Brandi DA 의 데이터 분석 비망록
윤현석
2023-07-28
Brandi DA 의 데이터 분석 비망록
안녕하세요, AI 검색팀 데이터 분석가 윤현석입니다. 브랜디의 데이터 분석가로 경험한 일들을 소개하고자 글을 쓰게 되었습니다.
제가 이번에 가져온 이야기는 RFM부터 시작합니다. 커머스 분야에 관심이 있으신 분들은 매우 친숙한 주제일 것 같은데요. RFM 모델이 고객 분석, 셀러 클러스터링, CRM 캠페인에 각각 적용된 과정과 결과에 대해 이야기해 드리고자 합니다.
1. RFM 이란?
RFM framework 는 가장 기본적인 고객 분석 방식 중 하나입니다. 구매의 최근성을 의미하는 recency, 구매 빈도를 의미하는 freqeucny, 구매액을 의미하는 monetary 를 세 축으로 하여 고객이 가지는 특징을 분석하는 방법입니다. (최근성과 구매빈도, 구매액은 각각 recency, frequency, monetary로 서술하도록 하겠습니다.)
기본적으로는 구매데이터를 이용하여 만들고, 새로운 고객들을 유치하는 것 보다 기존에 구매했던 고객을 관리하는 것에 중점을 둔 분석방법이라고 할 수 있겠습니다.
RFM framework 가 가지는 장점은 단순함에서 옵니다. recency, frequency, monetary 라는 변수는 누구라도 그 의미를 이해할 수 있고 손쉽게 변수를 정의할 수 있으므로 빠르게 분석을 시작할 수 있습니다.
또한 3가지 변수를 이용하여 고객군을 정의할 수 있으므로 여러 가지 방식으로 시각화가 용이합니다. RFM framework를 이용하면 플랫폼 안의 셀러에게 본인의 고객과 관련한 시각화 자료를 제공할 수 있으며, 내부적으로 확인할 수 있는 리포팅에도 사용할 수 있습니다.
그리고 RFM 변수 자체가 고객들의 구매행동의 중요한 지점을 잘 설명하고 있기 때문에 추후 framework를 고도화하거나 다른 모델의 파라미터로 사용될 수 있습니다.
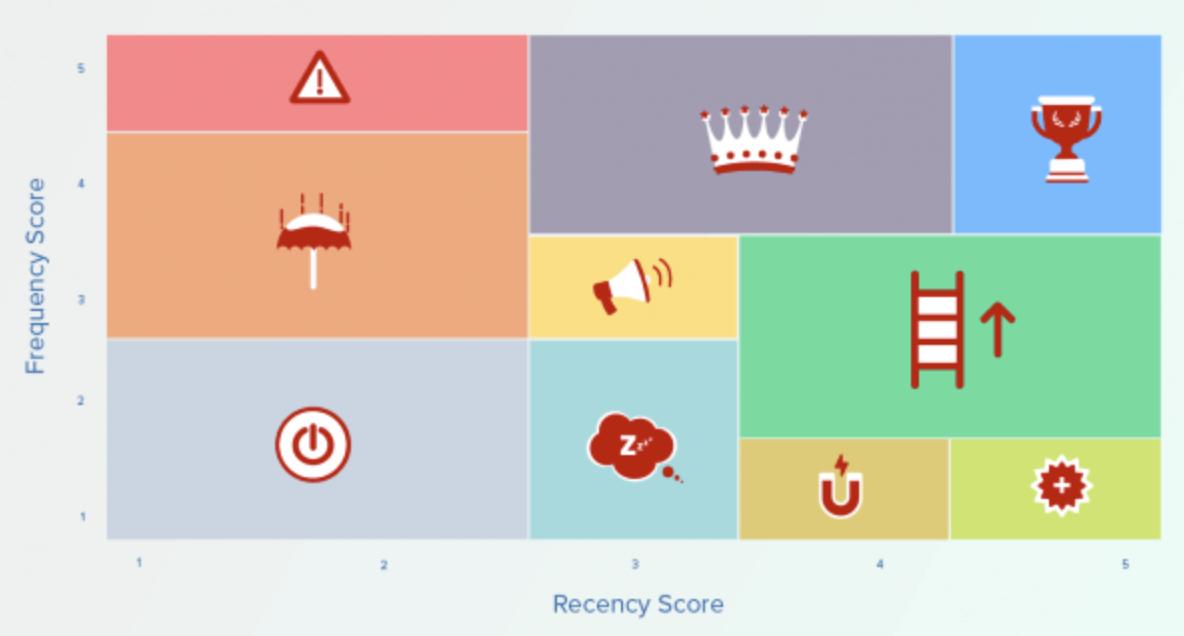
따라서 RFM framework 는 단순하고 사용하기 쉽고 범용적이므로 처음 시작하는 분석 프로젝트로 선택했습니다.
RFM framework를 적용하기 위해서 선행적으로 브랜디 서비스라는 비즈니스 도메인의 특징을 고려할 필요가 있었습니다. 먼저 전체 이용자수에 기반하여 RFM점수 스케일을 확정했습니다.
또한 앱 기반의 이커머스 특성상 구매 기록과 더불어 앱 내에서의 행동 데이터 또한 함께 확인할 필요가 있었습니다. 특히 recency, frequency 의 경우, 구매와 앱 방문 각각의 최근성과 빈도가 중요한 변수로 될 수 있기 때문에 해당 변수들도 고려해야 했습니다.
마지막으로 패션 커머스의 특성상 구매의 시즌성을 고려해야 했습니다. 이는 RFM framework 에서 사용하는 데이터의 시간적 범위를 정의하는 문제로 생각했는데요, 기본적으로 패션업계는 S/S, F/W 로 나눠지는 시즌성이 존재하고, 이에 따라서 구매 행동 또한 달라질 것으로 생각했기 때문입니다. 이 문제는 데이터를 통해 확인하는 과정과 함께 사업부 분들과의 협업 과정에서 구매 빈도와 행동의 분기별 차이를 확인하고 이를 기반으로 해결하게 되었습니다.
2. 분석 과정
실제로 브랜디 서비스의 데이터를 분석하는 과정에서 제일 먼저 풀어야 하는 것은 변수 선택 문제였습니다. RFM은 추후에도 여러 가지 모델이나 리포팅 결과에서 사용될 수 있는 만큼 변수의 결정과 결정 근거의 확립이 선행되어야 했습니다.
고려한 변수들 중 구매와 관련된 데이터는 최근 구매일, 구매 빈도, 구매량을 사용했습니다. 활용하는 데이터의 범위는 사업부와의 협의 후 3개월로 설정하였습니다.
행동 데이터는 최근 접속일, 접속 빈도를 고려했습니다. 이유는 앱 서비스의 특성상, 고객의 행동 또한 중요한 지표로 사용될 수 있기 때문입니다. 추가적으로 구매와 구매 사이에 걸리는 시간의 평균, 접속과 접속 사이에 걸리는 시간의 평균을 duration 으로 정의하여 고려했습니다. 이 경우 RFM 이 고려하지 못하는 특정 시간 내의 구매 집중도를 확인할 수 있는 지표라고 생각했기 때문에 추가했습니다.
변수들을 선택할 때 사용했던 기준 두 가지는 “시각화 가능하게 할 것”, “선택된 변수들을 기반으로 고객들을 나눌 수 있게 할 것”이었습니다. 효과적인 시각화를 가능하게 하기 위해서는 변수를 2개로 제한하여 2차원상의 도표를 그릴 수 있어야 한다고 생각했고, 각 변수 별 상관관계 분석을 통해 높은 종속성을 보이는 변수를 우선적으로 제거하였습니다. 이 때 구매 frequency 가 monetary에 대해 매우 높은 0.8의 상관관계를 보였으므로, monetary를 제거하고 frequency 를 한 축으로 선정했습니다. 이는 frequency 가 monetary를 충분히 설명할 수 있다고 생각했기 때문입니다. 반면 구매의 recency나, 행동데이터 기반의 frequency, recency는 monetary와의 상관관계가 낮게 나타났습니다. 결국 많이 접속하고 최근에 접속했다고 해서 반드시 많은 금액을 사용하는 고객은 아니었다는 것을 확인할 수 있었습니다.
duration 의 경우 3개월 기준을 적용했을 때 구매가 2회 이상 이루어지지 않은 고객이 전체 framework 상의 상당 부분을 차지하였습니다. 대다수 고객의 duration이 0이었음을 의미합니다. 이 경우 duration 을 통한 고객 구분은 크게 의미가 없다고 생각하여 제거했습니다.
구매와 접속(행동 기반)의 recency의 경우는 두 변수 모두 구매 빈도와 유사한 관계를 보였습니다. 두 변수 모두 monetary와 frequency 만큼 큰 관계를 보이지는 않았으나 frequency 와는 정적인 관계를 보였으며, recency 자체의 분포 또한 유사한 모양을 가졌습니다. 그러나 구매를 기준으로 변수를 만드는 것이 접속을 기준으로 데이터 처리 하는 것보다 분산이 더 컸고, (분포의 왜도가 더 작았습니다.) 이는 고객들을 보다 명확하게 분류할 수 있다는 장점을 가진다고 생각했습니다. 또한 사업부와의 협업과정에서 일반적으로 recency를 구매의 최근성의 의미로 사용하게 되어 RFM framework 는 구매데이터를 이용한 recency score 과 frequency score 를 이용해 고객을 분류하는 framework 로 사용하게 되었습니다.
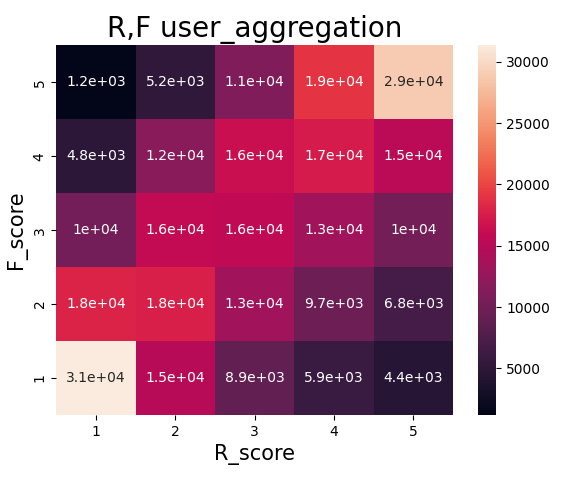
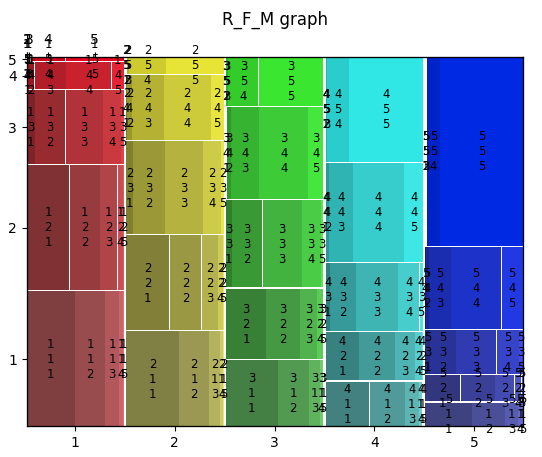
이렇게 정의한 변수들의 특징은 추후 고객 군집을 정의하는 데에 주요한 근거가 되었습니다.
먼저 frequency 의 상위 20% 고객들이 전체 monetary의 절반 이상을 차지하고 있는 사실을 통해, 브랜디 서비스 플랫폼이 pareto principle 을 충실하게 반영한다는 것을 알 수 있었습니다. 또한 하위 60% 고객들은 정의된 time scope 내에서 한 번만 구매한 고객들로 이루어졌습니다. 따라서 frequency 점수만을 기준으로 구별했을 때 하위 60% 고객, 상위 20% 고객 그리고 그 외의 고객들로 크게 구분할 수 있었습니다. 반면 recency 의 경우는 frequency 값에 비해 균일하게 분포되어 있었고 명확한 분류 기준을 잡기가 어려웠습니다. 따라서 임의적으로 구분을 해 주었는데요, 이 점은 이후에 진행한 sequential pattern mining 을 통하여 보완했습니다.
분석 과정 초기의 고객 군집 정의는 앞서 말씀드린 각 변수들이 보이는 대강의 분포를 기반으로 정의했는데요. 사업부와의 회의 과정에서 시간대별, 군집별 이동을 시각화하여 확인하고 비슷한 이동 양상을 보이는 군집들로 정의하였습니다. 가장 중요하다고 판단한 군집은 vip 군집으로 해당 군집은 이후 사업부와의 협업에서 가장 면밀히 분석하게 되는 유저군이 되었습니다.
이후 마케팅실과의 협업을 통한 CRM 캠페인 기획 과정에서는 vip 군집 외의 다른 유저 군집 또한 면밀히 확인해야 하는 필요가 생겼고 이 과정에서 sequential pattern mining 을 통해 확인한 군집 간 이동의 빈발 패턴을 기반으로 하여 군집을 다시 정의하게 되었습니다.
