Serverless 환경에서 수행시간이 긴 작업 처리하기
김민세
2021-05-31
Overview
현재 브랜디 풀필먼트시스템의 기본적인 API는 모두 Serverless로 구축되어 있습니다.
그동안 브랜디의 모든 헬피셀러를 풀필먼트시스템에 적재하여 운영하면서 대용량 데이터를
Serverless 환경에서 운영할 수 있도록 고도화 한 작업들에 대해 이야기 해보고자 합니다.
익숙한 아키텍처의 함정
초기 풀필먼트 서비스의 API는 일반적으로 사용하는 아키텍처인 백엔드 API에서 모든 데이터를
가공 및 조회하여 JSON형태의 결과를 내려주고 프론트엔드에서 데이터를 보여주는 형태로
되어 있었습니다. 다만 데이터가 적은 상황에서는 문제 없이 동작하였으나 차츰 데이터량이
늘어남에 따라 Lambda 및 API Gateway의 할당량 제한으로 인하여 기존 아키텍처를 사용하여
데이터 처리가 힘들어지게 되었습니다.
Lambda와 API Gateway의 할당량
Lambda와 API Gateway의 여러가지의 할당량이 있지만 API에 가장 영향을 주는 할당량에 대해서만
간략하게 적어보았습니다.
Lambda
- 동시실행 : 1,000개 (증가 요청 가능)
- 함수 메모리 할당 : 128MB ~ 10,240MB, 1MB씩 증분됨
- 함수 제한시간 : 900초 (15분)
- 호출 페이로드 (요청 및 응답) : 6MB (동기식), 256KB (비동기식)
API Gateway
- 최대 통합 제한 시간 : 30초
- 페이로드 크기 : 10MB
API에서 Lambda를 사용하기 위해서는 API Gateway가 필수적으로 사용되는데 위에 나온 할당량에
의해서 30초 이내에 모든 작업이 완료되고, API 응답 데이터량은 6MB 이내로 처리되어야 합니다.
위의 할당량이 초과된 경우에는 프론트엔드에서 정상적으로 데이터를 받을 수 없게 됩니다.
Lambda와 API Gateway의 할당량에 의해 많은 영향을 받는 서비스
초기 풀필먼트시스템에서 API로 구현된 기능 중 앞으로 데이터량이 많아짐에 따라 할당량
제한으로 기능을 사용하지 못할 것이라 예상되는 기능들은 다음과 같았습니다.
- 대용량 데이터 엑셀 다운로드
- 많은 데이터를 한번에 가공하여 저장하는 기능
- 외부 API를 사용하여 처리시간을 정확하게 알 수 없는 기능
위의 기능들은 풀필먼트시스템 베타 오픈과 동시에 바로 개선이 되어야 하는 부분으로 빠른 처리가
필요했습니다. 최대한 공수가 적게 들면서 안정적으로 처리 할 수 있는 방안을 모색해야 했습니다.
페이징을 사용한 방법
현재 풀필먼트시스템에서 엑셀 다운로드 기능은 여러 페이지에서 사용중에 있습니다.
필자가 담당한 부분인 재고부족요청 페이지의 엑셀 데이터는 셀러수가 늘어남에 따라
주문수가 증가하고 그에 따라 노출되어야 하는 데이터량도 자연스럽게 증가하게 되었습니다.
엑셀리스트 데이터를 한번에 조회하는 방식을 크게 변경하지 않고 리스트 결과 데이터에
총 결과 데이터 수를 최초 1회만 조회하도록 추가 하여 페이징 처리를 통해 페이지 수만큼 조회를
다시 하는 방식으로 구현하였습니다.
this.payload.isFirst = 'true'
this.payload.offset = 0
this.payload.len = 500 // 500개 씩 페이징
let response = await this.$store.dispatch('excelList', this.payload)
let totalCount = response.totalCount
let dataList = response.dataList
delete this.payload.isFirst
if (totalCount <= 0) {
alert('다운로드할 데이터가 없습니다.')
return false
}
// 2회 이상 추출되어야 할 경우
if (totalCount > this.payload.len) {
for ( let i = 1; i < Math.ceil(totalCount / this.payload.len); i++ ) {
this.payload.offset = i * this.payload.len
let response = await this.$store.dispatch('excelList', this.payload)
dataList = dataList.concat(response.data.dataList)
}
}
// dataList 엑셀 가공 및 다운로드
// ...
