AWS Personalize 과거데이터 갱신 프로세스 자동화하기
곽정섭
2020-10-06
Overview
최근 e-commerce 시장은, 데이터 기반의 개인화 추천 서비스에 많은 관심을 갖고 적극적으로 도입하고 있습니다. 브랜디 서비스도 AWS Personalize 알고리즘을 활용한 실시간 개인화 추천 서비스를 제공하고 있습니다.
(이전 글 : 개발1팀의 AWS Personalize 도전기)
개인(고객)에게 맞는 상품을 추천하는 데 있어 데이터 수집은 무엇보다 중요합니다. 현재 AWS Personalize에서 제공하는 데이터 수집 방법은 2가지로 구성되어 있습니다.
- Datasets을 이용한 과거 데이터 수집
- Event trackers를 이용한 실시간 데이터 수집
Dataset 생성 이후에 등록된 신규 상품을 실시간으로 추천하기 위해서는 Event trackers 수집만으로는 추천 항목을 얻을 수 없습니다. Datasets Interactions 교육 데이터에 포함된 상품만 추천되기 때문에 주기적인 과거 데이터 갱신이 필요합니다.
본 글에서는 주기적으로 AWS Personalize 과거 데이터를 갱신하는 프로세스를 자동화하는 내용을 정리해 보겠습니다.
Step 1. 과거 데이터 갱신 프로세스 정리
- Dataset import job 생성
- Solution version 생성
- Campaign 업데이트
Step 2. 과거 데이터 갱신 프로세스 자동화
현재 브랜디에서는 일주일에 한번 AWS Glue 서비스를 이용하여 고객 행동 이력을 추출, 변환하여 S3에 업로드합니다.
- Dataset import job 생성
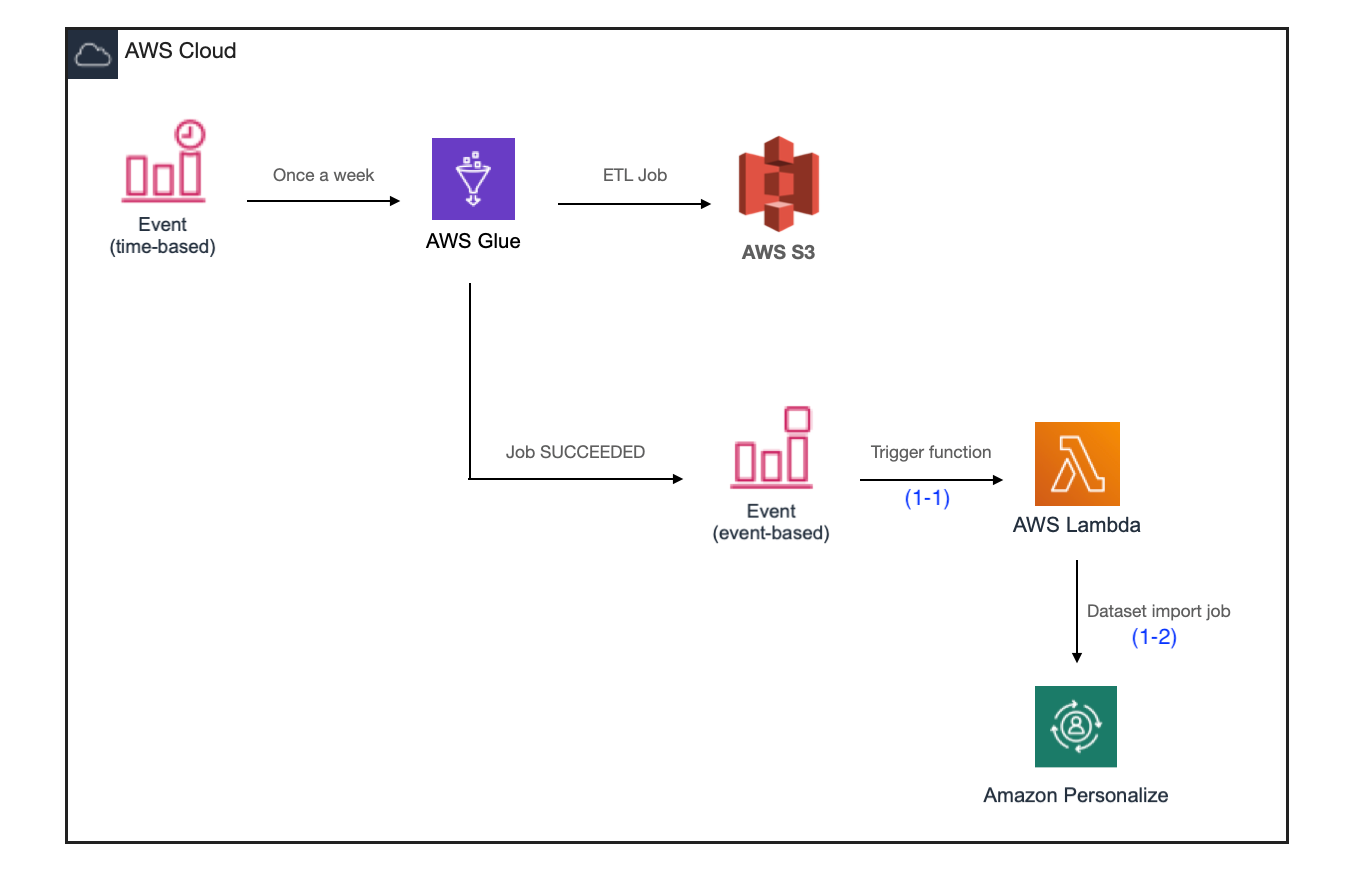
1-1. 행동 이력 데이터 업로드 완료 시점에 이벤트 발생시켜 과거 데이터 갱신 프로세스를 실행합니다.