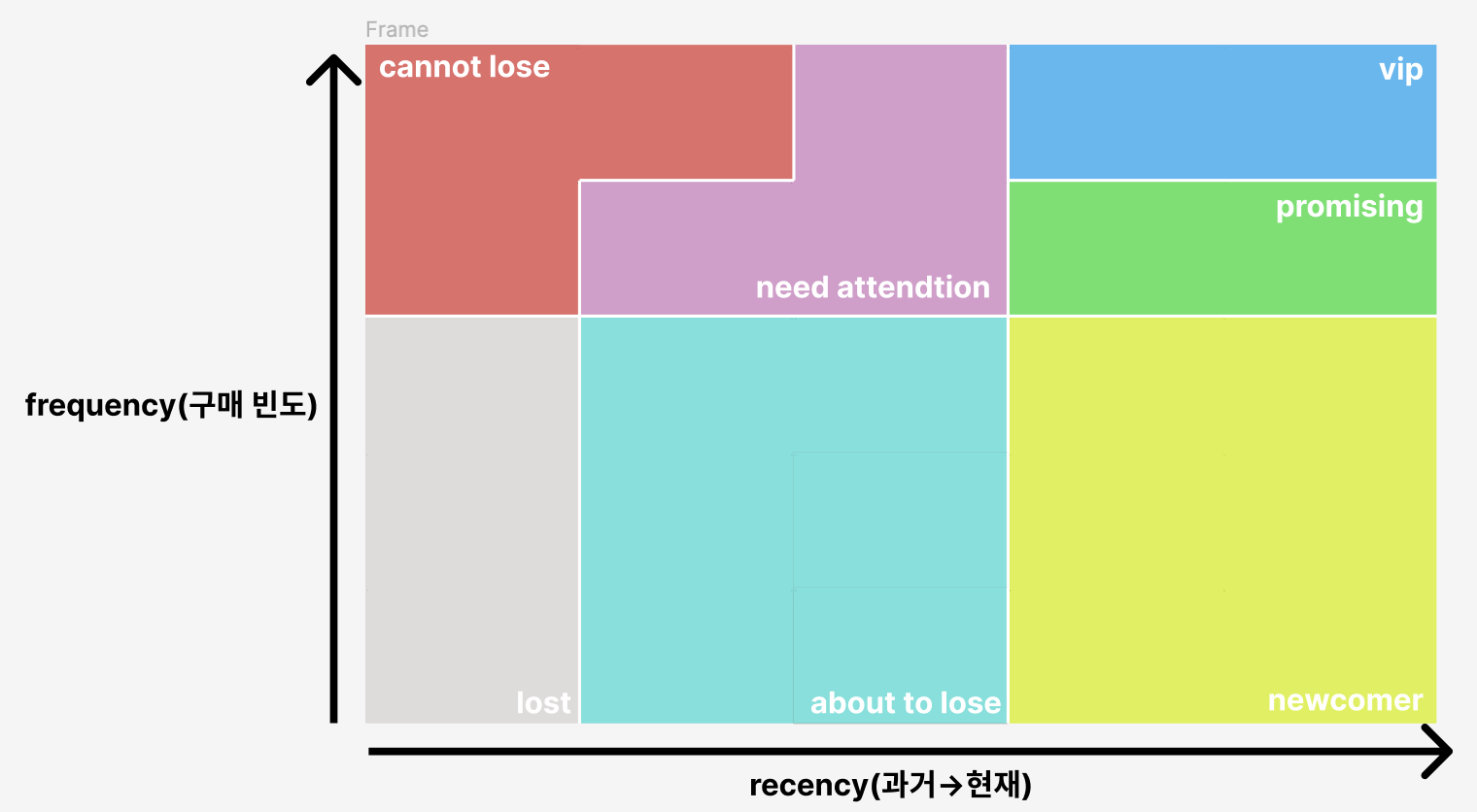
3. 함바지 Project 적용 사례
RFM 활용 방안 중 하나는 현상분석을 위한 분석 framework로의 이용인데요. 함바지 project로 명명한 사업부와의 협업에서 RFM은 브랜디 서비스 내의 고객들의 행동 양상을 확인하고, 고객 - 상품 - 셀러의 전체적인 그림을 이해하기 위한 framework로 사용되었습니다.
(함바지 프로젝트라는 이름의 기원은 사업부와의 협업 과정에서 나온 신조어로 ‘청춘은 바로 지금부터’라는 건배사를 이용해 만든 ‘함수는 바로 지금부터’라는 구호 아닌 구호에서부터 시작되었습니다. input을 받고 output을 산출하는 ‘함수 같은’ 저희 팀의 특징을 잘 나타낸 표현이라고 생각합니다!)
이 협업에서 가장 중요하게 생각한 문제 중 하나는 전체적인 시야에서 브랜디 서비스를 이용하는 유저들의 분포를 셀러들과 연관지어 조망하는 것이었습니다. 여기서 사용된 RFM 분석은 단순한 시각화 용도에서 더 나아가 보다 거시적인 유저 분석 framework로 활용하고자 했습니다. 이 과정에서 사용된 RFM 기반 유저 군집화는 분석 결과를 보다 단순하게 설명할 수 있게 했습니다.
“유저가 누구인가?”의 질문은 “유저는 왜 이탈하는가?”의 질문과 연결되었는데요. 우리는 현재 가장 임팩트가 큰 유저 군집의 이탈을 집중적으로 분석하기 위해 RFM 기반의 유저 군집을 사용했습니다. 이 과정에서 전체 유저 중에 가장 큰 구매력을 가지고 있는 VIP 군집(recency 와 frequency 가 가장 높은 군집)의 이탈을 타겟하게 되었습니다.
아이디어 중 하나는 Seller Tier Framework 였는데, 브랜디 서비스 내에서의 셀러의 거래량과 신규 상품 판매 성공율을 이용하여 셀러의 등급을 나누는 관점이었습니다. 해당 관점을 통해서 바라봤을 때, “높은 등급의 셀러가 플랫폼에서 이탈하게 되면, 해당 셀러를 이용하던 유저들 또한 함께 플랫폼에서 이탈하지 않을까?” 라는 아이디어를 생각해 낼 수 있었고, 이를 시각화하여 본 결과는 다음과 같았습니다.
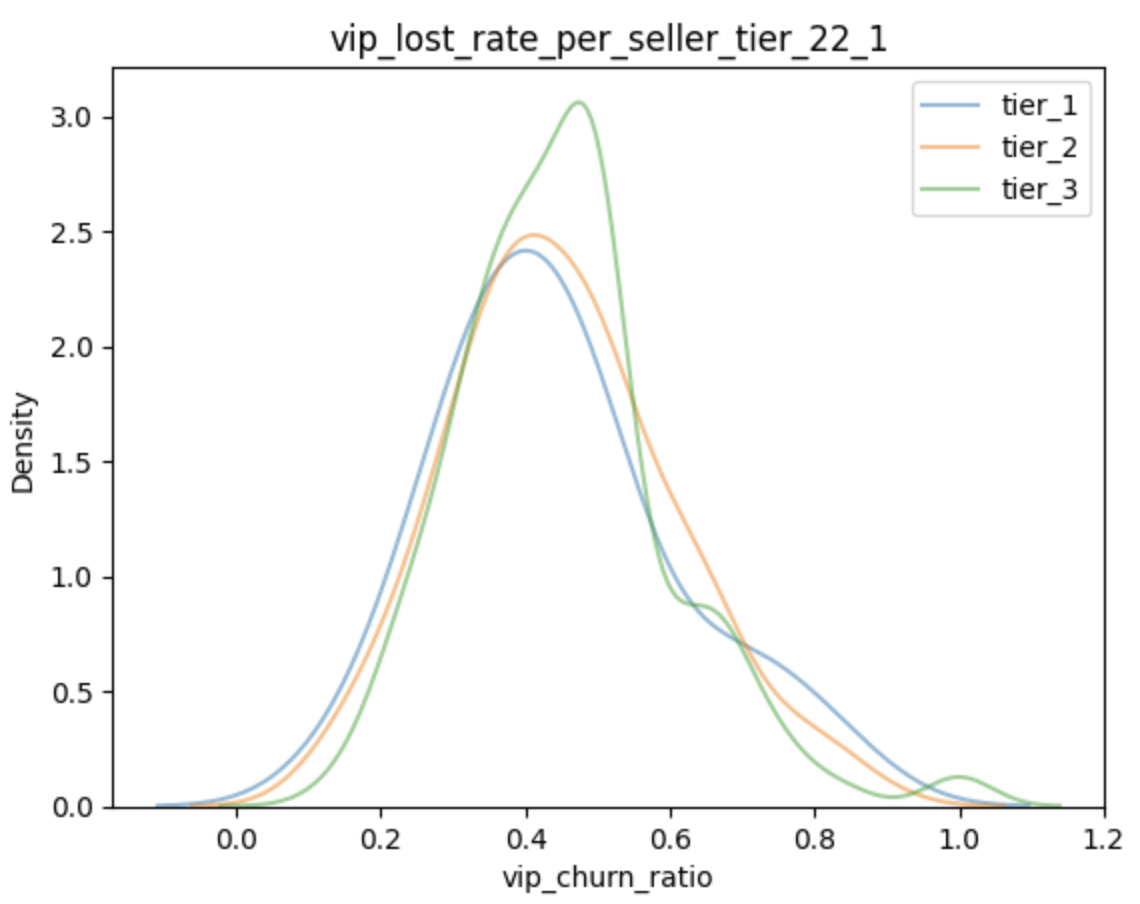
이러한 그림을 분기별로 그릴 수 있었고 시각화하여 보았을 때 셀러의 등급과 VIP 고객의 이탈의 상관성은 낮아 보였습니다.
이에 두 번째로 확인한 아이디어는 user engagement 지표였습니다. 이는 어떤 고객이 어떤 셀러에게 얼마나 연관되었는가를 보여주는 지표로, 다음과 같이 정의하였습니다.
\[user~seller~engagement=\frac{N(user~purchase~count_i\mid seller_j)}{N(user~purchase~count_i)}\]다시 말해, 특정 유저가 구매한 상품에서 특정 셀러가 판매하는 상품의 비율을 의미합니다. 이를 기준으로 다시 티어를 나누고 히스토그램을 그려 보았을 때, 다음과 같은 분포의 차이를 보였는데요,
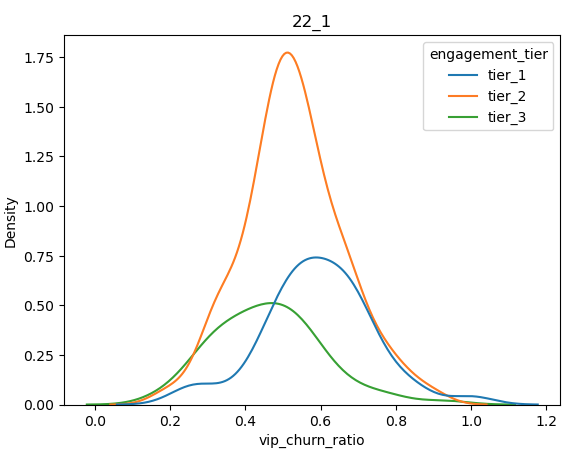
1등급과 3등급 셀러의 분포는 명확한 차이를 보였습니다. 이러한 결과를 확인한 후 다음 고민은 이탈하는 유저를 막기 위해서 셀러 관리 차원에서는 어떤 노력을 할 수 있는지에 대한 것이었는데요, 이를 더 구체화하면 “어떤 셀러를 중점적으로 관리하여 고객의 이탈을 방지할 수 있는가?” 였습니다.
앞서 확인한 결과를 기반으로 생각해 보면 engagement 가 큰 셀러를 우선적으로 관리할 수 있었습니다. 그러나 단순히 engagement 값만을 이용하여 셀러가 관리 우선순위를 정하는 것은 한계가 있었습니다. 예를 들어 단 한 명의 충성고객을 가지고 있는 셀러와 10,000명의 일반 고객을 가지고 있는 셀러 중 관리 우선순위를 정하는 것은 몇 가지 변수를 이용하여 해결하기 어려운 문제였습니다. 이에 저희는 문제를 보다 일반적으로 접근하기 위해서 클러스터링 방법을 사용하기로 하였습니다.
클러스터링 방법은 여러 가지 변수를 한 번에 고려하여 특정 셀러와 다른 셀러가 얼마나 ‘유사한지’를 보여줄 수 있는 방법입니다. 클러스터링 방법을 사용하면 engagement 뿐만이 아니라, 거래량, 이용 고객 수, 판매하고 있는 상품의 카테고리 등 여러 가지 정보를 한번에 고려할 수 있게 됩니다. 기존에 사용했던 셀러 구분 방법들은 거래량, hit rate, engagement의 3가지 변수만을 사용하는 방법이었습니다. 그러나 클러스터링 방법을 잘 활용하게 되면 여기에 더해 여러 가지 특징들을 한 번에 설명할 수 있다는 강점이 있습니다. 또한 특정 셀러와 유사한 셀러가 얼마나 많은지를 확인할 수 있기 때문에 어떤 셀러가 더 ‘대체 불가능한지’ 를 알 수 있습니다. 따라서 클러스터링 결과를 이용해 얻는 ‘대체 불가능성’ 정도는 관리 우선순위와 관련한 직관적 지표가 될 수 있다고 생각했습니다.
4. Seller Clustering
앞서 분석한 것은 결국 어떠한 셀러가 더 영업의 우선순위를 가지는지를 확인하기 위한 작업이었습니다. 저는 클러스터링 작업을 통해 문제의 일반화를 시도하였는데요. 셀러를 동질적인 특징들을 기준으로 클러스터링하게 되면, 해당 셀러와 비슷한 성향의 셀러가 얼마나 있고, 얼마나 특별한지 파악할 수 있기 때문입니다. 예를 들어 특정한 셀러가 상대적으로 작은 크기의 군집에 존재한다는 것은, 그 셀러의 특징과 유사한 셀러들이 얼마 없다는 것이고, 이 말은 대체되기 어려운 셀러라고 생각할 수 있습니다.
