AWS ElastiCache를 활용한 데이터 동기화 시스템의 개선
양정훈
2020-12-11
Overview
이번 글에서는 AWS ElastiCache를 활용해 서로 다른 서비스 간의 데이터 동기화 시스템을 개선한 과정을 공유하고자 합니다.
긴 시행착오를 겪은 작업이었고 개인적으로도 이번 개발을 통해 많은 것을 배우게 되었습니다. 부족한 내용이지만 이 글을 읽으시는 분들도 작게나마 도움이 되셨으면 합니다.
데이터의 동기화
현재 브랜디 시스템은 서로 다른 두 서비스의 서버 환경이 완전히 분리되어 있는 상태입니다. 하지만 양쪽 시스템의 데이터는 준 실시간으로 동기화가 이루어져야 하죠.
우리는 AWS SNS를 구독하거나, 목적지 시스템의 API를 직접 호출하는 식으로 이 요구사항의 구현을 꾀했습니다.
기존 연동 모듈의 구조
하지만 서로 다른 DB 서버의 데이터 상태를 맞춘다는 것은 쉽지 않은 작업이고, 저희는 지금도 안정화 개선 작업을 진행하는 중입니다.
가장 큰 문제는 SNS 구독을 통한 데이터 연동은 불안정할 수밖에 없다는 것이었습니다. 서버의 컨디션이 좋지 않거나, 또는 로직상의 버그가 발생할 수도 있죠. 연동이 실패했을 경우의 재연동 시스템이 필요했습니다.
에러가 발생했을 경우 똑같은 내용의 SNS 메세지를 가지고 연동이 요청된 순서대로 재연동이 수행되어야 했습니다. 또한 이 요청들은 일정한 지연 시간을 두고 진행되어야 했습니다. (서버의 컨디션이 즉시 좋아지지 않을 가능성이 높기 때문입니다. 준 실시간의 요구사항이 깨지게 되지만, 실패할 확률이 높은 요청을 빠르게 계속해서 수행할 수는 없었습니다.)
이 모든 요구사항을 만족하는 서비스가 AWS SQS였습니다. 연동이 실패했을 경우 FIFO SQS에 데이터를 쌓고, n분 간격으로 메세지를 dequeue해 동일한 람다 로직을 수행시켰죠. 재연동이 실패하면 다시 또 FIFO SQS의 맨 마지막 순번으로 쌓습니다.
계속해서 실패할 경우를 고려하지 않을 수 없었기에 최대 재요청 횟수의 제한을 뒀습니다. n분 간격으로 m번의 연동을 수행했으나 모두 실패했을 경우 별도의 FIFO SQS를 구성해 해당 SQS에 데이터를 쌓고 연동을 종료합니다. 이후 문제를 해결하고 해당 SQS를 수동으로 람다 트리거링해 연동을 수행시킵니다. (여기서도 연동이 실패하면 다시 m번 연동하는… 이 과정이 계속 반복됩니다.)
나쁘지 않은 방법입니다. 처음부터 연동을 다시 수행시키기 때문에 가장 확실한 방법이죠.
문제점
이 시스템에는 커다란 문제점이 한 가지 있었습니다. 실패 누락 건의 재연동에 소요되는 시간이 너무 길었습니다.
평상시에는 SNS로 요청이 오면 바로바로 연동을 수행하지만, 누락 건들은 순서대로 메세지를 dequeue해 연동 시키므로 이전 메세지의 연동이 완료될 때 까지 다음 연동 건들은 큐 안에서 대기하고 있다는 것이 문제였습니다.
누락 건이 몇 건 안 되면 큰 문제가 없었지만 서버 점검시에는 연동이 들어올 경우 m번 반복의 재시도를 건너뛰고 바로 연동 누락 SQS에 메세지가 저장되도록 했기 때문에 너무 많은 메세지가 쌓였습니다.
경우에 따라 달랐지만 누락 건을 다 연동시키는 데에 길게는 서버 점검 시간의 두 배 이상이 소요되고는 했습니다. 수행 시간의 단축이 시급했죠.
