돈이 되는 Data Analytics
최정현
2024-03-04
안녕하세요, Tech Data AI검색 소속 데이터 분석가 최정현입니다.
지난해 말부터 커머스 유저 데이터를 분석 및 지표를 기획하고 대시보드로 자동화 하는 업무를 진행하였습니다. 이를 통해 추가적인 수익을 얻게 되었고 데이터를 통한 최적화 방향을 잡을 수 있었습니다.
Databricks와 AWS 서비스를 활용한 데이터 파이프라인 설계 및 고도화 부분은 해당 작업을 맡아주셨던 같은 팀 권순철님이 작성해주셨습니다.
먼저 대시보드를 만들게 된 계기와 구체적인 지표 선정 작업을 공유드려요. 그리고 Databricks와 AWS 서비스를 활용한 데이터 파이프라인 설계 과정과 대시보드의 임팩트 그리고 개선할 점으로 글을 구성했습니다.
🏐 들어가며
지난 11월, 브랜디 서비스는 메인페이지 추천 및 비즈니스 로직에 대한 실험을 진행했습니다. 그 결과, 실험을 진행한 조닝*에서 실험 집단이 통제 집단에 비해 압도적인 거래량을 발생시켰지만 실험 대상이 아닌 타 조닝에서 통제 집단이 실험 집단에 비해 높은 거래액을 발생시켰어요. 결국 상쇄된 거래액으로 인해 기존의 상품 진열 비즈니스 로직을 제거하지 않는 방향으로 결론이 났습니다.
*조닝: 상품이 전시되는 영역
해당 실험의 결과를 좌우한 핵심 지표는 ‘거래액’이었지만, 저희 팀은 이커머스 맥락에 맞춰 AARRR 지표를 위주로 추적하며 유저의 서비스 이용 과정에서의 어떤 차이가 해당 조닝에 대한 거래액 차이를 만들어냈는지 원인을 파악하는 작업을 진행했습니다.
여기서 AARRR이란, 사용자의 서비스 이용 여정을 다섯 단계로 나누어 분석하는 프레임워크입니다. Activation(고객 획득), Activation(활성화), Retention(재방문율), Revenue(수익률), Referral(추천)으로 구성되어 있습니다.
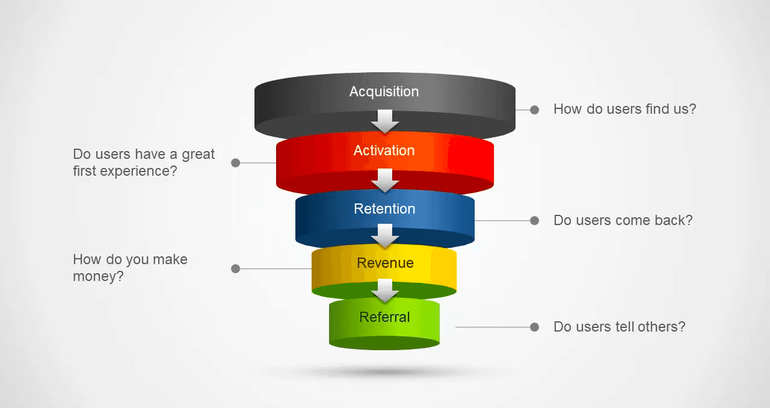
아래로 갈수록 사용자의 비율이 줄어드는 깔대기 모양으로, 더 많은 사용자를 각 단계에서 그 다음 단계로 전환시키는 것을 목적으로 합니다. 궁극적으로는 사용자가 해당 서비스를 더 적극적으로 이용하고 더 많은 수익을 창출하는 건강한 사용자 여정을 만들고자 하는 것이죠. 해당 실험에서는 이 중에서도 Activation, Retention, Revenue 관련 지표를 개발하여 실험 결과를 측정했습니다.
실험 기간인 한 달 간, 아래와 같이 매일 아파치 스파크를 활용하여 지표를 수동으로 추출 및 실험 리포트를 작성했는데요. 이 과정에서 실험 이후에도 해당 지표를 꾸준히 추적할 필요를 느꼈습니다. 따라서 해당 작업을 자동화하고 더욱 세밀한 AARRR 분석을 위해 대시보드 작업을 시작하였습니다.

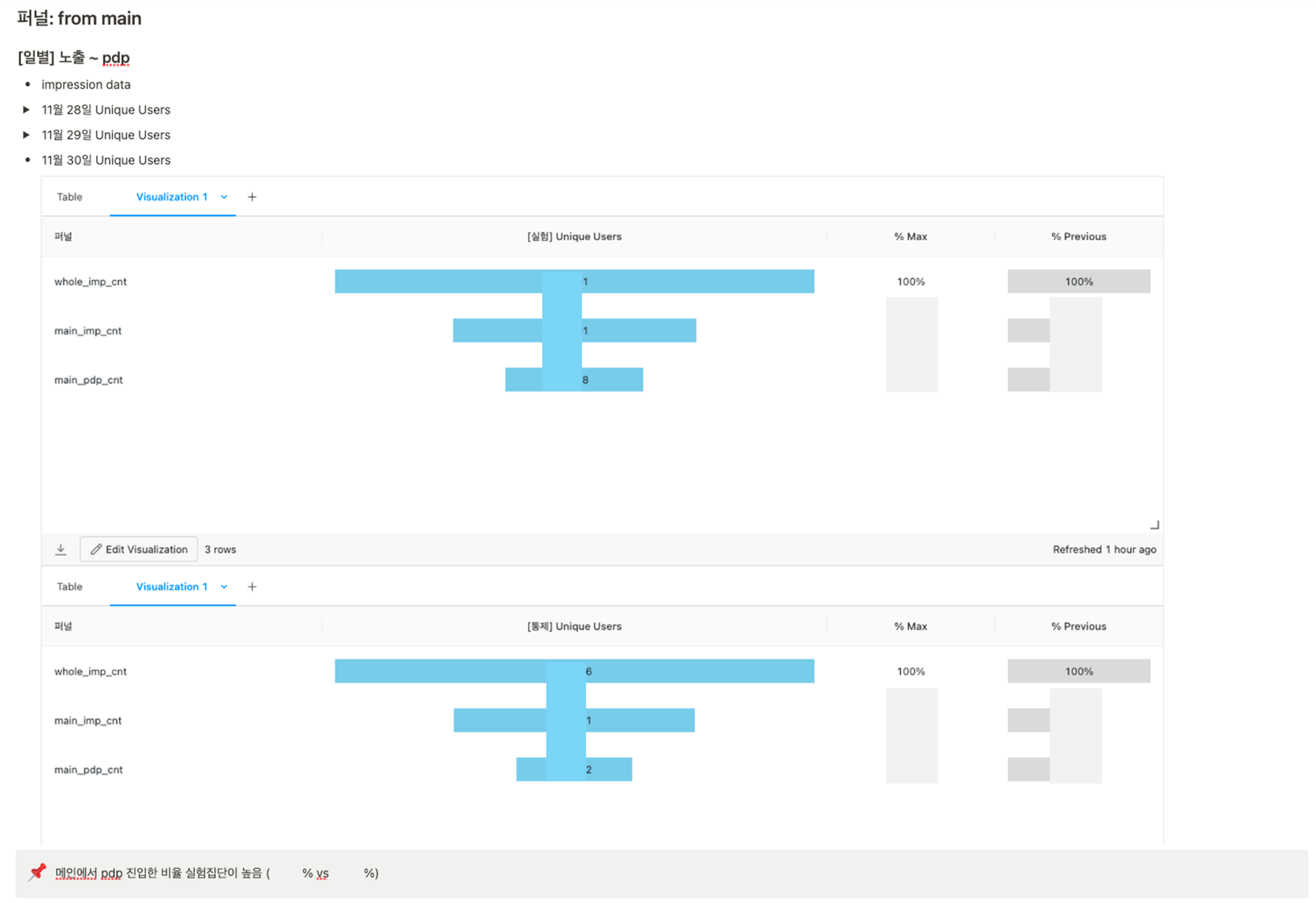
🥎 기존 고객 이탈을 방지하기 위한 AR 대시보드
이전에는 대시보드가 없었나요?