먼저, 기본적으로 셀러들이 가지고 있는 거래액, 판매중인 상품의 카테고리 종류, 앞서 정의한 hit rate, 유저들의 engagement 를 이용하여 클러스터링을 수행해 보았습니다. 클러스터링 방법론은 DBSCAN 방법을 이용했고 시각화를 위해 t-SNE 방법을 이용했습니다. DBSCAN 클러스터링 방법은 밀도 기반 클러스터링 기법으로 흔히 사용되는 k-means 방법에 비해서 미리 군집의 크기를 지정할 필요도 없고, 데이터의 형태를 미리 가정할 필요가 없기 때문에 사전에 데이터 분포를 알지 못하는 지금 같은 상황에서 유용하게 사용할 수 있는 알고리즘입니다. (DBSCAN 방법에 대한 자세한 설명은 appendix 에 첨부하였습니다.)
클러스터링 결과는 다음과 같았습니다. 5개 군집에서 군집을 구성하는 변수들의 분포를 확인했을 때 판매하고 있는 상품 카테고리 유형에 따라서 대부분 군집화가 일어난 것으로 보였습니다. 크게는 옷(원피스, 니트 등)을 파는 셀러와 악세서리, 뷰티 용품을 파는 셀러로 구분되었고 거래액 기준으로는 옷을 파는 셀러들이 당연하게도 높은 거래액을 차지하였습니다.
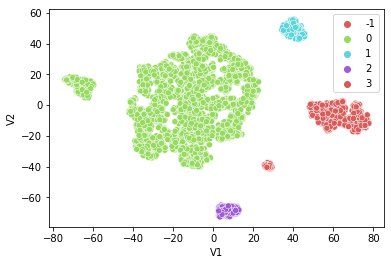


이런 방식의 클러스터링 결과는 지나치게 광범위한 결과로, 이를 이용하여 셀러 관리의 우선순위를 결정하는 것은 무리가 있었습니다.
이를 보완하기 위해 한 가지 클러스터링 과정에서 고객들의 행동 정보를 추가적으로 사용하기로 했는데요. 유저들이 한 세션 안에서 확인하는 상품 상세 목록과 셀러 목록을 매칭하여 세션 단위로 나타나는 셀러의 목록을 이용하였습니다. 이를 통해 셀러 간 유사도를 확인할 수 있었습니다.
이를 도식적으로 보면 무방향 그래프와 인접 행렬의 형태로 나타낼 수 있었습니다.
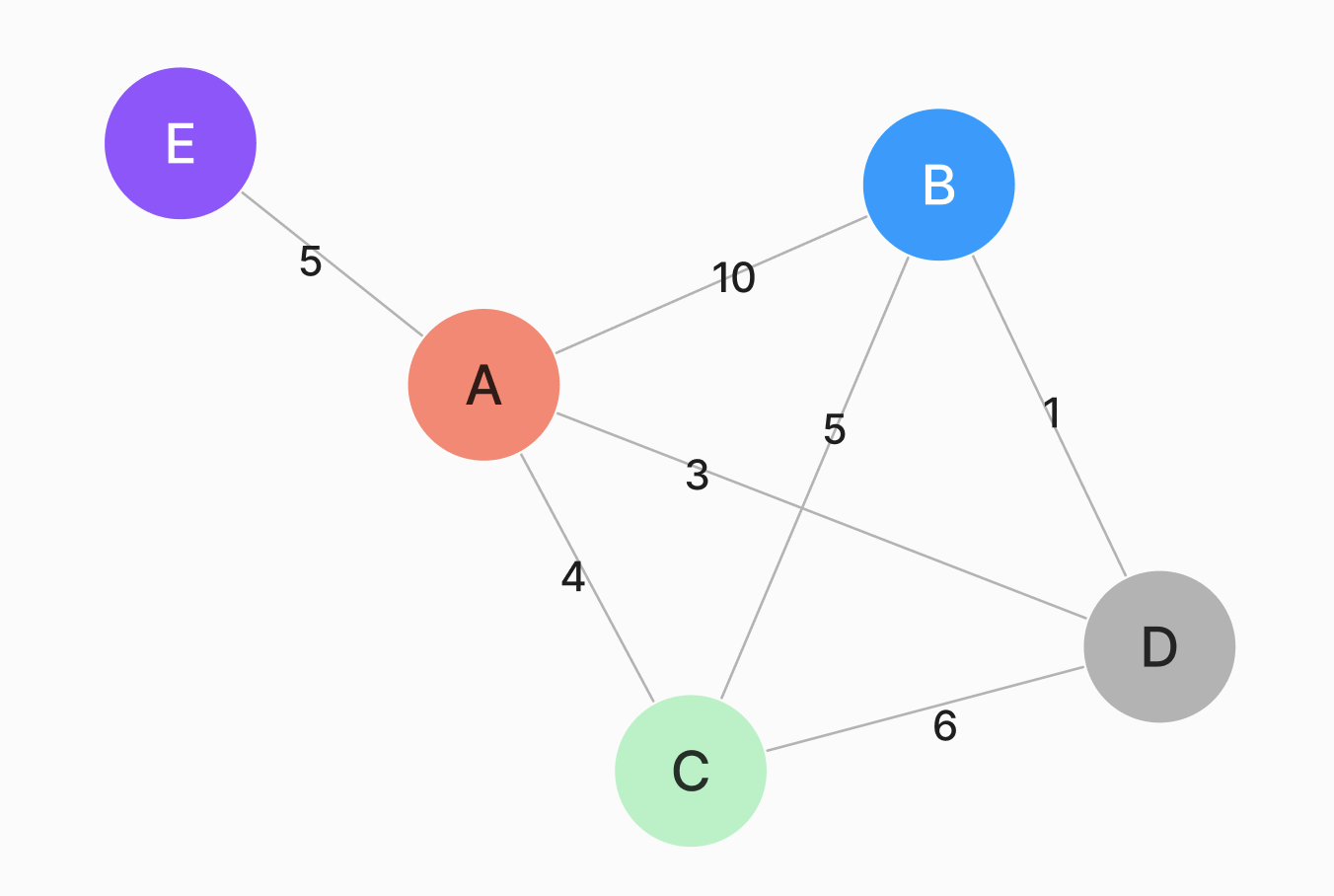
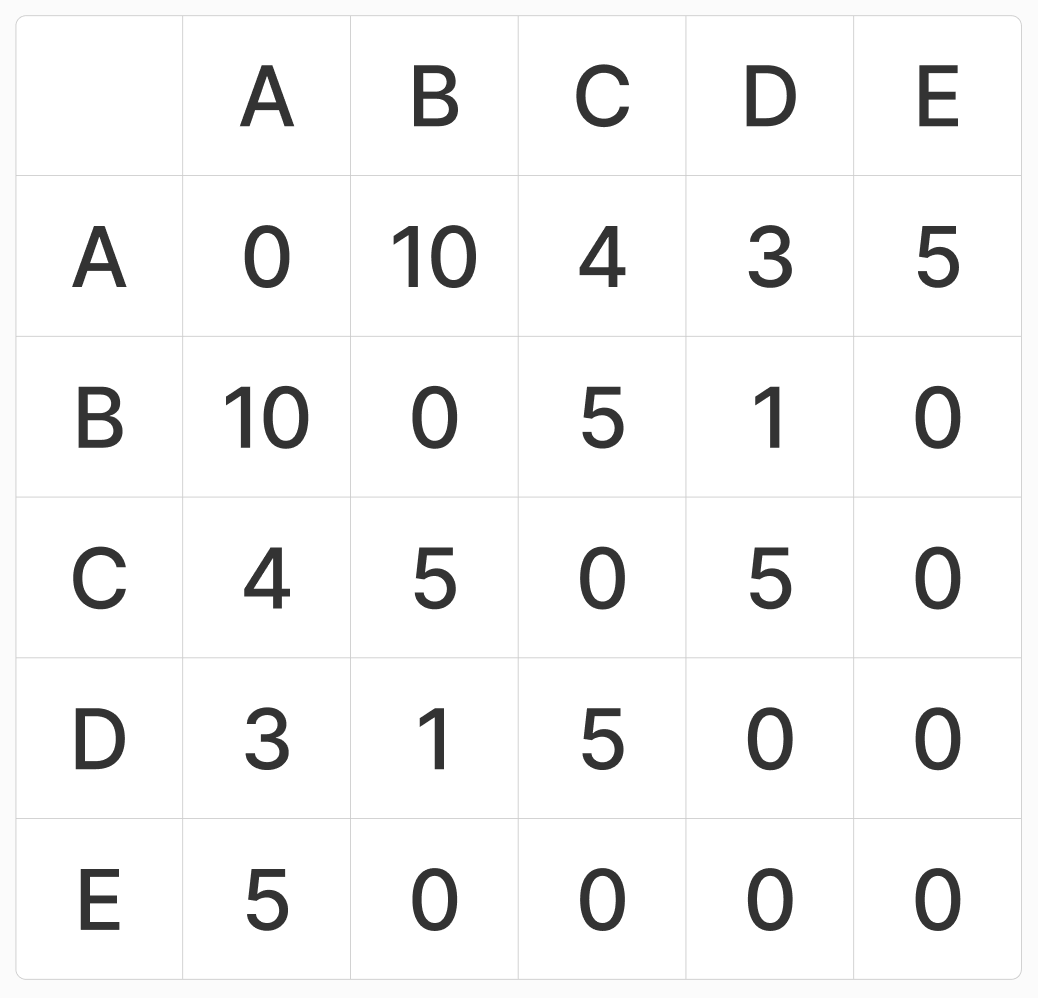
인접 행렬로 표현된 그래프는 스펙트럴 클러스터링이라는 방법을 통하여 또 다시 군집화가 가능합니다. 이는 간단히 말해 다른 노드와의 관계에 대해서 높은 차원으로 설명되어 있는 각각의 노드 정보들을 행렬 분해 방법을 통하여 낮은 차원으로 축소시키고, 그렇게 축소된 일종의 임베딩 값을 이용하여 군집화를 시도하는 방법입니다.
이 방법을 이용하면 인접행렬이 가지고 있는 각 노드(데이터포인트라고도 할 수 있겠습니다)들이 가지고 있는 서로에 대한 연관관계를 기반으로 클러스터링을 할 수 있고, 클러스터링 단계 이전에 얻어진 임베딩값은 셀러 간의 유사도를 필요로 하는 다른 여러 일들에서 사용될 수 있습니다.
고객 행동데이터를 이용한 셀러 임베딩값을 이용하면 셀러 클러스터링 과정에서 셀러에 대한 유저의 취향을 반영할 수 있고, 단순히 거래량과 판매 물품을 기준으로 한 구분보다 더 구체적으로 구분할 수 있다는 강점이 있습니다.
스펙트럴 클러스터링을 효과적으로 해 낸다는 것은 각 셀러의 관계적 특성을 잘 반영하는 임베딩 값을 잘 만든다는 것과 같습니다. 이를 위해서는 몇 가지 전처리 작업과 파라미터 튜닝이 필요한데요, 튜닝에 앞서 임베딩 값의 효과성을 측정할 수 있는 지표가 필요합니다.
실루엣 점수와 같은 지표로 비교할 수 있는 클러스터링 결과와는 다르게 임베딩 값의 판단은 해당 임베딩 값이 어떤 의미를 가지고 있고, 어떤 방식으로 사용되는지에 따라서 달라질 수 있습니다. 이번에 사용할 임베딩 값은 유저의 세션 안에서의 행동 데이터로 이루어져 있고, 셀러들이 한 세션 안에서 얼마나 서로 강한 관계를 맺고 있는지에 따라서 그 위치를 정의하기 위해서 개발한 것이므로 판단 지표는 실제 유저의 행동 상에서 임베딩 값이 가까울수록 세션 내에서의 ‘겹침’이 많은지의 정도로 정의하게 되었습니다.
구체적으로는 샘플링을 통해서 적당한 수의 셀러 번호를 확인하고, 해당 셀러에게 매칭되는 다른 셀러와의 ‘겹침 정도’와 임베딩 값의 유사도를 비교하는 지표를 산출한 후, 특정한 전처리 혹은 파라미터 튜닝을 진행한 경우와 진행하지 않은 경우의 지표 분포의 비교를 통해서 파라미터 튜닝결과와 전처리 방식의 효율성을 판단하게 되었습니다. 이 방법은 이후 임베딩 값이 실제 서비스에서 상용화 되었을 때에도 사용할 수 있는 것으로, 해당 지표의 등락을 기준으로 언제 임베딩값을 갱신할지 결정할 수 있게 될 것입니다.
