 개발팀
kimwk@brandi.co.kr