기존 태블로 대시보드가 존재했습니다만,
(1) 다양한 차트와 대시보드가 산발적으로 존재해 서비스의 현황을 한눈에 진단하기 어려웠습니다.
(2) 사업부의 요구사항에 따라 그때 그때 필요한 내용을 작성한 경우가 많아, 데이터 분석가가 서비스를 바라보는 관점은 포함되지 않았습니다.
(3) 대부분 거래액과 같은 ‘결과 지표’ 위주로 집계하는 방식으로 작성되어 있었으며 ‘선행 지표’인 플랫폼 내부의 유저의 여정에 대한 지표는 따로 확인하고 있지 않았습니다.
요컨대, 데이터 분석가의 관점을 반영해 필요한 지표를 통합하여 서비스의 현재 상태를 통합적으로 볼 필요가 있었습니다. 단순 결과 지표 뿐 아니라 이에 선행하는 ‘선행 지표’를 추적함으로써 서비스 유저 여정의 단계별 현황을 파악하고 유저가 겪는 문제를 진단하는 것이 시급했지요.
새로운 대시보드는 무엇을 보여주나요?
좋은 대시보드는 데이터 분석가가 서비스를 바라보는 관점, 대시보드 독자에게 전하고자 하는 주장이 스토리라인으로 명확히 담겨있어야 합니다. 새로이 기획할 대시보드에 이를 반영해야 했지요.
이전 실험 결과에 더불어 거래액 등 주요 결과지표의 흐름을 봤을 때, “기존 고객이 지속적으로 높은 비율로 이탈하는 것”이 서비스가 당면한 문제라는 결론을 내릴 수 있었기에 대시보드의 관점을 다음과 같이 설정하였습니다.
왜 Activation과 Retention이죠?