전술한 지표를 기반으로 전처리 방식을 판단한 결과, 단순히 세션 내에서의 겹침 정도를 계수하여 인접행렬의 가중치로 사용하는 것 보다는 tf-idf 방식을 사용하여 가중치의 셀러 별 차이를 완화시킨 후 사용하는 것이 효과적인 것으로 확인되었습니다.
tf-idf method
tf-idf 방식은 원래 자연어 처리에서 사용되는 데이터 전처리 방법 중 하나로, 지나치게 많이 등장하는 표현의 중요도를 지나치게 높게 판단하는 것을 방지하는 방법입니다. 구체적으로는 다음과 같은 방식을 사용하는데요,
tf-idf 에서 각 단어의 중요도는 \(tfidf(t,d,D) = tf(t,d)*idf(t,D)\) 의 식으로 표현됩니다. \(tf(t,d)\) 는 t 라는 단어가 d 라는 문서에서 나타난 횟수를 의미하고 \(idf(t,D) = log\frac{|D|}{|\{d\in D:t\in d\}|}\) 는 한 단어가 전체 문서에서 얼마나 자주 나타나는가와 관련된 수치입니다. D 는 전체 문서의 수를 의미하고 분모의 값은 t 라는 단어를 가진 d 문서의 개수를 의미합니다. 따라서 t 단어가 적게 들어갈수록 해당 값은 커지게 되는데, 빈번하게 관찰되는 단어와 드물게 관찰되는 단어의 값 차이가 지나치게 크게 나타나는 것을 방지하기 위해서 log를 씌워줍니다. 단순히 단어가 빈번하게 등장한 정도인 ft 에 idf 라는 평준화 가중치를 곱해 준 형태로 생각할 수 있겠습니다.
위 방법을 셀러 별 유사도에 적용하게 되면, 특정 셀러 조합이 세션에 자주 등장하는 정도가 tf 가 되고, 전체 세션의 개수가 D가 될 수 있습니다. 이런 방식으로 가중치가 특정 셀러에게 지나치게 편중되는 현상을 방지합니다.
Searching K
마지막으로 spectral clustering 과정에서는 추출하는 고유값의 개수에 따라서 k-means 에 사용할 군집의 수가 달라지고 이에 따라서 임베딩 값의 차원 수도 달라지는데요, 고유값의 개수는 eigen-gap 이라는 지표를 이용해서 결정하게 됩니다. eigen-gap은 특정 행렬에서 고유값을 크기 순서대로 추출했을 때 각 고유값 간의 차이를 의미하는데요, 해당 고유값이 증가하는 정도가 더 이상 크게 뛰지 않는 지점에서 고유값이 인접 행렬의 특성을 상당 부분 반영했다고 볼 수 있다고 합니다. 따라서 이 문제는 충분한 수의 고유값과 고유벡터를 추출한 후에 eigen-gap 이 가장 큰 지점 이후로 결정할 수 있게 됩니다.
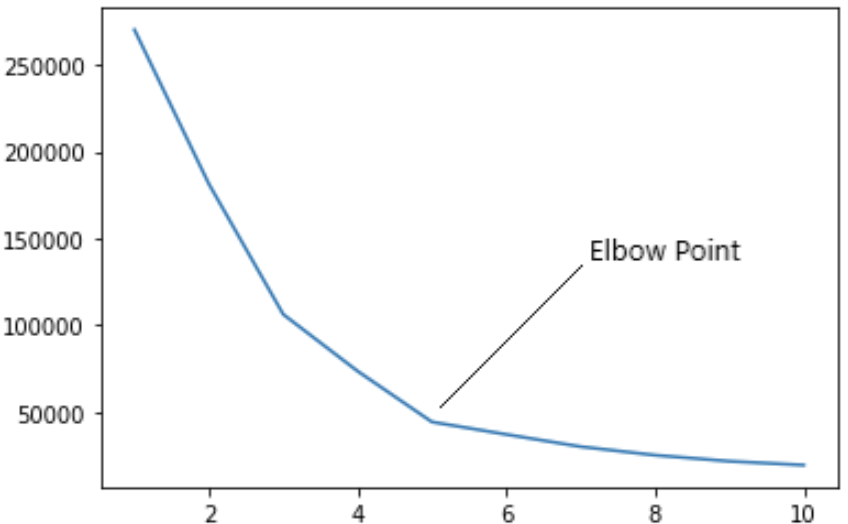
이렇게 얻은 임베딩 값을 기반으로 앞서 진행했던 셀러 클러스터링 작업을 다시 진행할 수도 있는데요, 기존에 사용했던 상품 카테고리, 거래액, hit rate 에 유저의 행동 데이터를 추가하여 더욱 세분화된 셀러 클러스터링을 가능하게 합니다.
Clustering Result
위의 방법들을 이용하여 얻은 임베딩 값을 이용하여 클러스터링을 다시 수행한 결과, 훨씬 세분화된 군집을 얻을 수 있었습니다.
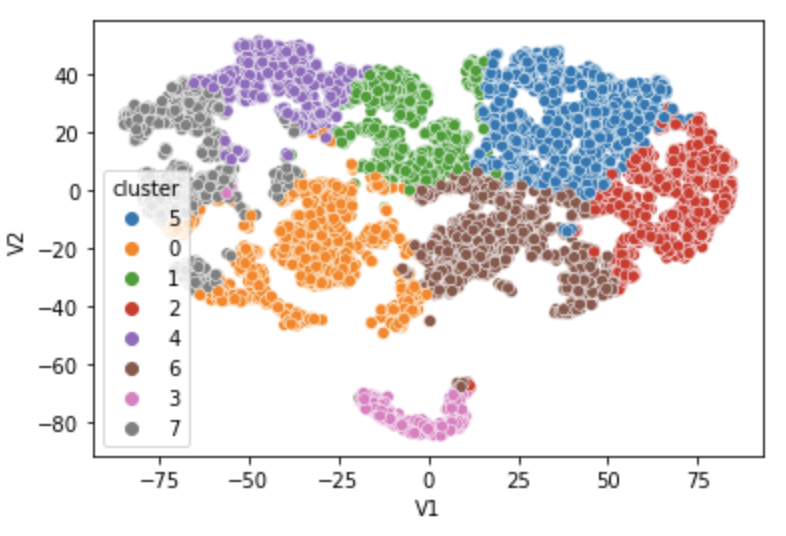
특히 이전에 단순 의류 판매자로 분류된 셀러들의 경우 판매하는 의류의 특징별로 구분이 더 효과적으로 되었음을 알 수 있었습니다.
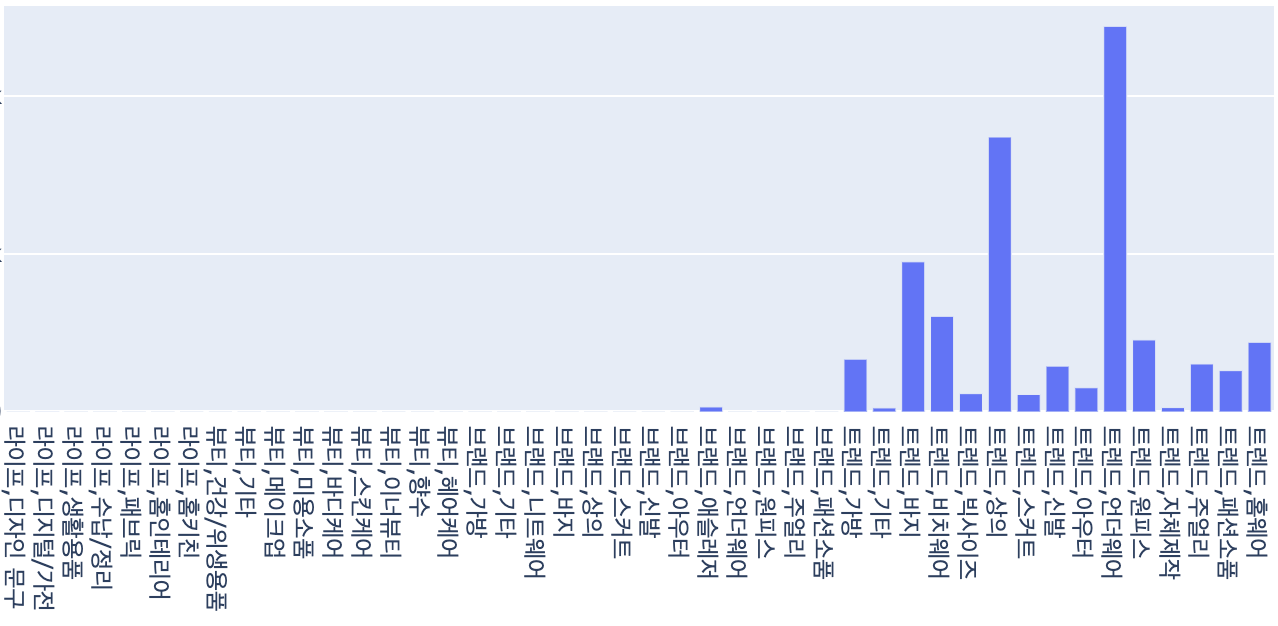
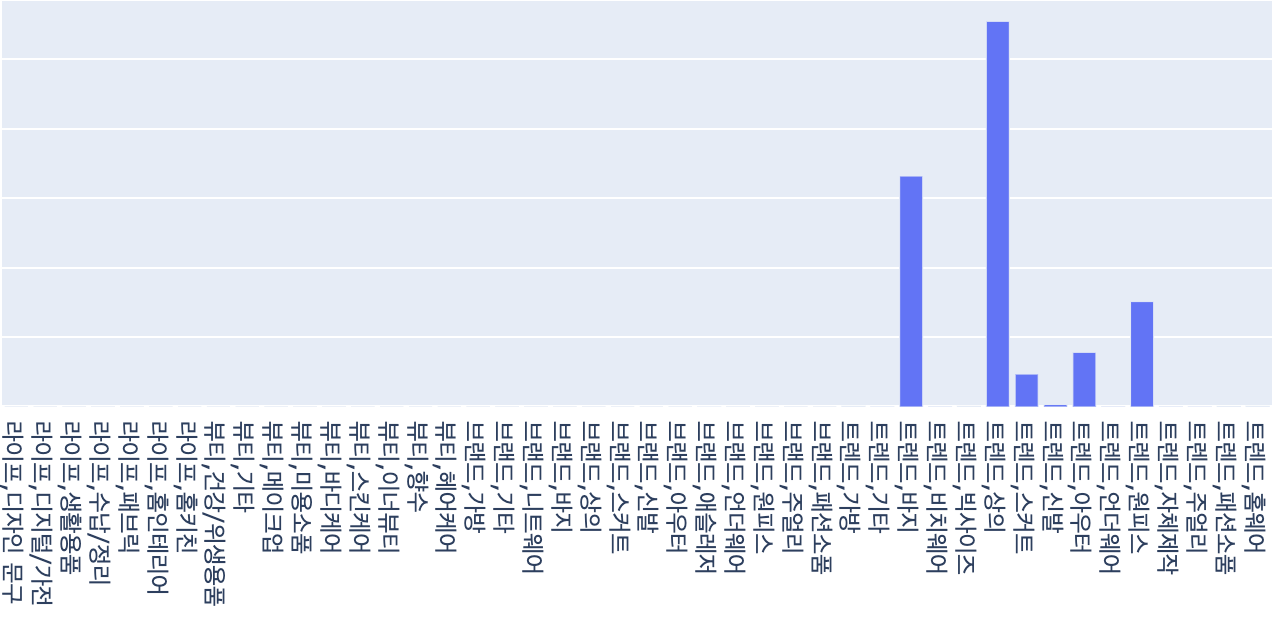
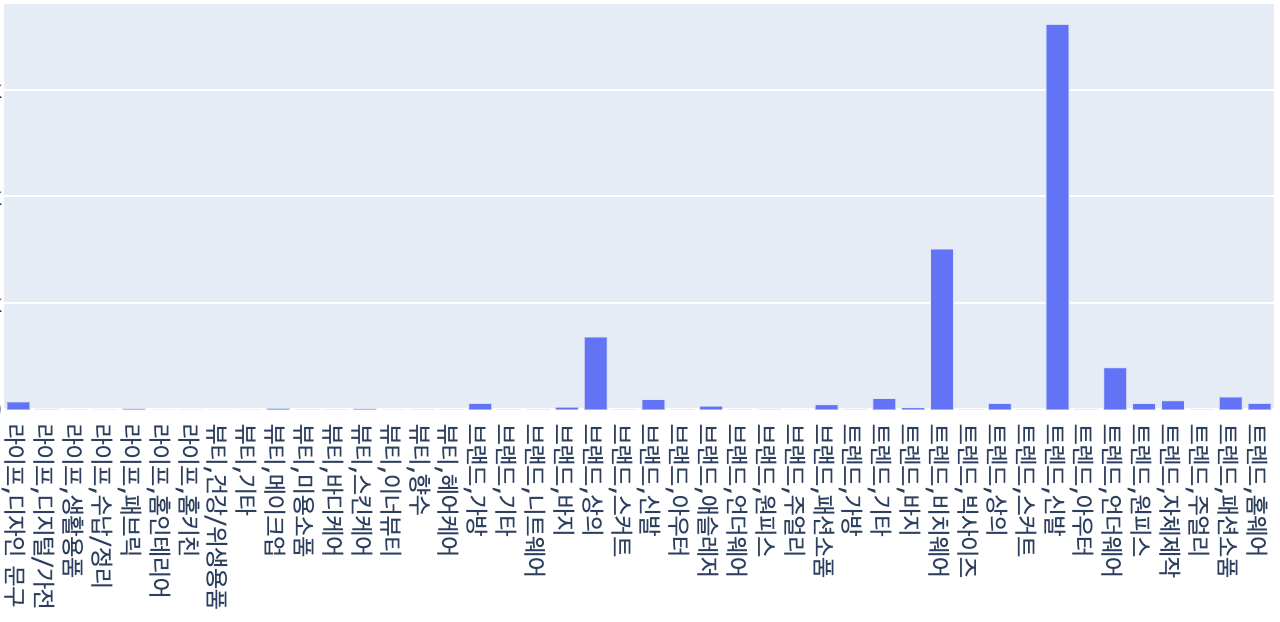
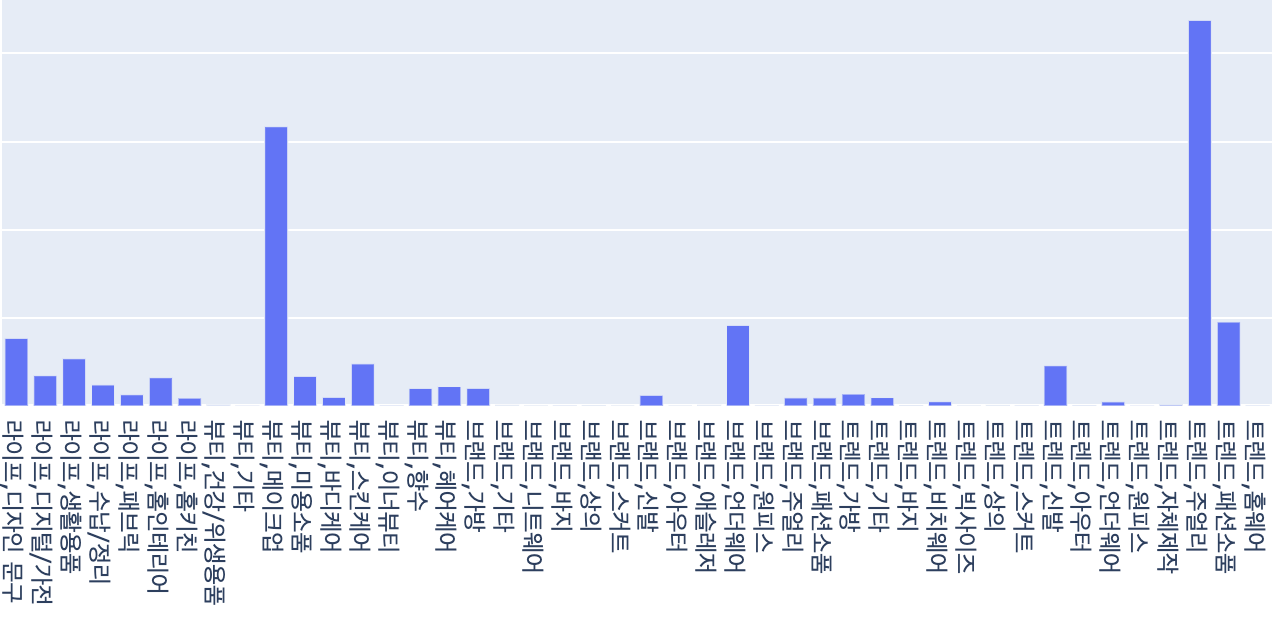
의류 판매자 중에서도 언더웨어와 비치웨어를 주로 판매하는 셀러와 상의와 바지 위주로 판매하는 셀러로 나눠지고, 신발을 주력으로 하는 셀러나 메이크업 용품을 주력으로 판매하는 셀러 등 보다 명확하게 셀러들을 분리해 낼 수 있었습니다. 또한 상의와 바지 위주로 판매하는 셀러의 경우도 스타일에 따라서 군집이 나눠지는 것을 확인할 수 있었습니다.