{
"source": [
"aws.glue"
],
"detail-type": [
"Glue Job State Change"
],
"detail": {
"state": [
"SUCCEEDED"
],
"jobName": [
"Job-Brandi-Commerce-API"
]
}
}
1-2. Personalize SDK를 이용하여 Dataset import job을 생성합니다.
personalize_response = aws_client.create_dataset_import_job(
# Job Name에 실행날짜 추가하여 구분
jobName='Brandi Dataset Job Name' + base_date,
datasetArn='Brandi Dataset Arn',
dataSource={'dataLocation': 'Brandi Data Location'},
roleArn=constants.PERSONALIZE_DATASET_ROLE_ARN,
)
1-3. AWS Personalize 콘솔 확인
2. Solution version 생성 및 Campaign 업데이트
Dataset import job 생성 완료(ACTIVE)로 변경된 후에 Solution version 생성 및 Campaign 업데이트를 순차적으로 진행해야 합니다. AWS Personalize는 Dataset 생성 완료 시 트리거를 지원하지 않으므로 Personalize Dataset를 조회하여 이전 단계 생성 여부를 판단하고 다음 단계를 실행해 주어야 합니다.
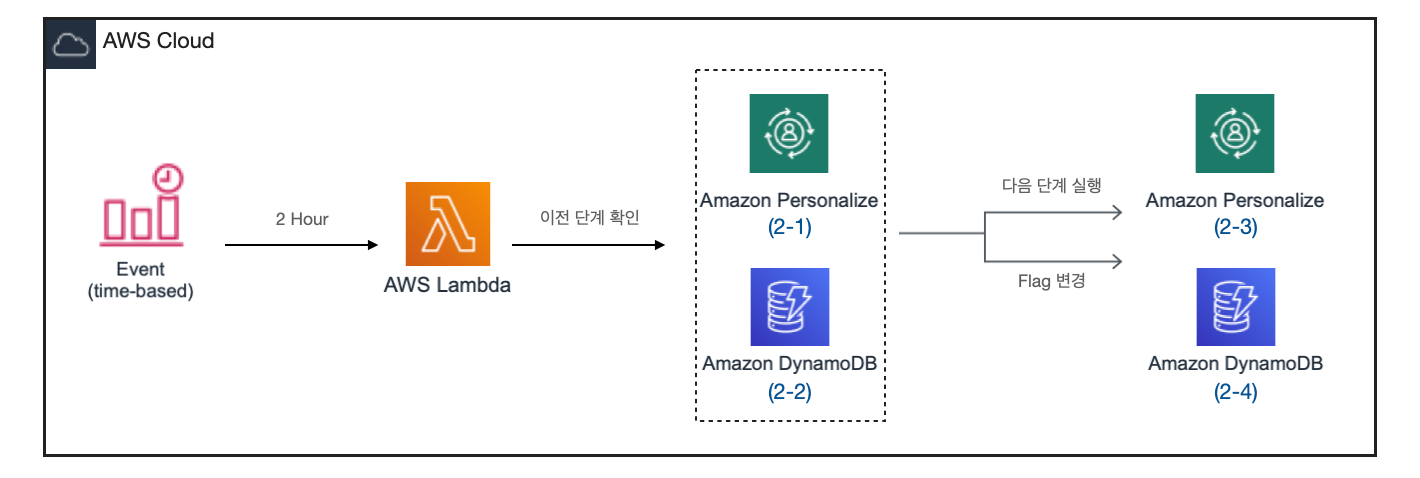
2-1. Personalize 과거 데이터 갱신 프로세스는 단계별로 전부 갱신되어야 업데이트 되기 때문에 각각 이전 단계 확인이 필요합니다.