AARRR 중에서도 가장 중요한 것은 Activation과 Retention입니다. 아무리 고객을 새로 유입시켜도 고객의 활동성이 높아지고 리텐션이 낮아지면 결국 밑빠진 독처럼 구매 전환으로 가는 고객의 비율이 높아지기 어렵기 때문입니다. 따라서 고객의 이탈을 막기 위해 독의 밑바닥을 채우기 위해서는 Activation과 Retention 단계에서의 지표 개선이 이루어져야 합니다.
뿐만 아니라 이미 Revenue로 대표되는 ‘결과 지표’들은 충분히 다른 팀에서도 많이 보고 있었기에 아직 사내에서 제대로 확인하지 않던 Activation과 Retention을 위주로 지표를 선정했습니다.
구체적으로 어떤 지표를 작성했나요?
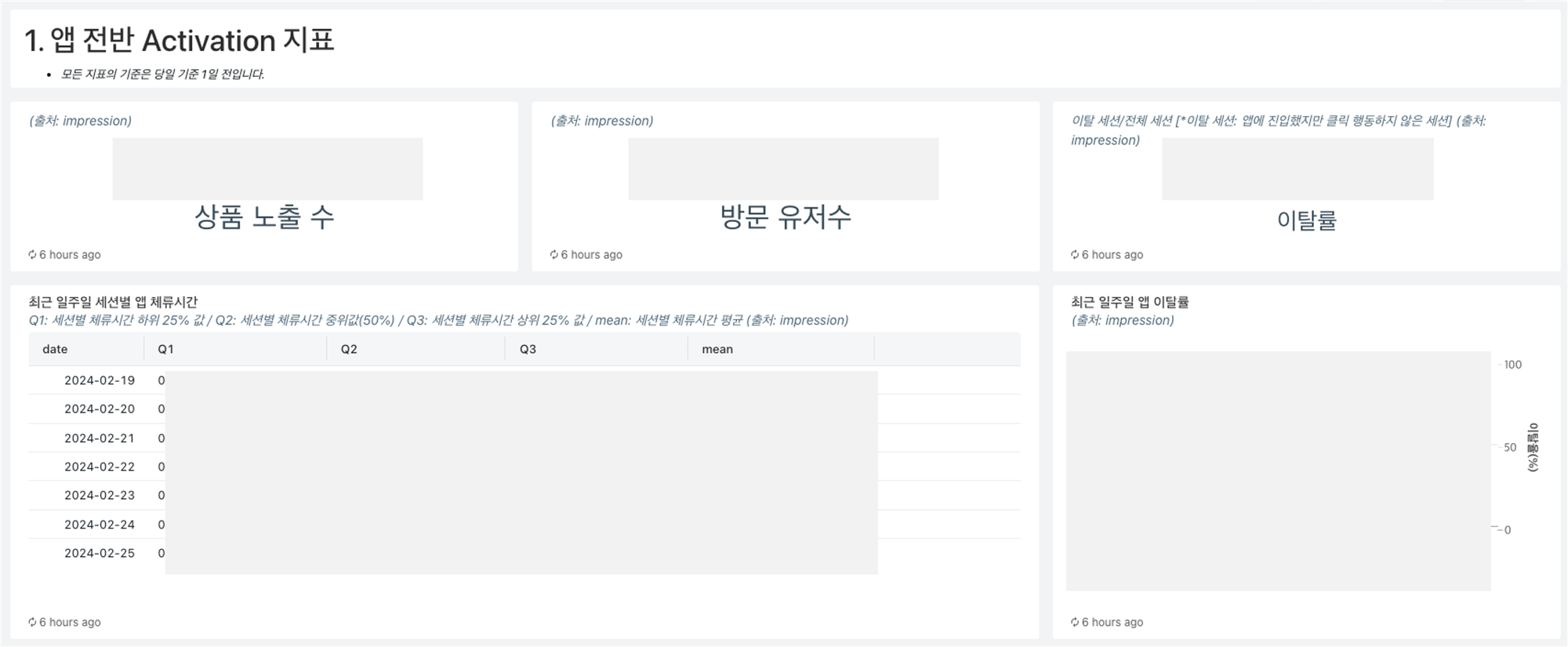
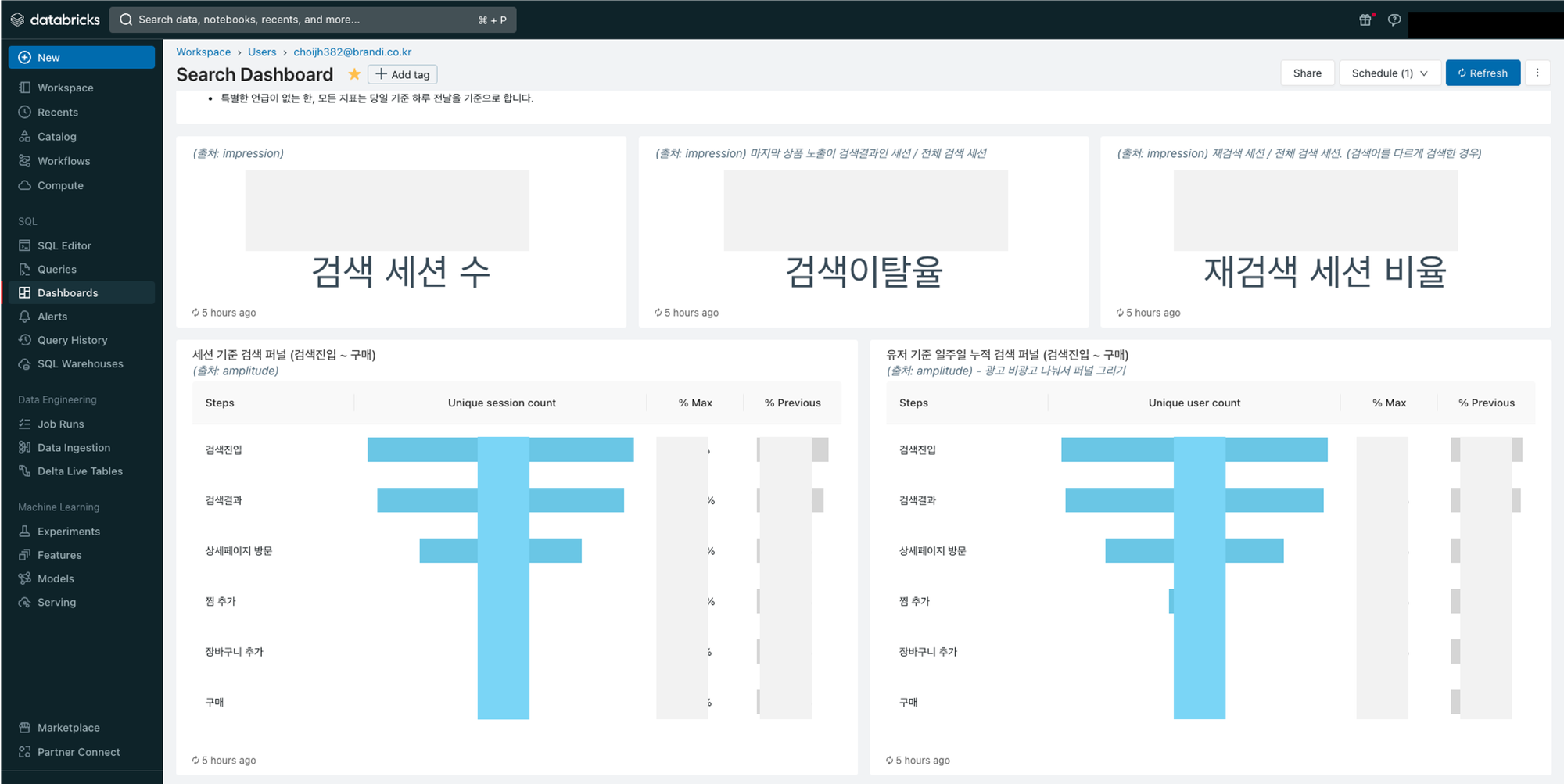
고객이 가장 많이 방문하는 메인페이지, 검색 지면, 상품 상세 페이지, 총 3가지 지면을 위주로 Activation과 Retention 관련 지표를 선정하고 개발하였습니다.
- Activation
Activation의 경우 고객의 활동성을 정의할 수 있는 방식이 다양하기 때문에 각 지면별로 활동성에 관한 주요 질문을 던지고 질문의 답이 될 수 있는 지표를 제시하는 방식으로 개발하였습니다. 핵심 질문과 그에 대한 답변이 되어주는 지표를 나열하면 아래와 같습니다.
(1) 메인페이지
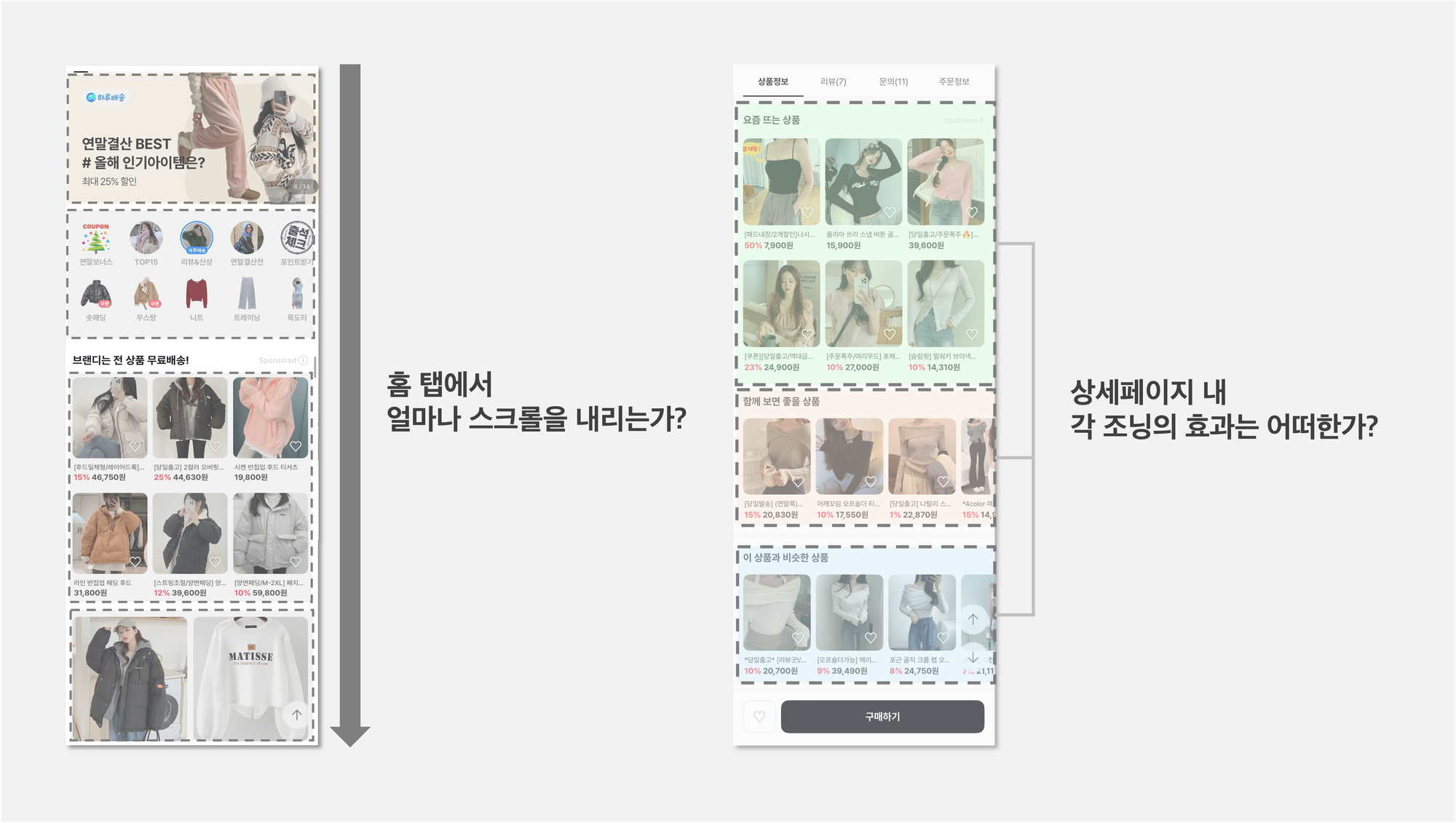
Q1. 고객은 브랜디의 홈 탭에서 얼마나 스크롤을 내리는가?