5. CRM 자동화 캠페인 적용 사례
앞의 셀러와 고객 분석에서의 RFM은 주로 EDA, 리포팅의 목적으로 사용되었습니다. 그러나 고객들을 분류하는 RFM framework의 특성 상 실제 프로덕트에서도 사용될 수 있는 여지가 있는데요. CRM 캠페인에서의 사용이 그 전형적인 예시입니다.
CRM 캠페인에서의 RFM framework 적용은 고객 군집이 어떤 특징을 지니는지를 확인하고 고객들의 segment 간 이동 패턴을 포착하는 것에 집중했으며, 실제 적용 과정에서 사용하는 AB test 방법 그리고 CRM 캠페인의 성과를 측정하는 방법을 고안하는 것을 중점으로 진행했습니다.
먼저 CRM 에 RFM 모델을 사용하기 이전에 전체 고객에 대하여 고객들을 나눈 군집이 실제로 구분을 잘 하는가, 그리고 군집간의 이동 중에 중요하게 고려해야 할 것은 없는지를 다시 한번 확인하는 작업이 필요했습니다. 사업부와의 협업에서는 명확하게 구별되는 VIP 고객군에 집중했다면, 이제는 RFM framework에 속하는 모든 고객군들에 대한 분석을 하게 되었고 이에 특정 군집 간에 발생하는 이동을 관찰하기 위해 sequential pattern mining 방법을 도입하였습니다.
prefixspan 방법은 다른 방법들에 비해 대용량의 데이터를 빠르게 처리할 수 있는 알고리즘을 사용했습니다. 이 과정에서 몇 가지 행동 패턴을 확인할 수 있었는데요, 먼저 기존에 구분한 frequency 기반의 분류가 유효하다는 것이었습니다. 대부분의 고객들은 처음에 시작한 frequency 레벨에서 특정 범위 밖으로는 움직이지 않았음을 확인할 수 있었고, 그렇게 구분된 frequency 간격은 앞서 EDA 를 통해 임의로 구분한 경계와 같았습니다.
또 recency 의 경우 또한 특정 범위 안에서의 이동이 관찰되었는데요, 이 말은 이동이 관찰되는 recency 의 범위가 고객들이 일반적으로 구매 후 재구매하는 기간과 같다는 것입니다. (왜냐하면 recency 는 구매의 최근성을 의미하므로, 구매하게 되면 recency는 다시 5점이 됩니다.) 이러한 관찰 결과를 기준으로 recency 기준의 고객 군집 분류 또한 재정의할 수 있었고, 그 결과로 처음에 보여드렸던 RFM framework를 정의할 수 있었습니다.
RFM framework 는 과거 구매를 진행한 고객들만을 대상으로 하기 때문에 CRM 캠페인 중 과거 구매자들을 대상으로 하는 캠페인을 개선하는 데 사용할 수 있었습니다. 개선의 목표는 크게 두 가지로 CRM 대상 고객의 증대(이 경우 새로운 대상 고객군들을 발굴하는 데 초점을 맞춘 목표)와 CRM 효율의 개선이었습니다.
효율 개선과 관련하여 가장 먼저 해야 했던 것은 CRM 캠페인의 성과 측정 방식의 정의입니다. 현행 방식은 과거 실험을 통해서 정의된 고객 군집을 그대로 사용하면서 해당 캠페인의 전환율만을 성과 지표로 사용하고 있었는데요. 이는 직관적인 방식이지만 실제 CRM 캠페인의 효과를 정확하게 측정하기 어렵습니다. 왜냐하면 대조군을 통해서 CRM 의 효과를 비교하지 않기 때문에 어떤 캠페인이 높은 전환율을 기록했을 때 그 전환율의 원인이 CRM 캠페인에 있는지 캠페인의 대상이 된 고객 군집의 특성에 있는지 확인할 수가 없기 때문입니다. 이러한 문제를 해결하기 위해 저희는 기존 전환율에 더해서 uplift modeling 방법에서 사용하는 성과 측정 방식을 적용하게 되었습니다.
uplift modeling 은 어떤 마케팅 캠페인의 대상자들을 해당 마케팅 캠페인 수신 후의 전환여부와 캠페인을 받지 않았을 때의 전환여부를 통해 고객을 크게 4가지 분류로 나눕니다.
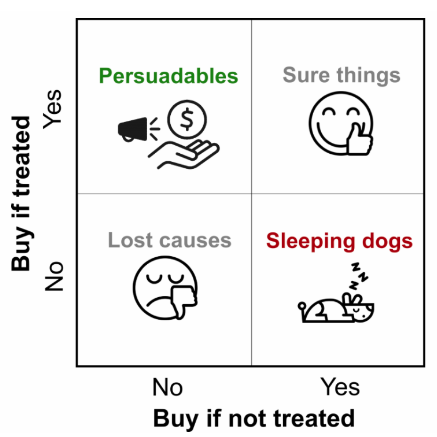
여기서 가장 중요한 고객 군집은 persuadables로 해당 군집은 캠페인을 받지 않았을 때는 구매하지 않고, 캠페인을 받았을 때에는 구매하는 ‘설득이 가능한’ 특징을 가집니다. CRM 캠페인의 진짜 효과는 “persuadables 군집의 고객들이 얼마나 터치되었고 해당 고객들이 얼마나 많이 전환되었는가”로 말할 수 있겠습니다.
저희는 이를 다음의 지표를 통해서 확인했는데요,
\[uplift~metric=\frac{transition~rate|user \in CRM}{transition~rate|user\notin CRM}, ~~user \in U_i\]같은 \(U_i\) 집합에 속하면서(같은 조건을 가지면서) CRM 캠페인을 받은 군집과 아닌 군집의 전환율의 비를 uplift metric 으로 정의하여 해당 지표가 1을 넘는 경우에 유의미한 효과를 일으켰다고 보았습니다.
위의 uplift metric 을 통해 기존 CRM 캠페인의 효율을 확인해 본 결과 대부분의 캠페인이 전환율은 높지만 uplift metric 은 낮은 상태였습니다. 또한 현행 캠페인의 대상 고객들이 모두 RFM framework 상에서 vip, promising, newcommer 군집에 속하는 바, 현재의 CRM 캠페인의 전환율은 대상 고객군의 특성에 의한 결과로 결론지었습니다.
이에 RFM framework 를 이용한 개선 방안은 아래와 같이 정리하였습니다.
- 새로운 군집을 발굴하여 터치되는 모수의 증대 - 기존에 vip, promising, newcommer 대상으로만 진행되는 CRM 캠페인을 다른 군집에 대해서도 확장.
- uplift metric 을 이용하여 효율이 좋지 않은 기존 캠페인 제거.
첫 번째 모수 증대 목적을 위해서 여러 번의 실험이 필요했습니다. 이 때 uplift metric을 계산하기 위해 브레이즈가 CRM 캠페인 대상자 별로 적용하고 있는 frequency cap 을 이용했습니다. frequency cap 이란 특정 push 캠페인을 고객이 수신하였을 때, 특정 시간동안은 다른 push 캠페인을 수신하지 못하게 함으로써 고객의 피로도 누적을 방지하는 기능입니다. 이를 이용해 특정 캠페인을 받은 뒤 유저의 2시간 동안의 행동은 다른 캠페인을 받지 못하므로 온전하게 특정한 캠페인의 영향을 확인할 수 있겠다고 생각했습니다.
마찬가지로, 현행 CRM 캠페인에 의해서 frequency cap 에 의해서 실험하고자 하는 CRM 캠페인의 대상자임에도 불구하고 CRM 캠페인을 수신하지 못하는 유저가 생길 수 밖에 없으며 해당 유저들을 대조군으로 설정할 수 있었습니다.
실험은 브레이즈를 통해서 실행하였고, 몇 번의 실험 이후 유의미한 군집을 확인할 수 있었습니다.
마케팅실 그로스파트원분들의 도움으로 타겟 군집, 랜딩 페이지, 소재, 문구를 완성하였고 앞서 말씀드린 지표를 통해서 효과적인 고객 군집을 선정할 수 있었습니다. 마찬가지로 기존에 적용하고 있던 CRM 캠페인 중 효과적이지 않던 캠페인의 제거 작업도 CRM팀과 함께 하였으며 그 결과로 몇 가지의 캠페인을 제거하였습니다.
새롭게 적용한 CRM 캠페인의 경우, 상용으로 진행되었을 때 주기적으로 갱신되는 RFM 점수를 파라미터로 받게 됩니다. 이 때 갱신되는 파라미터 값은 현재 AI 파트에서 구상하고 있는 자동화 CRM framework 상의 한 부분을 차지하게 됩니다. 이는 기존 CRM팀의 업무 부담 완화와 효율 개선을 목표로 합니다.
6. 자동화 CRM framework 에서의 RFM
현재 AI 파트에서 계획하고 있는 CRM 프로젝트는 크게 3가지 파트로 나뉩니다. 첫 번째는 앞서 설명한 자동화 캠페인, 두 번째는 개별 - 일회성 캠페인, 그리고 마지막으로 AI 파트의 순철님께서 작업하신 쿠폰 플레이 영역입니다. 쿠폰 플레이 영역은 이미 ML 모델이 도입되어 구매확률 기반의 쿠폰플레이가 이루어지고 있으며, 높은 효율을 기록하고 있는 상황입니다. 여기서의 RFM 은 자동화 캠페인 영역에서 framework 로의 역할과 쿠폰플레이에서의 ML모델에 feature 값으로도 사용되고 있습니다.
다음은 AI 파트에서 계획하고 있는 대략적인 자동화 캠페인의 아키텍처입니다.