개선 사항
개선되어야 할 몇 가지 사항들이 보였습니다.
- 수행 시간 단축을 위해 누락건 재연동은 병렬로 동시에 수행되어야 할 필요가 있었습니다.
- 병렬로 수행하기 위해서, 연동 요청이 온 순서대로 동작되지 않아도 무방한지의 확신이 필요했습니다.
- 반복되는 작업이므로 누락건 연동과 관련된 모든 기능들이 손쉽게 동작 가능하며 모니터링이 용이하면 좋겠다 생각했습니다. Slack Slash Commands가 적절해보였죠.
- 연동 요청 온 순서대로 동작되지 않아도 된다면 FIFO SQS를 사용할 필요가 없다는 이야기였고 그렇다면 굳이 SQS를 사용해야할까,라는 생각이 들었습니다.
Standard SQS로도 이 모든 작업이 가능했지만 몇 가지 추가적인 개선 기능을 넣기엔 부적합하다는 판단이 들었습니다. (연동 시작 전에 전체 메세지를 백업해두고 싶었지만 SQS는 전체 메세지를 조회하는 데에는 적절하지 않습니다.)
다른 아키텍처로의 변경은 영향도가 크기 때문에 조심스러웠지만 어차피 많은 변경이 일어날 수 밖에 없는 작업이었습니다. 저희는 검토 끝에 AWS ElastiCache를 활용해 저장소를 Redis로 대체하기로 했습니다.
개선
이렇게 개선 사항들을 정리한 뒤 작업을 진행했고, 결과적으로 6개의 함수로 시스템을 구성했습니다 (함수 로직의 가짓수가 6가지일 뿐, 실제 AWS 상에 정의되는 람다는 2개로 구성했습니다.)
- 연동 누락 건 백업 후 재연동을 요청하는 함수
- 메세지를 조회해 건별로 비동기로 연동을 요청하는 함수
- 실제 연동을 수행하는 함수
- 모든 누락 건 메세지를 삭제하는 함수
- 재연동 수행 여부를 변경하는 함수
- Slack Slash Commands와 연동되어 적절한 람다를 호출하는 함수