- 메인페이지의 영역별 노출 유저 수 비율: 메인페이지에서 각 영역(메인배너, 최상단 조닝, 무한추천영역)별로 몇 명의 고객이 노출됐는가?
- 특정 조닝 마지막 노출 상품의 진열 순서
Q2. 각 조닝의 상품 노출 상황 및 효과는 어떠한가?
- 영역별 상품 CTR, 노출된 상품 수 , 셀러 수
Q3. 고객이 메인페이지에서 본 상품에 대해 다른 페이지보다 얼마나 더 특정 행동을 수행하는가?
- 메인페이지의 찜, 상세페이지 클릭 수 등
- 홈에서 클릭한 상품에 대한 구매까지의 퍼널
(2) 상세 페이지
Q1. 상세 페이지는 충분히 다양하게 노출되고 있는가?
- 전체 상품 대비 4번 이상 조회된 상품 수 등
Q2. 상세페이지 내 각 조닝의 상품 노출 상황 및 효과는 어떠한가?
- 조닝별 CTR
(3) 검색페이지
Q1. 고객이 검색을 통해 본 상품에 대해 다른 페이지보다 얼마나 더 특정 행동을 수행하는가?
- 검색 상품 클릭수
- 검색에서 진입한 상품에 대한 구매까지의 퍼널 등
Q2. 검색 결과 지면에서 광고상품과 비광고 상품의 효율은 어떻게 다른가?
- 광고 여부별 상품 CTR 및 클릭 수
Q3. 검색어랭킹과 변화는 어떠한가?
- 급상승 검색어, 최근 한달 검색어 랭킹
Q4. 검색 이전과 이후 행동은 어떻게 되는가?
- 검색 이전 행동 event flow, 검색 이후 행동 event flow
Activation 단계에서는 퍼널 분석을 적극 활용했습니다. 예를 들어, 홈에서 상품 상세페이지를 클릭한 경우 대비 검색에서 상품 상세 페이지를 클릭한 경우 찜과 장바구니, 구매까지 가는 비율을 비교하였습니다.
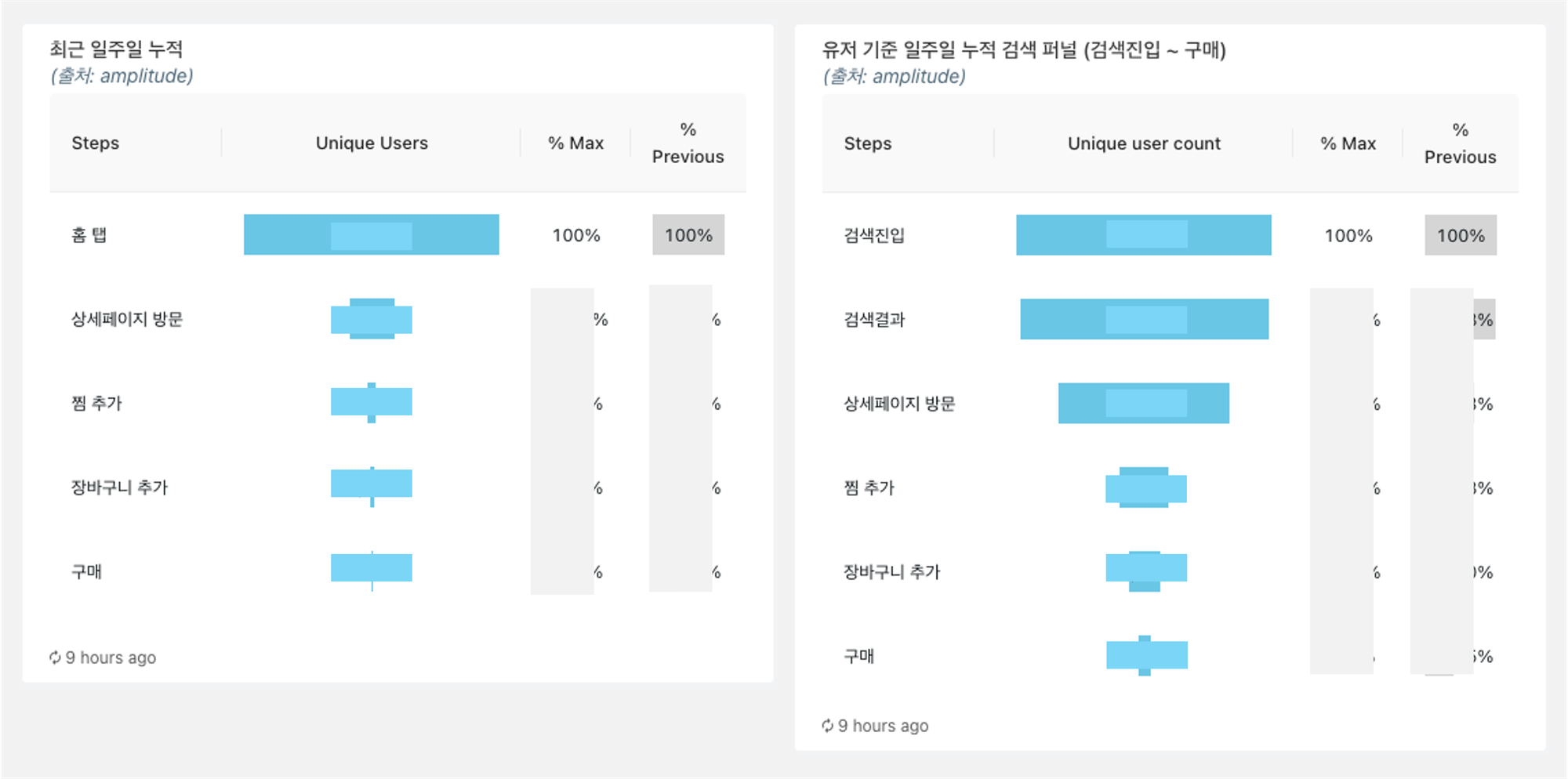
2. Retention
Retention 지표의 경우 코호트 분석을 결합하여 지표가 떨어지는 원인을 찾고자 시도했습니다. 전체 방문 리텐션 및 구매 리텐션을 구하고 구매자와 비구매자로 코호트를 나누어 방문 리텐션을 확인했습니다.