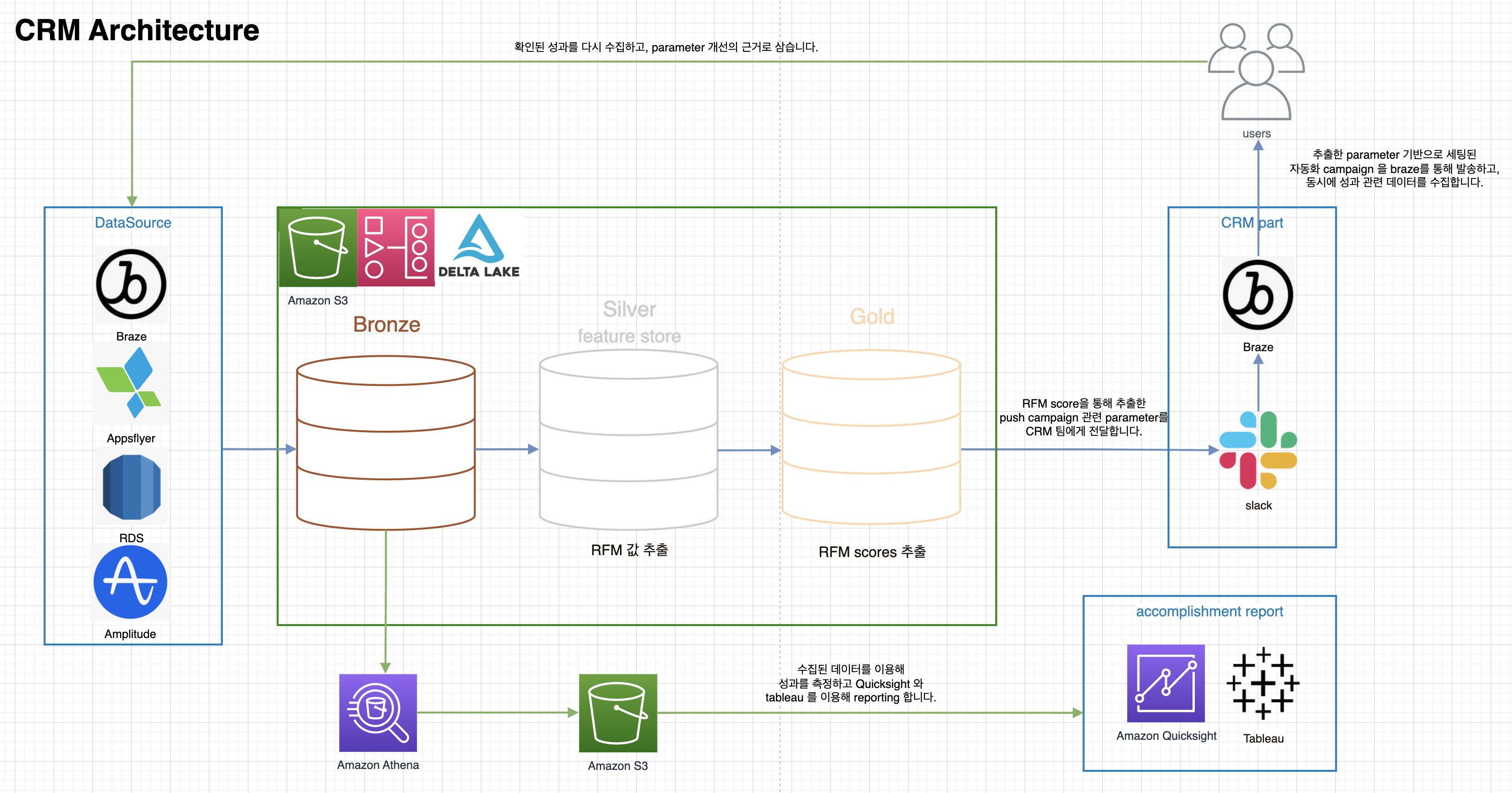
7. 맺음
RFM은 이와 같이 범용성 있게 사용될 수 있는 유용한 도구입니다. 고객을 구분해 내고, 특징지을 수 있는 변수 값을 만들어 낸다는 점에서 커머스 도메인에서 중요하게 사용되기도 합니다. 설명할 수 있는 범위의 한계가 분명하고, 개인화된 수준의 분석을 해내기는 어렵다는 단점이 존재하지만 이러한 단점을 보완할 수 있는 다른 분석 방법과 함께 사용되었을 때 좋은 효과를 내는 방법이라고 할 수 있습니다.
RFM 모델은 CRM 고도화, 고객 분석 방법의 baseline model이라고 볼 수 있습니다. 앞으로 더욱 개인화, 자동화된 모델들과 고도화된 분석 방법을 도입하여 CRM 캠페인을 개선하고 고객 분석을 통해 새로운 인사이트를 제공할 수 있을 것입니다.
PS.데이터 분석 과정에서 도움 주시고 조언해 주신 AI검색팀, 비즈니스 관점에서 적절한 피드백을 주신 기획팀, 그리고 협업 과정에서 CRM 캠페인 작업을 함께 해 주신 마케팅실 그로스파트에 감사드리며 글을 맺습니다.
참고한 글들
- prefixspan algorithm
https://webdocs.cs.ualberta.ca/~zaiane/courses/cmput695-04/slides/PrefixSpan-Wojciech.pdf
- spectral clustering
https://arxiv.org/pdf/0711.0189.pdf
https://gjkoplik.github.io/spectral_clustering/#proofs_with_2_clusters
https://pizzathief.oopy.io/spectral-clustering#32a54120-1899-483d-b92e-2bd73ac965a8
https://wkdtjsgur100.github.io/P-NP/
- DBSCAN
https://dl.acm.org/doi/10.1145/3068335
- RFM
https://clevertap.com/blog/rfm-analysis/
- uplifting modeling
https://ambiata.com/blog/2020-07-07-uplift-modeling/
Appendix
위에서 설명한 방법들에 대한 자세한 설명을 첨부합니다. 글에서 사용한 여러 가지 방법들의 작동 원리에 대해 궁금하신 분들을 위해 남겨 놓은 부분이니 궁금하시면 보고 가세요!
A. sequential pattern mining - prefixspan
Sequence data는 특정기간 동안 대상의 행동을 나타내는 선후관계가 있는 항목들의 집합입니다. Sequential pattern mining은 주어진 시퀀스들의 집합에서 완전한 빈발 부분 시퀀스 집합(complete set of frequent subsequences)을 탐색하는 방법입니다.
prefixspan은 sequence pattern mining algorithm 의 하나입니다. prefixspan algorithm은 깊이 기반 방식으로 대용량 데이터에 효율적인 방법입니다. 이는 특정한 threshold를 설정한 후, 기준을 넘지 못하는 sequence 를 제거해 나가는 식으로 연산을 수행하며, 이러한 특징 덕분에 대용량 sequence 데이터를 효율적으로 계산할 수 있습니다.
prefixspan 알고리즘의 원리는 다음과 같습니다.
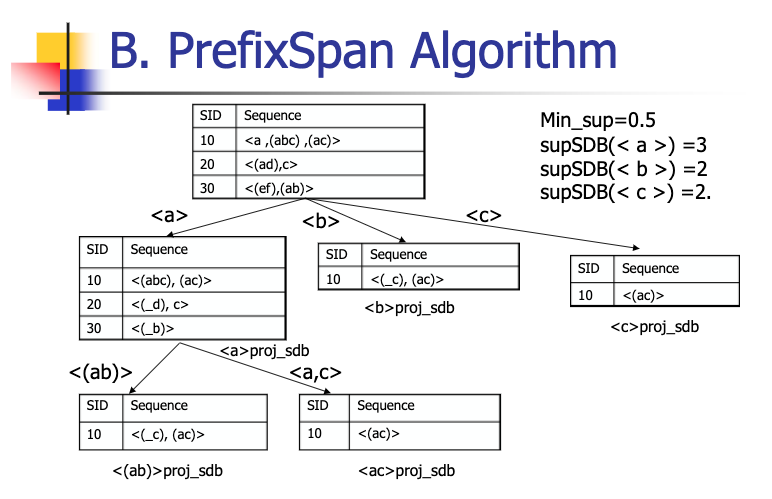
- sequence dataset 이 가지고 있는 각각의 element 를 기반으로 파생되는 dataset 을 구합니다.
- 각각의 dataset 을 대상으로 위의 과정을 반복합니다.
- 설정해 놓은 min support 를 넘지 못하는 pattern 들을 제거합니다.
- 위의 과정을 반복하여 실행하고, min support 조건 상에서 살아남은 패턴들을 집계합니다.
B. clustering method - spectral clustering
Laplacian matrix를 이용한 인접 행렬 구성
1. 그래프 형태로 표현되는 노드와 엣지를 인접 행렬 형태로 구성합니다. 이 과정에서 엣지 값의 정규화를 위하여 gaussian kernel 을 통과시킵니다.
- gaussian kernel
\(exp(\frac{-||x_i-x_j||^2}{(2\sigma ^2)})\) 으로 두 데이터포인트가 얼마나 떨어져 있는가를 정규분포 상에서 표준화하여 보여주는 방법입니다.
2. 그래프를 연결하는 방법(아래 방법 중 택 1)
- \(The~\epsilon - neighborhood~graph\): 특정 엡실론 값보다 작은 노드들만 연결하는 방법입니다. 연결의 강도를 나타내지는 못합니다.
- \(k-nearest~neighbor~graph\): 특정 노드와 k 만큼 가까운 노드만 연결하는 방법입니다.
- the fully connected graph: 모든 노드를 연결하는 방법입니다.
3. 위의 방법을 통하여 만들어진 인접 행렬의 특징
- \(\omega_{ij}≥0\) (i 와 j의 유사도에 따라서 더 큰 값이 부여됩니다.)
- \(\omega_{ii}=0\) (i 와 i의 유사도는 0으로 설정됩니다.)
- \(\omega_{ij}=\omega_{ji}\) (그래프는 무방향으로 해당 그래프의 인접 행렬은 대칭입니다.)
4. laplacian matrix 로의 변환
- laplacian matrix 는 위에서 구한 인접행렬을 적절하게 변환한 행렬의 형태로, 대각원소들이 0으로 표기되었던 인접행렬의 모습에서 각 행의 유사도를 합친 것을 대각원소의 자리에 넣어준 차수행렬에서 인접행렬을 빼 줌으로서 엣지와 노드의 정보를 모두 반영한 행렬로 생각할 수 있습니다. 구체적인 예시는 다음과 같습니다.
\(L=D-W\)
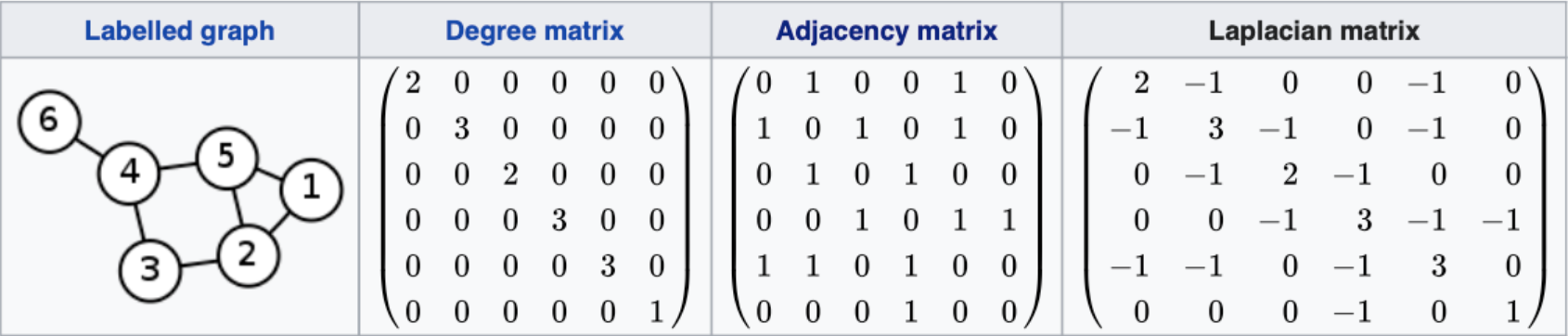
-
위의 식으로 표현된 laplacian 행렬은 unnormalized 된 graph laplacian 이라고 하는데, 이는 몇 가지 특징을 가지고 있습니다.
\(for~every~vector~f\in \boldsymbol{R}^n~we ~have ~ f'Lf=\frac{1}{2}\sum^{n}_{i,j=1}w_{ij}(f_i-f_j)^2\) \(\begin{align} f'Lf &=f'Df-f'Wf=\sum^n_{i=1}d_if^2_i-\sum^n_{i,j=1}f_if_jw_{ij} \\ &=\frac{1}{2}\left(\sum^n_{i=1}d_if^2_i-2\sum^n_{i,j=1}f_if_jw_{ij}+\sum^n_{j=1}d_jf^2_j\right) &=\frac{1}{2}\sum^n_{i,j=1}w_{ij}(f_i-f_j)^2 \end{align}\)L 은 대칭, positive semi-definite 합니다. (위의 정리는 항상 양수가 되기 때문입니다.) L의 가장 작은 eigenvalue는 0이고, 0에 대한 고유벡터는 \(\boldsymbol 1\) 입니다. (positive semi definite 한 행렬의 경우 그러합니다.)
\(f'Lf≥0\) 인데(모든 \(f\in \boldsymbol R^n\) 에 대해), 고유값을 구하는 식은 \(Av=\lambda v\) 이고, 이를 바꾸면 \(v'Av = v'(\lambda v) = v'v\lambda\) 이다. 따라서 \(v'Av=v'v\lambda≥0\) 이고 \(v'v ≥0\) 이므로 \(\lambda ≥ 0\) 일 수 밖에 없습니다.)