Lambda Invoke를 사용한 방법
API Gateway는 30초 제한이 있기 때문에 Lambda의 최대 15분 할당량을 모두 사용 할 수 없었습니다.
방법을 고민하던 중 15분을 모두 사용가능한 Lambda를 추가로 생성하여 작업 API 호출 시 Invoke로
Lambda에 처리 할 기본적인 데이터만 보내어 처리 하는 방법을 고안해 내었습니다.
처리과정을 정리하면 다음과 같습니다.
- 기능이 현재 동작중인지 Lambda 1에서 DynamoDB를 확인하여 상태 체크
- 백그라운드에서 동작중인 작업이 없을 경우 Lambda 1 (API) 에서 비동기 Invoke로 Lambda 2 (데이터 처리용) 를 호출
- Invoke로 호출 받은 Lambda 2에서 데이터 처리 (최대 15분)
- 데이터 처리 진행중 작업 상태에 대하여 DynamoDB에 저장 (TTL 15분)
- 프론트엔드에서 주기적으로 상태 체크 API를 호출하여 DynamoDB에 있는 상태 조회 및 처리 결과 노출
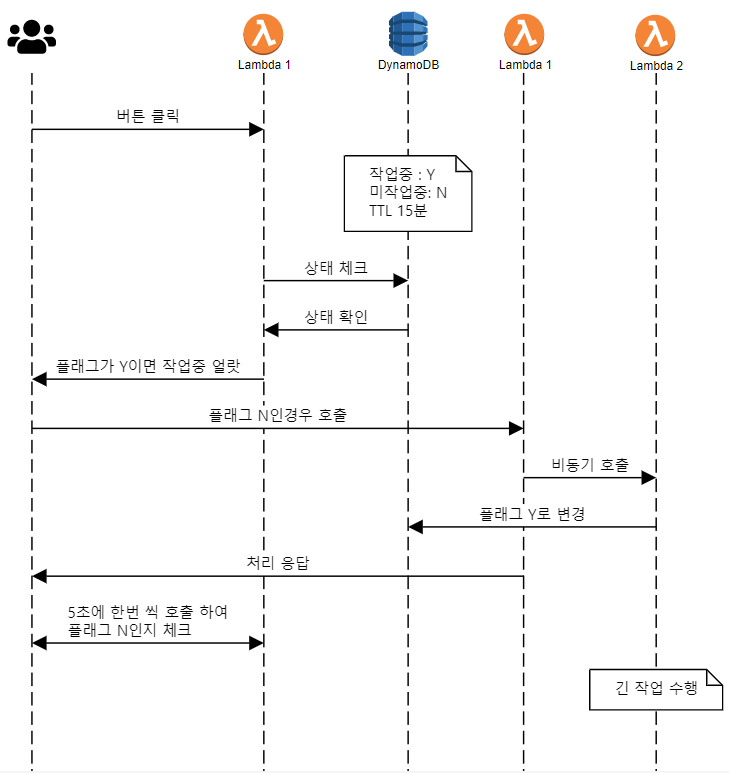
위와 같이 백그라운드에서 작업을 실행하는 경우에는 일반적으로 중복으로 작업이 진행되면
안되었기에 상태체크 및 작업 여부에 대해서 확인이 필수적으로 필요하게 되었습니다.
Lambda 2에서 15분 이상 걸리게 되는 작업이 발생하게 될 경우를 대비하여 DynamoDB에 저장한
상태 정보를 TTL을 15분으로 설정하였고, 상태 체크 시에는 해당 플래그의 생성시간이 15분이
지나지 않은 정보만 가져올 수 있도록 로직에서 처리하였습니다.
DynamoDB에서 TTL를 설정하여도 실제 삭제는 Redis처럼 바로 삭제되는 것이 아니기 때문에
로직처리로 조회하는 것이 정확한 데이터를 가져올 수 있었습니다.