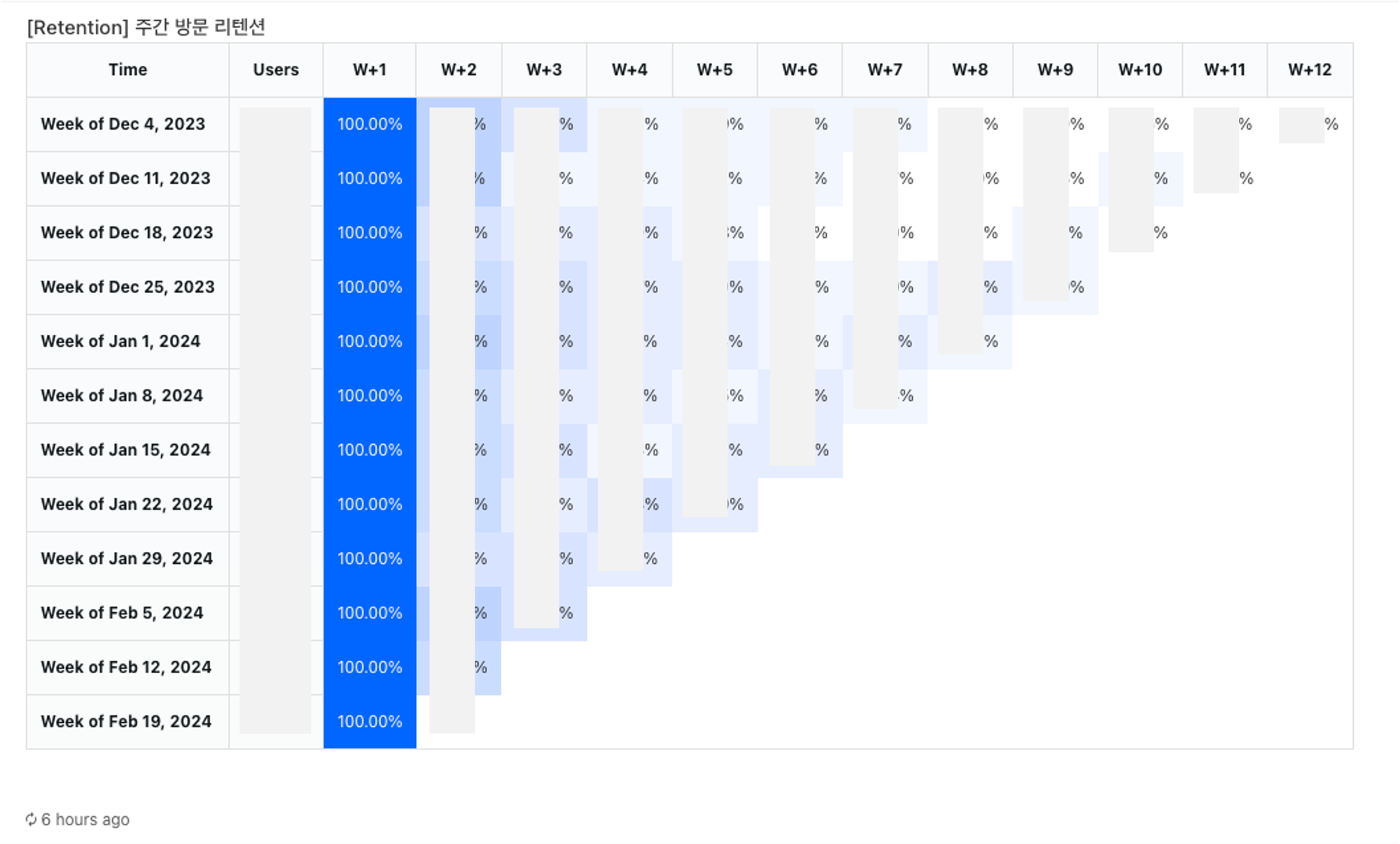
🏀 데이터 파이프라인은 어떻게 설계하고 무엇을 발견했나요?
현재 저희팀은 검색, 추천 그리고 CRM 최적화 작업을 진행하고 있습니다. 그리고 앞에서 정현님이 언급한 Ad-hoc한 분석을 진행하면서, 비즈니스와 밀접한 광고실 및 유관 부서에 데이터 분석 리포팅을 제공하고 있어요.
데이터 파이프라인을 만들고 운영하면서 데이터 분석가를 포함한 데이터 관련 팀원 분들, 비즈니스 문제와 직접적으로 맞닿은 유관 부서분들 그리고 서비스를 이용하는 고객 모두를 고려해야 한다는 점을 알 수 있었습니다.
결국 데이터 파이프라인을 설계할 때도 도메인에 대한 이해가 필요합니다.
🔥 패션 커머스 플랫폼의 특이점
패션 커머스는 어떤 특징을 가지고 있을까요?
앞에서 팀이 서비스의 전반적인 상황을 종합적으로 파악하기 위한 동기 부분에서 말씀드린 대로 패션 커머스 플랫폼은 크게 세 축으로 구성되어 있습니다.
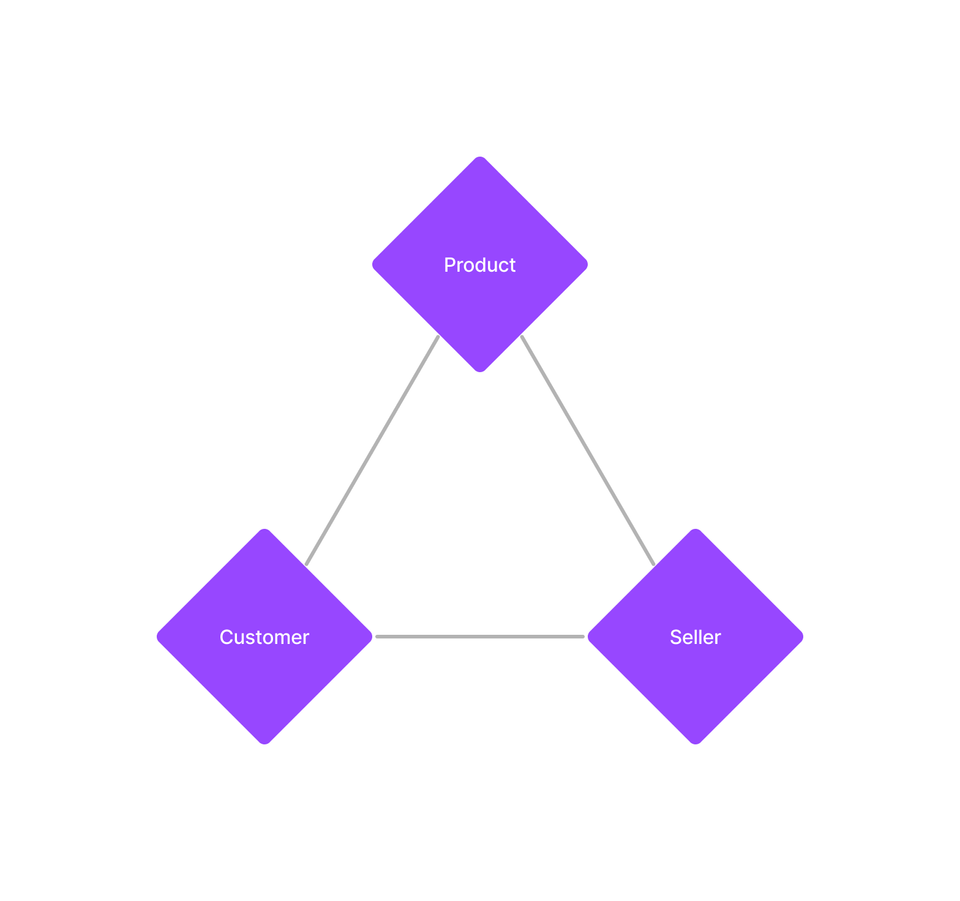
세 축은 각각 {상품, 고객, 셀러} 입니다. 고객과 셀러는 상품으로 연결됩니다. 플랫폼 특성상 상품, 고객, 셀러 모두를 고려해야 합니다. 이 중에서 한 축을 놓치는 순간 플랫폼은 급격히 무너집니다.
다음으로 이커머스에서 고객의 행동 경로를 살펴보면 아래와 같은데요.