L은 n개의 non-negative 하고 real - valued eigenvalues \(0=\lambda_1≤\lambda_2≤...≤\lambda_n\) 를 가집니다. (n*n 크기의 정방행렬에 대한 고유값은 n 개가 존재합니다.) L의 고유값 0 의 중복도 k는 그래프 상에서 \(A_1,...,A_k\) 군집 안의 연결된 component 의 수와 같습니다. 고유값 0 의 eigenspace 은 indicator vectors \(\boldsymbol 1_{A_1},...\boldsymbol {1}_{A_k}\) 들에 의해서 span 됩니다. (여기서의 중복도는 0에 대한 고유벡터 안의 원소들의 중복도를 의미합니다.)
k=1 일때, f 가 고유값으로 0 을 가지는 고유벡터라고 합니다. 그럼 다음이 성립하는데,
\[0=f'Lf=\sum^n_{i,j=1}w_{ij}(f_i-f_j)^2\]이면, \(w_{i,j}≥0\) 임을 알고 있으므로, 만약 i,j 노드가 연결되어 있으면 \(f_i,f_j\) 가 같아야 합니다. 따라서 만약에 fully connected 된 graph 상이라면, f = 1 vector 여야 합니다.
이를 k 개의 connected component 로 일반화하게 되면, 연결된 component 마다 고유벡터의 각 component 값은 대칭적으로 같아야 합니다. L은 대칭행렬입니다. 그러므로 각각의 연결된 그래프 군집들을 클러스터링 한 것이 아니라 2번 방법으로 인접행렬을 구성했을 때 연결된 그래프 군을 의미합니다. 전체 Laplacian 행렬 안의 block diagonal matrix 로 표현할 수 있게 됩니다.
\[L = \begin{pmatrix} L_1 & & & \\ & L_2 & & \\ & & \ddots & \\ & & & L_k \end{pmatrix}\]\(0=f'Lf\) 이므로 벡터 f는 연결된 각 노드에 해당하는 부분마다 같은 값(상수)을 가지는 고유벡터의 형태를 띄어야 합니다.
그러면 L의 고유값은 \(L_i\) 들의 고유값의 union 이 되고, 고유벡터 또한 \(L_i\) 각각의 고유벡터에서 남은 부분은 0으로 채운 indicator 벡터들로 span 되는 고유벡터가 됩니다. 따라서 v의 statement가 증명됩니다. (111000, 000111 가 aaabbb 를 span 하는 것으로 생각할 수 있습니다.)
-
위의 laplacian 은 일반화하여 나타낼 수 있는데, 이를 normalized graph laplacian 이라고 합니다. 이는 두 가지의 형태가 존재하는데, 기존의 laplacian 에서 vertices 의 영향을 다른 vertices 와 같게 만들려는 목적으로 normalize 해 주기 위함입니다.
(평준화 정도로 생각할 수 있겠습니다.) \(L_{sym} = D^{-1/2}LD^{-1/2}=1-D^{-1/2}WD^{-1/2}\)symmetric 한 형태로, 기존의 laplacian 행렬에 차수행렬의 역행렬의 제곱근으로 quadratic form 을 만들어 준 것입니다.. 0으로 나누는 것을 방지하기 위해서 고립된 노드는 제외됩니다.
\(L_{rw}=D^{-1}L=I-D^{-1}W\) 논문에서는 random walk 와 관련되었다고 설명하는데, 이는 symmetric 하지 않은 normalizing 방법입니다. normalized laplacian 의 경우 unormalized 된 laplacian 보다 노드들의 degree 의 분산이 큰 경우 더 좋은 결과를 보입니다. normalized laplacian 또한 unormalized laplacian과 유사한 특성을 가집니다. \(f'L_{sym}f=\frac{1}{2}\sum^n_{i,j=1}w_{i,j}\left(\frac{f_i}{\sqrt{d_i}}-\frac{f_j}{\sqrt{d_j}}\right)^2\) \(\lambda\) 는 고유벡터 u를 가지는 \(L_{rw}\) 의 고유값입니다. if and only if, \(\lambda\) 는 고유벡터 \(w=D^{1/2}u\) 를 가지는 \(L_{sym}\) 의 고유값입니다. \(\lambda\) 는 고유벡터 u를 가지는 \(L_{rw}\) 의 고유값입니다. if and only if \(Lu=\lambda D u\) 의 generalized eigen problem을 풉니다.
(이 말은 비대칭행렬인 \(L_{rw}\) 의 경우에도 일반화 고유벡터를 구할 수 있고, 그렇게 구한 일반화고유벡터는 대칭행렬인 \(L_{sym}\) 에도 통용될 수 있다는 것을 의미합니다.)
0 는 고유벡터 1 을 가지는 \(L_{rw}\) 의 고유값입니다. 또한 고유벡터 \(D^{1/2}\boldsymbol 1\) 를 가지는 \(L_{sym}\) 의 고유값입니다. \(L_{sym}, L_{rw}\) 모두 positive semi definite 하고 n개의 non-negative real-valued erigenvalue \(0=\lambda_1≤\lambda_2≤...≤\lambda_n\) 를 가집니다. 또한, 두 행렬의 고유값 0에 대한 중복도 k 는 마찬가지로 \(L_{sym}, L_{rw}\) 의 연결된 군집 \(A_1,...,A_k\) 안의 연결된 원소들의 개수와 같다. 또한 \(L_{rw}\) 는 indicator vectors \(\boldsymbol 1_{A_i}\) 에 의해 span되고, \(L_{sym}\) 의 경우 \(D^{1/2}\boldsymbol 1_{A_i}\) 에 의해 span 됩니다.
5. 그래프로 표현된 각각의 노드들은 더 작은 그래프들로 분리할 수 있습니다. 이는 클러스터링 문제를 약간 바꾼 것으로 이해할 수 있습니다.
- 클러스터링 문제: 주어진 데이터포인트들은 군집으로 구분하되, 군집 내의 분산은 작게, 군집 간의 분산은 크게 만드는 최적의 기준을 설정하는 것.
- 변환된 문제: 그래프 상에서 표현된 노드들은 군집으로 구분하되, 같은 군집 안에 속한 노드들의 엣지의 가중치는 높게, 군집 간의 노드들의 엣지의 가중치는 낮게 하는 최적의 기준을 설정하는 것.
그래프 쪼개기
위에서 설명한 laplacian matrix 를 이용하여 변환된 문제의 형태로 그래프를 클러스터링 할 수 있습니다. 앞서 정의한 3개의 laplacian matrix 별로 3가지의 방법이 제시되는데요, 이 방법들은 모두 유사합니다. 아래에서 이번에 사용할 \(L_{rw}\) laplacian matrix 를 이용한 방법을 소개하겠습니다.
Normalized spectral clustering according to Shi and Malik (2000)
\(similarity~matrix=S\in\boldsymbol R^{n\times n}\), \(cluster~number=k\)
- 인접 행렬을 구성합니다. 인접행렬을 weighted adjacency matrix 로 만듭니다. (예의 gaussian kernel 과 같은 것을 이용합니다.)
- unnormalized laplacian L 계산합니다.
- 일반화 고유벡터인 \(u_1,...,u_k\) 를 계산합니다. 이는 \(Lu=\lambda Du\) 로 표현되는 generalized eigenproblem 문제를 해결함으로써 얻을 수 있습니다.
- \(U\in\boldsymbol R^{n\times k}\) 가 고유벡터 \(u_1,...,u_k\) 를 column 으로 가지는 행렬을 정의합니다.
- \(i=1,...,n\) 에 대해 \(y_i\in\boldsymbol R^{k}\) 가 \(U\) 의 i 번째 열로 정의합니다.
- \((y_i)_{i=1,...,n}\) 에 대해 k-means 알고리즘을 적용하여 \(C_1,....,C_k\) 개의 군집으로 나눕니다.
- output: \(A_i,...,A_k~~cluster~~with ~~A_i=\) \(\{j\mid y_i\in C_i\}\)
나머지 두 방식 모두 위의 방식과 유사합니다.
이 방식들은 공통적으로 data point \(x_i\) 를 \(y_i\in R^k\) 로 변환하여 클러스터링 하는 방식을 사용합니다. 더 구체적으로는 인접행렬을 고유벡터로 분해하는 것인데, 이를 위해서는 고유벡터에 대한 기하학적 이해가 선행되어야 합니다.
고유벡터는 기본적으로 임의의 행렬 \(A\)과 상수 \(\lambda\) 에 대해 \(Ax=\lambda x\) 를 만족하는 벡터를 의미합니다. 행렬은 공간상에서 벡터의 길이, 방향을 변환하는 연산으로 이해할 수 있는데, 고유벡터의 경우는 해당 행렬을 통과함에도 어떠한 방향 전환이 일어나지 않고 벡터의 길이만 달라지는 벡터를 의미합니다. 이를 다시 설명하면, 고유벡터는 행렬이 변환하는 방향과 같은 벡터라고 볼 수 있으며, 특정 행렬의 모든 고유벡터는 특정 행렬의 변환 방향을 각각 의미하고 있다고 볼 수 있습니다. 따라서 특정 행렬에서 고유벡터 몇 개를 뽑아 새로운 행렬로 만든 것은 해당 행렬의 변환 방향 몇 가지를 뽑아 유사하게 행렬을 구성한 것이라고 이해할 수 있겠습니다. 이는 다시 말해 위의 클러스터링 방식을 복잡한 인접행렬에서 행렬의 중요한 특징만 추출하여 클러스터링에 사용하겠다는 것과 유사하다고 볼 수 있습니다.
추가적으로 spectral clustering 과정을 graph cut 의 관점의 최적화 문제로 바라본 해석을 첨부합니다.
Graph cut point of view
위에서 이야기한 변환된 문제의 형태로 클러스터링을 이해하는 방법입니다.
유사도 그래프가 인접 행렬로 주어졌을 때, 가장 간단한 해결 방법은 클러스터링 문제를 mincut problem으로 푸는 것입니다. mincut problem 은 다음과 같습니다.
\(W(A,B)=\sum_{i\in A, j\in B}w_{i,j}\) 이고, \(\bar A = A^c\) 일 때 클러스터링은 다음을 최소화하는 문제와 같습니다.
- \[cut(A_1,...,A_k) = \frac{1}{2}\sum^k_{i=1}W(A_i, \bar A_i)\]
다시 말하면, 군집을 나누는데, 인접행렬상에서 각 군집간을 연결하는 가중치들의 합이 최소화되게끔 나눠야 하는 문제입니다.
그런데 위의 cut 은 지나치게 작은 군집을 만들어낼 수 있는 가능성이 있습니다. (단순히 가중치 합산 평균을 줄이면 되는 문제이므로) 따라서 대안적인 cut을 적용하였는데, 이는 다음과 같습니다.
- \[RatioCut(A_1,...,A_k) = \frac{1}{2}\sum^k_{i=1}\frac{W(A_i, \bar A _i)}{|A_i\vert}=\sum^k_{i=1}\frac{cut(A_i, \bar A_i)}{|A_i\vert}\]
- \[Ncut(A_1,...,A_k)=\frac{1}{2}\sum^k_{i=1}\frac{W(A_i, \bar A_i)}{vol(A_i)} = \sum^k_{i=1}\frac{cut(A_i, \bar A_i)}{vol(A_i)}\]
ratiocut 의 경우, 분모에 클러스터의 크기를 넣음으로써 지나치게 작은 - 불균등한(하나가 너무 크면 하나가 너무 작게 되므로) - 클러스터 구분을 보정합니다.
ncut 의 경우, 분모에 클러스터의 edge(클러스터에 속한 노드들의 가중치 합)들을 합산함으로써 ratiocut 과 마찬가지로 클러스터 구분을 보정합니다.
ratiocut 은 unnormalized spectral clustering 에 사용되고, ncut 은 normalized spectral clustering에 사용됩니다.
그러나, 이러한 mincut 문제는 NP hard 한 문제입니다. 쉽게 말하면 풀기 어렵다는 것이고, 어렵게 말하면 다음과 같습니다.
모든 NP 문제(비결정론적 튜링 머신으로 다항 시간 안에 풀어낼 수 있는 문제)를 다항 시간 내에 문제 A로 환원할 수 있다면, 문제 A는 NP hard 인데요, 문제 A를 문제 B로 환원가능하다는 것은 문제 B를 풀면 문제 A도 풀린다는 것입니다. 따라서 문제 B가 더 어려운 것이고, 이 개념을 NP hard 문제에 적용하면 NP hard 문제를 풀면 다른 모든 NP문제를 풀 수 있게 되는, 적어도 다른 NP문제만큼은 어려운 문제라는 것입니다.