실제 연동을 수행시키는 프로세스를 설명드리자면,
1. 누락 메세지의 수집
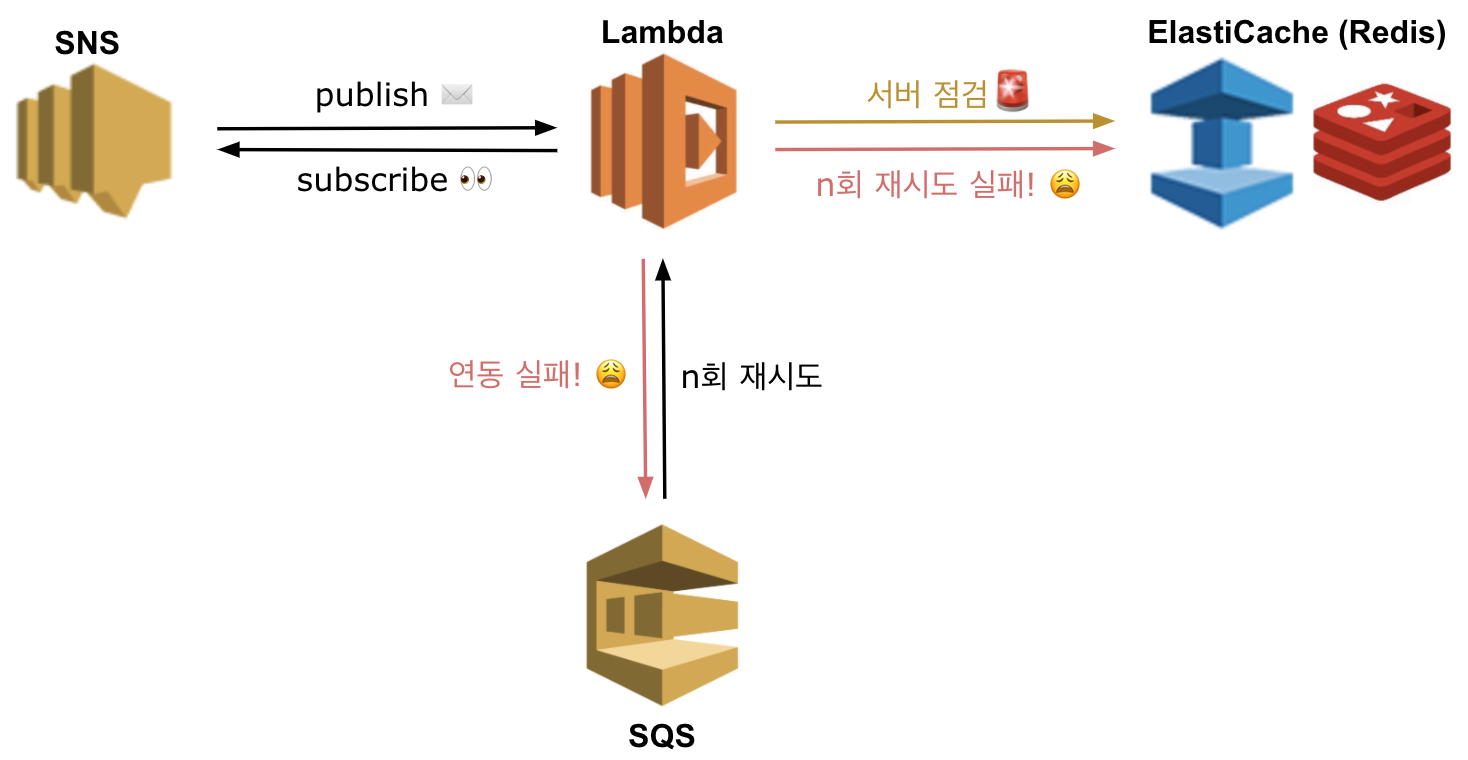
기존과 동일하나 메세지를 SQS가 아닌 Redis에 저장한다는 것의 차이가 있습니다.
서버 점검중이거나 재시도를 모두 실패하였을 경우 Redis에 저장합니다.
2. 연동 시작
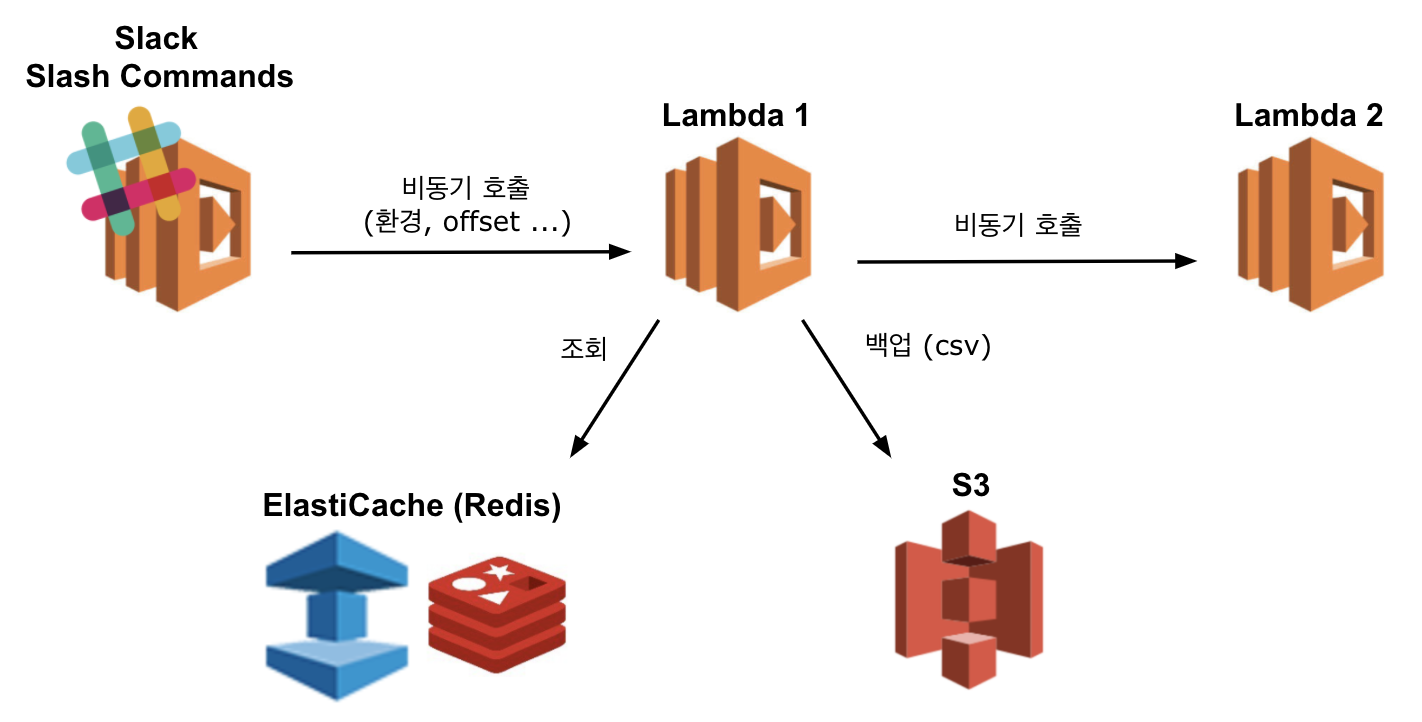
- Slack Slash Commands를 이용해 누락건들의 재연동을 요청하면
- 1번 람다는 Redis저장소에서 데이터를 조회해 csv로 가공, S3 버킷에 백업합니다.
- 이후 2번 람다를 비동기 호출 후 종료됩니다.
3. 연동 요청
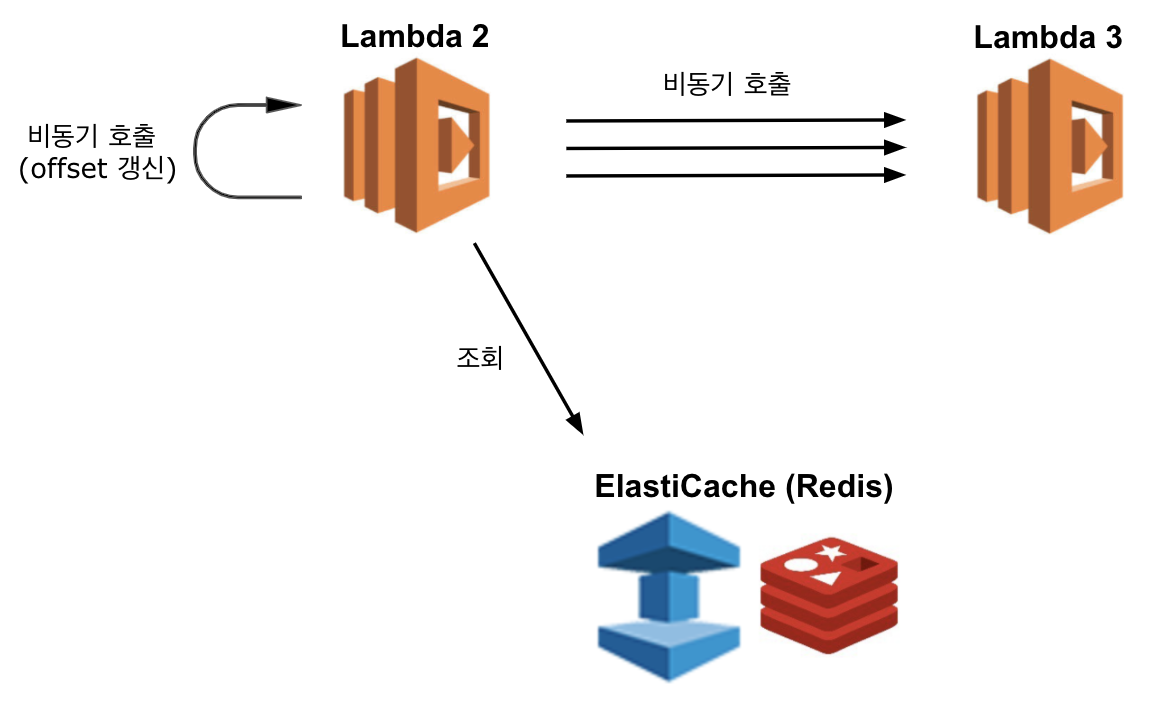
- 호출된 2번 람다는 Redis 저장소의 데이터를 n건 조회합니다.