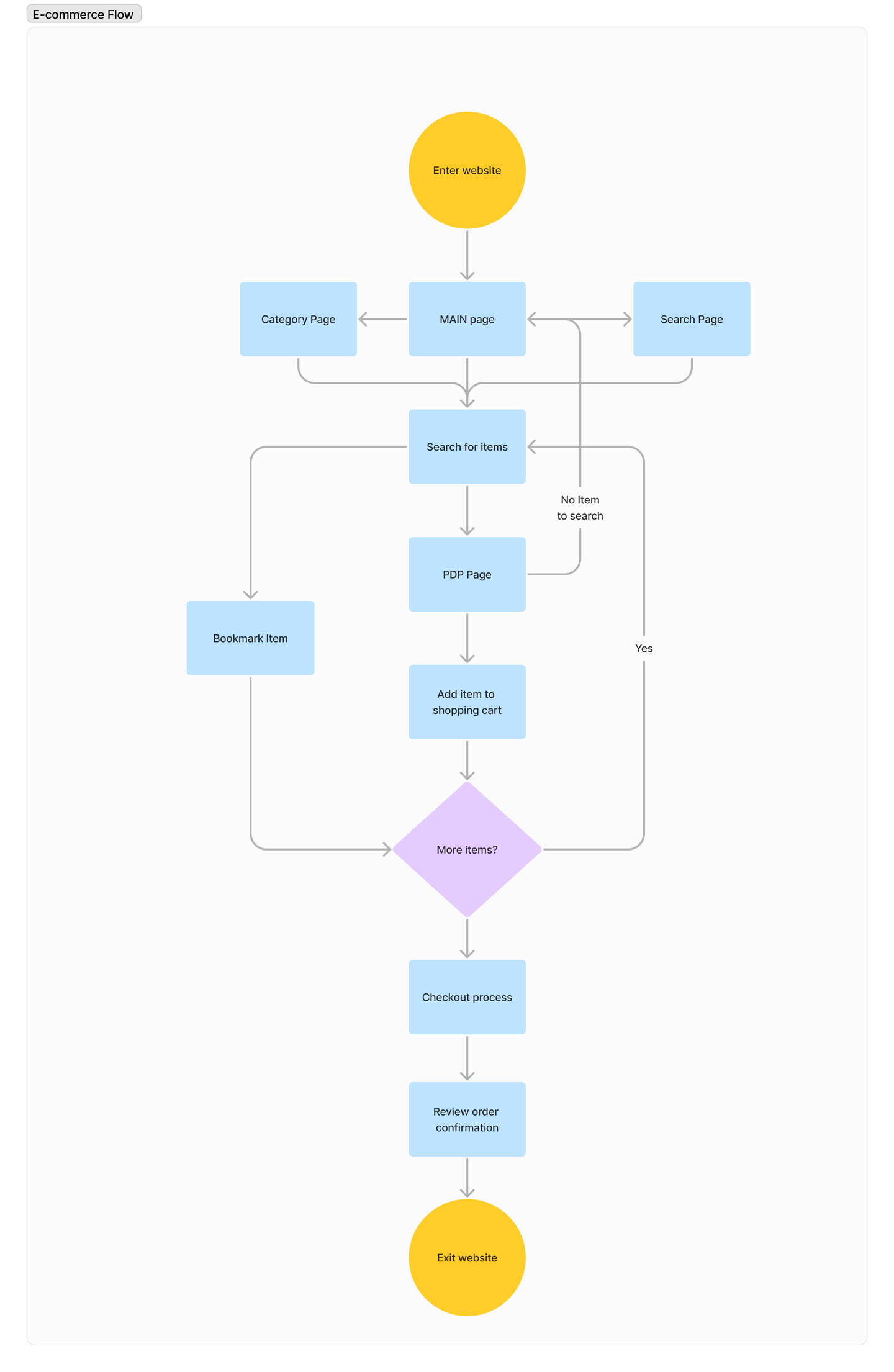
고객이 상품과 밀접하게 행동하는 주요 페이지는 메인 페이지, 상품 상세 페이지 그리고 검색 페이지인 것을 데이터 분석을 통해 확인할 수 있습니다. 다시 말해서 위의 세 축(상품, 고객, 셀러)과 함께 페이지간의 관계를 파악하기 위한 데이터 분석이 필요했습니다. 그리고 데이터 분석을 원활하게 하기 위해서 미리 각 축을 기준으로 정리된 데이터가 필요함을 알 수 있습니다.
⚽ 비즈니스 문제를 풀기 위한 데이터 파이프라인
데이터 파이프라인은 결국 조직이 마주친 비즈니스 문제를 풀고 현상을 파악하기 위해서 존재합니다. 비즈니스를 풀기 위해서 Analytics 파이프라인과 ML 파이프라인이 존재합니다. 결국 데이터 엔지니어링 라이프 사이클을 추상화하면 아래 이미지와 같은데요.
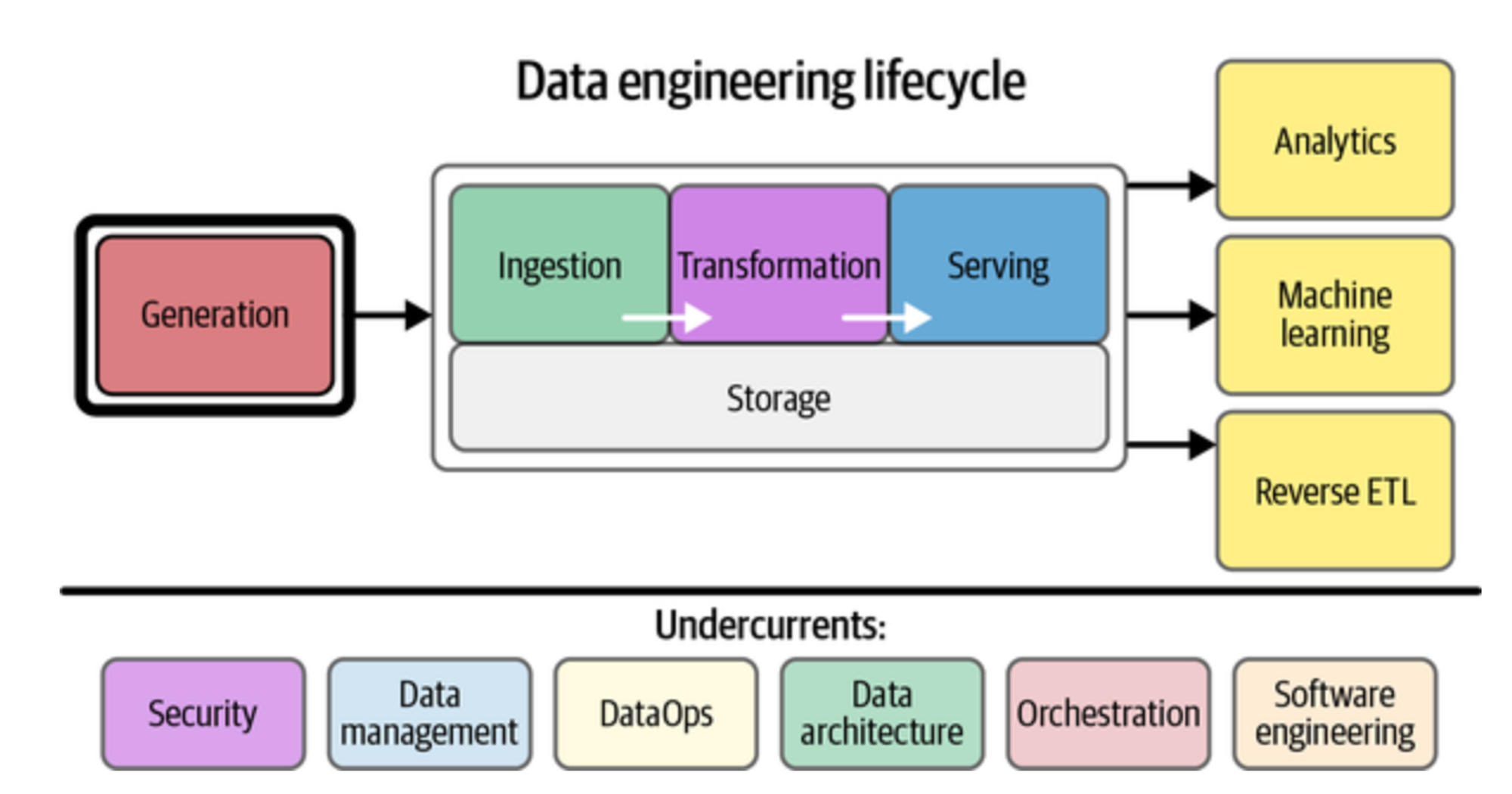
앞에서 말씀드린 여러 태스크와 리포팅이 공통적으로 사용하는 데이터는 유입 데이터, 고객의 행동 데이터 그리고 커머스 서비스를 위한 트랜잭션 데이터입니다.