어쨌든 결국 mincut 문제는 풀기 어려운 문제라는 것을 의미하며, 이를 relaxation 해야 합니다.
relaxation for k=2
두 개의 군집으로 그래프를 나눈다고 했을 때의 사례를 설명합니다. 해당 사례를 최적화 문제로 설명하면 다음과 같이 표현할 수 있습니다.
optimization problem: \(min_{A\subset V}RatioCut(A,\bar A)\)
이 때 벡터 f를 다음과 같이 정의합니다.
\[f_i= \begin{cases} \sqrt{|\bar A\vert/|A\vert}~~~~if~v_i\in A \\ \sqrt{|A\vert/|\bar A\vert}~~~~if~v_i\in \bar A \end{cases}\] \[f=(f_1,...,f_n)'\]따라서 f는 각 노드가 특정 군집 안의 포함 여부에 따라 2개의 값들 중 하나만을 원소로 가지는 벡터라고 정의합니다.
f 를 이용한 ratiocut objective function은 다음과 같이 변환됩니다.
\[\begin{align} f'Lf &=\frac{1}{2}\sum^n_{i,j=1}w_{i,j}(f_i-f_j)^2\\ &=\frac{1}{2}\sum_{i\in A,j \in \bar A}w_{ij}\left(\sqrt{\frac{|\bar A|}{|A|}}+\sqrt{\frac{| A|}{|\bar A|}}\right)^2+\frac{1}{2}\sum_{i\in\bar A, j \in A}w_{ij}\left(-\sqrt{\frac{|\bar A|}{|A|}} -\sqrt{\frac{|A|}{|\bar A|}}\right)^2\\ &=cut(A,\bar A)\left(\frac{|\bar A|}{|A|}+\frac{|A|}{|\bar A|}+2\right)\\ &=cut(A,\bar A)\left(\frac{|A|+|\bar A|}{|A|}+\frac{|A|+|\bar A|}{|\bar A|}\right)\\ &=\vert V\vert\cdot RatioCut(A,\bar A) \end{align}\]벡터 f는 n 개의 datapoint 로 구성된 인접행렬에서 n개의 엣지를 가지는 노드를 스칼라값으로 변환시킬 수 있습니다. 즉 해당 순서에 있는 노드는 특정 클러스터에 속하는지 여부에 따라 값이 이산적으로 다른 indicator 벡터입니다. 해당 벡터를 이용해 quadratic form으로 계산하면, laplacian matrix 이므로 항상 0보다 큰 결과를 얻습니다.
indicator vector f는 아래와 같이 전개할 수 있습니다.
\(\sum^n_{i=1}f_i=\sum_{i\in A}\sqrt{\frac{\vert\bar A \vert}{\vert A\vert}}-\sum_{i\in \bar A}\sqrt{\frac{\vert A \vert}{\vert\bar A\vert}}=\vert A\vert\sqrt{\frac{\vert\bar A\vert}{\vert A\vert}}-\vert\bar A\vert\sqrt{\frac{\vert A\vert}{\vert\bar A\vert}} = 0\) 으로, \(f\bot \boldsymbol 1\) 입니다.
\(\Vert f\Vert^2=\sum^n_{i=1}f_i^2=\vert A\vert\frac{\vert\bar A\vert}{\vert A\vert}+\vert\bar A\vert\frac{\vert A\vert}{\vert A\vert}=\vert\bar A\vert+\vert A\vert=n\) 이므로 mincut 문제는 다시,
\(min_{A\subset V}f'Lf~subject ~to ~f\bot \boldsymbol 1,f_i,~~\Vert f \Vert=\sqrt{n}\) 으로 바꿀 수 있습니다.
그러나 아직 f 의 이산성이 유지되고 있기 때문에, 해당 문제는 여전히 NP hard 문제입니다. 그러나 f 벡터의 원소들에 반드시 둘 중에 하나의 값만을 가져야 한다는 이산성 조건을 제거하면, 위의 문제는 NP hard 문제에서 definite 한 답이 있는 문제로 변화합니다. (이는 어떠한 최적화 문제에 있어서 조건을 없애면 feasible한 값이 최소한 같거나 늘어난다는 아이디어에 의한 것입니다.)
Rayleigh-Ritz theorem에 의해서 위의 최적화 문제의 답 f 는 L 행렬의 두 번째로 작은 고유값에 대응하는 고유벡터가 됩니다. 이는 Rayleigh-Ritz theorem 에 대해 알아야 하는 문제이며, 간략하게 설명하자면 다음과 같습니다.
Rayleigh-Ritz theorem
\(R(x)=\frac{x^HAx}{x^Hx},\Vert x \Vert ≠0\) 이라고 할 때, (H는 conjugate transpose 이고 행렬 A는 대칭행렬입니다.)
(\(R(x)\) 를 다시 풀어서 보면 \(Ax\) 와 \(x\) 의 비율이라고도 볼 수 있고, 이는 결국 행렬 A에 의해 벡터 X가 얼마나 길거나 짧아지는지에 대한 비율이 됩니다.)
\(\lambda_{min}=min_{\Vert x \Vert ≠0}R(x)≤R(e_i)≤max_{\Vert x \Vert ≠0}R(x)=\lambda_{max}\) 입니다.
이를 다시 풀이하면, 어떠한 행렬로 인한 벡터의 길이 변화의 범위는 고유값 내에서 정해진다는 것입니다.
(해당 정리를 벡터 X 에서 행렬 H 로 일반화할 수도 있습니다. 이는 \(Tr(H^TLH)\) 의 값들의 범위를 구하는 문제로 확장할 수 있습니다. 이 경우 가장 작은 고유값들에 대응하는 벡터들로 만든 H 행렬이 답이 될 것입니다.)
Relaxation arbitrary k
임의의 k개의 군집으로 나눈다고 했을 때의 사례를 설명합니다.
이 경우는 이산적인 벡터의 정의를 다르게 합니다. 노드의 정보를 변환하는 벡터를 \(h_j=(h_{1,j},...,h_{n,j})'\) 라고 정의하고 이러한 벡터들로 이루어진 행렬들을 H행렬로 정의합니다. 행렬의 각 원소는 다음과 같은 이산적인 정의를 가집니다. (indicator vector의 역할을 하게 됩니다.)
\[h_{i,j}=\begin{cases} 1/\sqrt{|A_j|}~~~~if~v_i\in A_j\\ 0~~~~~~~~~~~~~~~~otherwise \end{cases}~~~~~(i=1,...,n;j=1,...,k)\]해당 indicator vector 들을 칼럼으로 가지는 행렬은 다음과 같은 정의를 가집니다. \(H\in\boldsymbol R^{n\times k}\)
또한 행렬 H는 orthonormal 하면서 동시에 다음과 같은 특성을 가집니다.
\[h_j^TLh_j=\frac{1}{2}\sum_{i,j}w_{ij}(h_j(i)-h_j(j))^2\]이는 앞서 \(f^TLf\) 의 특성에서 쉽게 유도할 수 있습니다. 또한 h의 정의에 의해 \(i,j\in A_j\) 거나 \(i,j\in \bar A_j\) 이면 \(h_j(i)-h_j(j)=0\) 이 됩니다. 따라서 \(h_j^TLh_j\) 는 다음과 같이 바꿔 쓸 수 있습니다.
\[\begin{align} h_j^TLh_j &=\frac{1}{2}\sum_{i\in A_j,j\in \bar A_j}w_{ij}(h_j(i)-0)^2+\frac{1}{2}\sum_{i\in A_j,j\in \bar A_j}w_{ij}(0-h_j(j))^2\\ &=\frac{1}{2}\sum_{i\in A_j,j\in \bar A_j}w_{ij}(\frac{1}{\sqrt{|A_j|}})^2+\frac{1}{2}\sum_{i\in A_j,j\in \bar A_j}w_{ij}(-\frac{1}{\sqrt{|A_j|}})^2\\ &=\frac{1}{2}(\frac{1}{|A_j|})\cdot cut(A_j)+\frac{1}{2}(\frac{1}{|A_j|})\cdot cut(\bar A_j)\\ &=\frac{cut(A)}{|A_j|} \end{align}\]따라서 \(h_j^TLh_j=\frac{cut(A_j, \bar A_j)}{\vert A_j \vert}\) 로 쓸 수 있습니다.
또한 다음의 특성도 가집니다.
\((H^TLH)_{jj}=h_j^TLh_j\) (trace 를 의미합니다.)
위에서 나열한 두 가지의 특성에 의해 ratiocut은 \(RatioCut(A_1,...,A_k) = Tr(H^TLH)\) 로 쓸 수 있습니다.
\[\begin{align} Tr(H^TLH) &=\sum ^k_{j=1}(H^TLH)_{jj}\\ &=\sum^k_{j=1}(h_j^TLh_j)\\ &=sum^k_{j=1}\frac{cut(A_j)}{|A_j|}\\ &=RatioCut(A_1,...,A_k) \end{align}\]따라서 mincut 에 관한 최적화 문제는 다음과 같이 만들어 낼 수 있습니다.
\[min_{A_1,...,A_k}Tr(H'LH)~subject~to~H'H=I\]또한 H의 이산성을 완화하면 다음과 같이 최적화 문제를 만들어 낼 수 있습니다.
\[min_{H\in \boldsymbol R^{n\times k}}Tr(H'LH)~subject~to~H'H=I\]앞서 Rayleigh-Ritz theorem 을 일반화하여 \(H'LH\) 의 대각원소에 각각 적용시키면 행렬 H의 column을 구성하는 고유벡터들은 0을 제외한 k번째로 작은 고유벡터에 대응하는 고유벡터임을 알 수 있습니다.
Approximating Ncut
ratiocut 을 이용한 위의 방법들은 unnormalized laplacian 을 사용할 때의 방법입니다. (가장 작은 eigenvalue = 0, eigenvector = 1 일 때)
ncut 을 이용하면 normalized laplacian 을 이용한 방법을 graph cut point of view 로 설명할 수 있습니다. 유도 과정은 위의 방법과 매우 유사합니다. 유일한 차이점은 laplacian matrix 가 normalized 되어 있다는 것이고, 그 때문에 고유값과 고유벡터의 값이 다르다는 것입니다.
여기서는 실제로 random walk laplacian 을 사용하여 k개의 cluster로 구분하는 과정을 유도합니다.
\[h_{i,j}=\begin{cases} 1/\sqrt{vol(A_j)}~~~~if~v_i\in A_j\\ 0~~~~~~~~~~~~~~~~otherwise \end{cases}~~~~~(i=1,...,n;j=1,...,k)~~~~~~~~~~~~~~vol(A_j)=node의~가중치~합\]로 정의된 h vector 들로 이루어진 행렬 H는
\(H'H=I\) 이며 \(h_i' Dh_i=1\) 인 특징을 가지고 있습니다.
위의 정리에 따라 다음의 문제를 최적화할 수 있습니다.
\[min_{A_1,...,A_k}Tr(H'LH)~subject~to~H'DH=I\]그리고 H의 discreteness condition 을 완화하고 \(T=D^{-1/2}H\) 를 나누게 되면, 이는 다음의 최적화 문제로 변화합니다.
\[min_{T\in \boldsymbol R^{n\times k}}Tr(T'D^{-1/2}LD^{-1/2}T)~subject ~to~T'T=I\]해당 문제는 위에서 확인했던 trace 의 최소화 문제가 되므로, ratio cut 을 사용한 최적화 문제와 같은 방식으로 풀 수 있습니다.
C. clustering method - DBSCAN
DBSCAN = density-based algorithm for discovering clusters in large spatial databases with noise
DBSCAN Algorithm
pseudo code 로 작성된 알고리즘은 다음과 같습니다.

DBSCAN 방법은 2가지의 파라미터만을 고려합니다.
\(\epsilon\) 으로 표기되는 radius 와 \(minPts\) 로 표기되는 Density threshold 입니다.
radius 는 반경의 크기를 의미합니다. 이는 데이터포인트 간 거리가 얼마나 가까워야 연결되었다고 고려할지에 대한 값입니다.
Density threshold 는 군집의 최소 크기를 의미합니다. 이는 최소한 몇 개의 데이터포인트가 모여야 최소한의 군집으로 인정할지에 대한 값입니다.
의사코드를 따라가면서 확인해 보면,
- DB 안의 임의의 데이터포인트를 선정합니다.
- 기존에 설정된 distance function(거리 metric 입니다.)을 이용하여 선정된 데이터포인트와 다른 데이터포인트 간의 거리를 확인하고, 조건에 따라서 p 주변의 점들을 neighbor 군집에 할당합니다.
- 만약 확인된 neighbor 의 크기가 Density threshold 보다 작게 되면, 해당 군집은 noise 로 정의합니다.
- 확인된 neighbor 이 Density threshold 보다 크면, 해당 neighbor 군집에 cluster label (c)을 부여합니다.
- 앞서 정의한 neighbor 군집에서 현재 점 p를 제외한 N을 S에 할당합니다.
- S에 할당된 데이터포인트에 대하여,
- noise 로 표기되었으면(주변에 neighbor 가 충분히 없다면) cluster c에 해당 데이터포인트를 할당합니다.
- 주변에 neighbor 가 Density threshold 를 넘어설 만큼 있다면 해당 데이터포인트 주변의 데이터포인트 또한 neighbor 군집에 포함하고, cluster c에 해당 데이터포인트를 할당합니다.
- 이렇게 만들어진 neighbor 군집을 S 집합과 합치고 이를 6번 반복합니다.
이 과정의 1~5번을 통해 정의된 클러스터에 대한 확장이 발생합니다.
DBSCAN 방법은 클러스터링을 진행하고자 하는 변수들의 분포를 잘 알지 못할 때 유용하게 사용할 수 있습니다. k means 와는 다르게 미리 군집의 개수를 지정해 줄 필요가 없기 때문입니다. 또한 spectral clustering 방법과 유사하게 밀도를 기반으로 하기 때문에 데이터의 분포가 둥글지 않은 경우, k means 방법에 비해 더욱 효과적으로 클러스터링 할 수 있다는 장점이 있습니다.
윤현석 | 랩스본부 앱스랩유닛 ML팀