- 조회한 메세지를 1건씩 가공해 짧은 지연시간을 두고 3번 람다를 계속 비동기로 호출합니다.
- Redis저장소에 메세지가 남아 있다면, 모든 호출이 끝나고 2번 람다는
갱신된 offset 정보로 다음 메세지를 조회할 수 있도록 다시 자기 자신을 비동기로 호출합니다.
남아있는 메세지가 없다면 2번 람다는 종료됩니다.
4. 연동 수행
호출된 3번 람다는 전달받은 1건의 메세지를 기반으로 데이터 동기화를 수행합니다. 여기서도 동기화에 실패한다면 다시 위의 n번 재시도를 반복하다가 Redis에 쌓이게 됩니다. 이렇게 백업과 반복 재시도로 연동 메세지의 유실을 방지했습니다.
5. 메세지 삭제
- 모든 연동이 완료되었다고 판단되면, Slack Slash Commands를 이용해 4번 람다를 호출합니다.
- 4번 람다는 Redis저장소의 모든 메세지를 삭제합니다.
연동 중지!
저희는 Redis저장소에 현재 연동을 수행시킬 수 있는 상태인지의 YN 필드를 정의해두었습니다.
위의 연동 과정 중간중간마다 해당 필드를 체크하고 있어, 어느 시점에서던지 필드의 값을 N을 바꾸면 연동이 중지됩니다.
해당 YN 플래그 값의 변경 역시 Slack Slash Commands를 이용해 수행할 수 있습니다.
결과
이러한 개선 작업을 통해 결과적으로 우리는 연동 소요 시간을 5배 이상 단축시키는 결과를 만들어냈습니다. 3번 람다를 비동기로 호출하는 사이의 지연시간은 테스트를 통해 더 조절할 수 있을 것으로 보여 추가적인 시간 단축도 가능해보입니다.
Slack의 연동도 좋은 선택이었던 것으로 보입니다. 반복적으로 수행되어야 하는 동작이므로 간편하게 동작시킬 방법이 필요했죠.
중간중간의 연동 수행 상황을 슬랙으로 알람이 오도록 연동해둔 것도 좋은 모니터링 수단이 되어주고 있습니다.
Conclusion
일단의 개선은 이루었지만 이루어지는 동작에 비해 아무래도 구조가 너무 복잡하다는 느낌은 지울 수가 없습니다. 시스템이 복잡해지면 장애로 이어지기 마련이죠.
처리해야할 데이터의 양이 늘어나면 늘어날수록 한계가 드러날 수밖에 없는 구조이기도 합니다. 어찌됐건 짧은 시간차를 두고 한건 한건 연동을 수행하고 있기 때문에 데이터의 양에 정비례해 소요 시간이 늘어나게 됩니다.
서로 다른 두 메세지의 동기화 결과 데이터가 같다면 굳이 여러번 수행시킬 필요는 없겠죠. 현 시스템에서 충분히 발생할 수 있는 케이스이고, 이 또한 소요시간의 단축을 꾀할 수 있는 부분입니다.
많은 변경이 있었지만 이렇듯 여전히 개선해야 할, 개선할 수 있는 요소들이 눈에 보입니다. 여러 고민거리들 또한 산재해있는 상황입니다. 저는 일단의 이루어낸 결과에 만족하고 욕심을 버리기로 했습니다. 결국 완전무결한 시스템이란 없고, 현재의 상황과 환경에 적절한 시스템만이 존재할 뿐이니까요.
양정훈 | 풀필먼트 개발팀
yangjh@brandi.co.kr