시퀀스 다이어그램을 작성하고 개발을 진행할 때 Lambda Invoke 방식을 개발환경에 어떻게 구현을
해야 할지 고민이었으나, 저희 팀의 리더인 현준님의 아이디어룰 기반으로 Thread를 통해
Lambda Invoke를 비슷하게 구현하여 로컬 개발 및 테스트가 가능하였습니다.
event = {
'payload': payload,
'lambda_name': lambda_name,
'headers': headers,
}
# 비동기 요청
if is_async:
def __worker(event):
index.handler(event, {})
import threading
worker = threading.Thread(target=__worker, args=(event , ))
worker.start()
# 동기 요청
else:
# ...
또한 수행시간이 15분이 넘어 갈 경우 작업자분들의 노티가 있을 때까지 알 수 없기 때문에 Slack을
통해 작업 시간을 실시간으로 모니터링을 하고 있습니다.
Async Queue를 사용한 방법
풀필먼트 시스템에서 특정 API는 외부 API를 사용하여 연동하는 작업을 진행하고 있습니다.
외부 API서버 처리 능력에 따라 총 처리시간이 매번 달라지고, 1회에 보낼 수 있는 데이터량도 제한
이 있어서 1회 호출로 모든 데이터를 처리하는 기존 방식을 개선하여 데이터 묶음 단위로
1건씩 처리하도록 변경하였습니다.
예를 들어 아래와 같은 데이터 묶음이 있다고 가정하면,
{
"data": [
"one", "two", "three", "four", "five", ......
]
}
프론트엔드에서 데이터를 나누어 호출 시 아래와 같이 데이터를 보낼 수 있도록 처리하였습니다.
// 1회
{
"data" : "one"
}
// 2회
{
"data" : "two"
}
// 3회
{
"data" : "three"
}
// N회
......
설명한 내용을 구현한 로직은 다음과 같습니다.
import Queue from 'async-await-queue'
let payloadList = [{..}, {..}, {..}, ......] // 처리되어야 할 데이터
let jobQueue = new Queue(10, 100) // 동시실행 최대 수, 호출 간격 (ms)
let queueId = ''
let queueList = []
let totalCount = payloadList.length
for (let i = 0 ; i < totalCount ; i ++) {
queueId = Symbol()
queueList.push(jobQueue.wait(queueId, -1) // -1은 우선순위 (기본값)
.then(() => process(i, payloadList[i], totalCount))
.catch((e) => {
// 예외처리
})
.finally(() => jobQueue.end(queueId)))
}
process (index, item, totalCount) {
// 처리 로직
}
Async-await-queue 라는 오픈소스 라이브러리를 사용하여 구현하였고, 동시 실행 수와 호출 간격의
두가지 옵션을 사용 할 수 있었습니다.
Async Queue를 사용하면서 1회 커넥션을 사용하던 기존 방식에 비해 DB 커넥션을
매번 API를 호출 할 때마다 맺기 때문에 커넥션 수가 다소 증가하게 되어 옵션을 통해 동시성을
제어하였습니다. 그리고 비동기로 처리 되어 결과값에 순서가 필요한 경우 호출 시에 순서 데이터를
같이 보내어 로직에서 데이터 처리 후 별도의 스토리지에 저장하고 순서 데이터로 정렬하는
방식으로 해결하였습니다.
Conclusion
Serverless 환경에서 여러 기능을 위와 같은 방식으로 아키텍처를 구성하거나
로직을 구현하면서 Lambda는 서버관리 측면에서는 너무 편하지만 할당량 제한에 주의해서
개발을 해야겠다는 생각이 많이 들었습니다.
앞으로 Serverless 환경으로 어플리케이션 구현을 고려해야 한다거나,
수행시간에 따른 문제에 직면한 개발자 분들께 이 글이 도움이 되었으면 좋겠습니다.
참고자료
- https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/gettingstarted-limits.html
- https://docs.aws.amazon.com/ko_kr/apigateway/latest/developerguide/limits.html
김민세 | 풀필먼트개발실 풀필먼트개발팀