데이터 파이프라인을 고안 및 개선하면서 느낀 점들은 크게 두 가지입니다.
- 먼저 배치 및 스트리밍 데이터 파이프라인을 구성할 때, 파이프라인 자체에서 발생할 수 있는 데이터 정합성 오류와 병목현상을 최소화하는 것입니다.
- 두번째는 데이터 파이프라인이 생산하는 최종 결과물의 대상 고객과 고객이 원하는 것을 확실히 파악하는 것입니다. 이 때 중요한 것은 도메인에 대한 이해입니다.
1. 데이터 파이프라인 자체에서 발생할 수 있는 내재적인 문제 다루기
팀에서 활용하는 데이터 파이프라인의 기본 저장소는 S3입니다. 여러 형태의 데이터를 S3에 쌓는 구조를 효율적으로 처리하기 위해서 저희는 Medaillion architecture를 차용하였습니다. Medallion architecture의 구조는 아래와 같습니다.
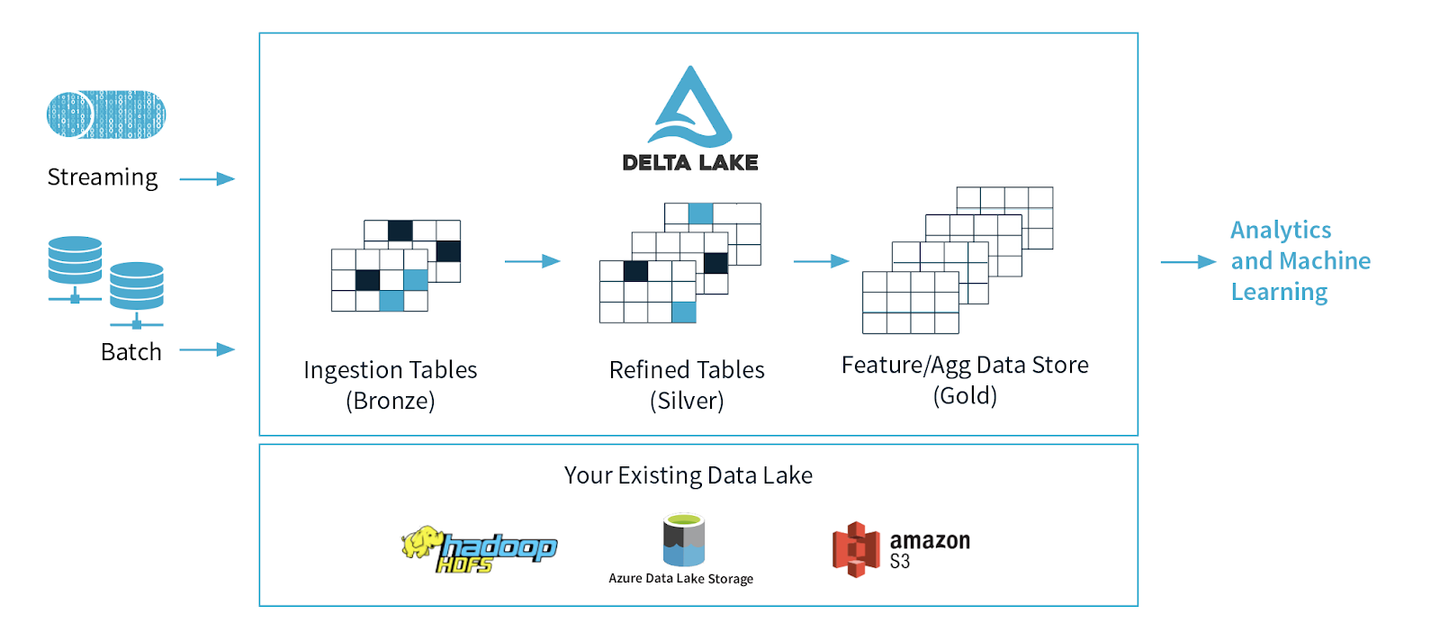
위의 아키텍처를 이커머스 도메인과 팀의 태스크에 맞게 적용하고 보완하면 다음과 같은 데이터 파이프라인을 고안할 수 있습니다.
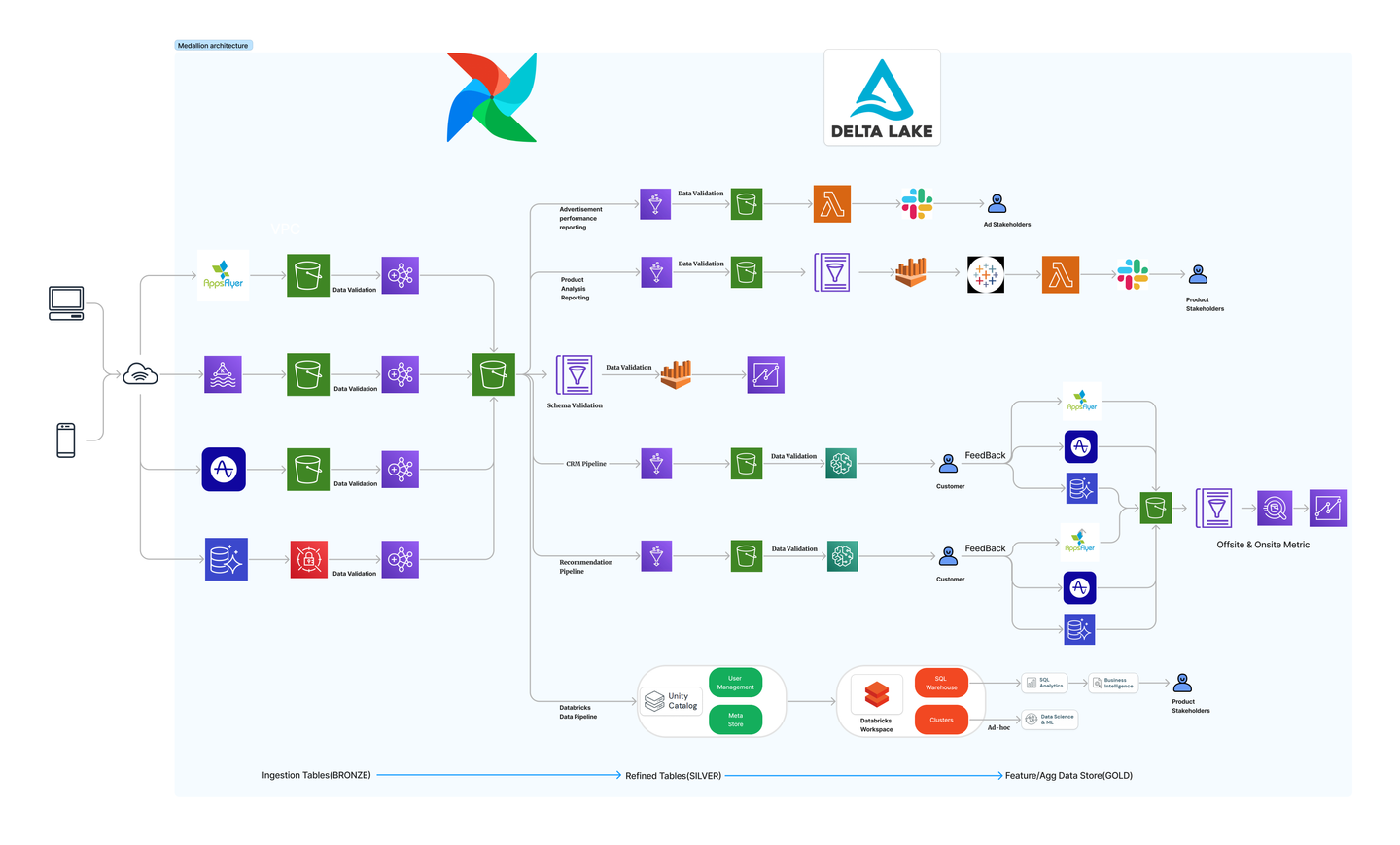
- Bronze data layer
- Bronze 레이어에는 내부 RDS 내 데이터와 외부 소스 시스템에서 로깅된 모든 데이터가 저장됩니다.