# 퍼스널라이즈 데이터셋 생성 여부 확인
description = personalize_client.describe_dataset_import_job(
datasetImportJobArn='Dataset Import Job Arn'
)['datasetImportJob']
# 퍼스널라이즈 솔루션 버전 생성 여부 확인
description = personalize_client.describe_solution_version(
solutionVersionArn='Solution Version Arn'
)['solutionVersion']
2-2. DynamoDB를 이용하여 플래그로 Personalize 다음 단계 실행 여부를 확인합니다.
- Table Name : PROD_PERSONALIZE_DATA_PROCESS - Provisioned capacity - Read capacity units : 1 (Auto Scaling Disabled) - Write capacity units : 1 (Auto Scaling Enabled) - campaign_name (partition key) - String - 캠페인 이름 - base_date (sort Key) - Number - 기준 날짜 - dataset_import_job_arn - String - 생성된 Dataset import job 리소스 이름 - dataset_import_job_status - String - Dataset import job 생성 상태 - dataset_import_job_datetime - Number - Dataset import job 생성 시간 - solution_name - String - 솔루션 이름 - solution_version_arn - String - 생성된 솔루션 버전 리소스 이름 - solution_version_status - String - 솔루션 버전 생성 상태 - solution_version_datetime - Number - 솔루션 버전 생성 시간 - ex)
{
"base_date": 20200928,
"campaign_name": "brandi-hrnn-campaign-v2",
"dataset_import_job_arn": "arn:aws:personalize:ap-northeast-1:439438562359:dataset-import-job/brandi-dataset-interaction-prod-job-20200928",
"dataset_import_job_datetime": 1601257517,
"dataset_import_job_status": "ACTIVE",
"solution_name": "brandi-hrnn-solution",
"solution_version_arn": "arn:aws:personalize:ap-northeast-1:439438562359:solution/brandi-hrnn-solution/648d42c6",
"solution_version_datetime": 1601265645,
"solution_version_status": "ACTIVE"
}
2-3. Personalize 과거 데이터 갱신 프로세스는 단계별로 전부 갱신되어야 업데이트 되기 때문에 각각 다음 단계 실행이 필요합니다.
# 퍼스널라이즈 솔루션 버전업 생성
response = personalize_client.create_solution_version(
solutionArn='Solution Arn'
)
# 퍼스널라이즈 캠페인 업데이트
response = personalize_client.update_campaign(
campaignArn='Campaign Arn',
solutionVersionArn='Solution Version Arn',
)
2-4. Personalize 다음 단계 실행시 DynamoDB에 플래그를 변경합니다.
# 솔루션 버전 생성
dynamodb_table.update_item(
Key={
'campaign_name': dict_item.get('campaign_name'),
'base_date': int(dict_item.get('base_date')),
},
UpdateExpression='set solution_version_arn = :solution_version_arn'
',solution_version_status = :solution_version_status'
',solution_version_datetime = :solution_version_datetime'
',dataset_import_job_status = :dataset_import_job_status',
ExpressionAttributeValues={
':solution_version_arn': 'Solution Version Arn',
':solution_version_status': 'IN_PROGRESS',
':solution_version_datetime': int(time.time()),
':dataset_import_job_status': 'ACTIVE',
},
)
# 캠페인 업데이트
dynamodb_table.update_item(
Key={
'campaign_name': dict_item.get('campaign_name'),
'base_date': int(dict_item.get('base_date')),
},
UpdateExpression='set solution_version_status = :solution_version_status',
ExpressionAttributeValues={
':solution_version_status': 'ACTIVE',
},
)
2-5. AWS Personalize 콘솔 확인
Conclusion
이제 과거 데이터 갱신 시 자동으로 모델을 교육할 수 있게 되었고, 특별한 관리이슈 없이 잘 운영되고 있습니다.
증분식 업데이트를 아직 지원하지 않아 전체 데이터 대상으로 모델을 교육하기 때문에 비용과 시간이 많이 소요되는 아쉬운 점은 있었으나 추후 지원되길 기대하며 글을 마칩니다.
곽정섭 | 커머스 개발팀
kwakjs@brandi.co.kr