- 외부 소스에는 현재 앱스플라이어 데이터 라커 데이터와 앰플리튜드 데이터 그리고 Impression 데이터가 존재합니다.
- 데이터 적재시 신선도(Freshness) 측면에서 가장 다운 타임이 증가하는 데이터 레이어입니다.
- Silver data layer
- Bronze 레이어 내 데이터를 주요 도메인의 축 기준으로 ETL한 뒤 적재합니다.
- Silver 레이어에는 Gold 레이어에 도달하기 전 지표 추출, 데이터 분석, ML을 지원하기 위해 존재합니다.
- 데이터 분석가, 데이터 사이언티스트, ML 엔지니어가 주로 사용하는 데이터 레이어입니다.
- Gold data layer
- 현재 Gold 레이어도 S3에 저장하지만 프로젝트별로 다른 경로로 저장됩니다.
- 태블로와 같이 쿼리시 연산 속도가 느린 시각화 BI는 정제가 완료된 Gold 레이어 내 데이터를 사용하는 것이 좋습니다.
데이터 파이프라인을 구성할 때 가장 중요한 것은 데이터 다운 타임을 최소화하는 것입니다. 데이터 다운 타임은 데이터의 오류로 인해 서비스의 가동이 중지되는 상황을 의미합니다.
Appsflyer가 제공하는 Data Locker 데이터를 통해 고객의 유입을 확인할 수 있습니다. 그리고 세션 단위의 화면 노출 및 클릭 행동을 트래킹 하는 앰플리튜드 데이터가 존재합니다. 그리고 정산 및 정확한 비즈니스 로직을 위해 필요한 RDS 내 데이터가 있죠.
구체적인 파이프라인 고안 전에 데이터 소스의 적재 빈도, 데이터 스키마, 적재되는 과정을 살펴보았습니다. 여러 소스가 존재하고 각 소스의 적재 시간 단위가 동일하지 않은 점(실시간으로 쌓이는 데이터가 존재하고 시간 단위로 적재되는 데이터도 존재해요!)을 알 수 있었습니다. 그리고 비즈니스 로직상 적재량의 차이도 상대적으로 심한 것을 확인했습니다.
파이프라인을 운영하면서 다운 타임에 가장 큰 영향을 끼친 것은 Bronze layer에서 데이터가 적시에 적재가 되지 않은 신선도(Freshness)문제입니다. 신선도는 결국 데이터의 최신성을 파악하는 것이 중요합니다.
신선도와 관련된 파라미터를 조정하는 것은 비즈니스 맥락에 따라 달라집니다. 예를 들어 임프레션당 셀러에 과금을 계산하는 광고 로직에 필요한 테이블을 대상으로는 업데이트 최신성의 단위가 짧아야 합니다. 그리고 신선도 지표의 대상이 되는 테이블의 이상치 기준을 낮게 잡아 재현율을 높여서 실제 이상 징후를 최대한 많이 포착해야 합니다.
신선도와 함께 실제 데이터 파이프라인에서 많은 오류의 근본적인 원인에 스키마 변화와 데이터 분포 변화가 있었습니다. 위의 문제를 해결하기 위해 Schema Validation과 Data Drift를 잡는 알고리즘을 설계 하였습니다. 구체적으로 Schema Validation은 스파크를 통해 별도의 유효성 로직(i.e. Null값 사용 여부, 컬럼별 범위 제한, 고유 값 유무)을 적용하였습니다. Data Drift 같은 경우 기본적인 알고리즘(i.e. Moving Average, KL divergence)을 통해 자동으로 파악하여 대처할 수 있었습니다.
현재 팀 내 데이터 파이프라인 내 데이터 집계를 Athena(아테나)를 활용하는 부분이 많은데요. 아테나는 스캔한 데이터 양만큼 과금하므로 데이터를 분할 저장하여 원하는 파티션만큼 검색할 수 있는 파티셔닝이 중요합니다. 또한 데이터 파이프라인에서 지켜야 할 멱등성(특정 이유로 데이터 파이프라인을 여러번 실행해도 결과가 다르지 않게 하는 것!)과 원천 데이터의 완전성 원칙을 지키는 것이 중요합니다.
2. 데이터 파이프라인 외부의 외재적 상황 다루기
비즈니스 문제를 풀기 위한 데이터 파이프라인은 필연적으로 여러 이해 관계자와 연결됩니다. 회사의 비즈니스는 디스플레이 광고와 검색 결과 광고를 포함하는 리테일 미디어(Retail Media)를 포함하고 있습니다. 이와 관련하여 중요한 지표는 앱 내 고객의 활동성과 관련된 지표(i.e. 서비스 체류 시간)임을 데이터 분석을 통해 알 수 있습니다.
고객의 활동성 지표를 AARRR 프래임워크 중 Activation과 Retention으로 해석하고, 빠르게 대시보드에 표현하기 위해서는 앞에서 언급한 대로 패션 커머스 플랫폼은 크게 세 축으로 구성되어 있습니다. 세 축(고객, 상품, 셀러)으로 데이터가 Silver Data Layer에 적재되어야 합니다. 해당하는 주요 축은 도메인 및 풀고자 하는 비즈니스 문제에 따라 많이 다른데요. 중요한 점은 데이터 파이프라인 설계 시 개별적인 태스크 별로 공통적으로 사용할 수 있는 피처(feature)들을 발견하고 중복되는 연산량을 줄이는 것입니다.
이것을 효율적으로 해결하기 위해서 다양한 태스크에서 주요 축 단위로 정돈된 피처를 한 저장소에서 확인할 수 있어야 하는데, 해당 데이터 스키마를 저장하고 확인하는 작업은 글루 카탈로그와 Unity Catalog의 메타 스토어를 통해 원활히 진행할 수 있습니다.
팀 내부에서는 보다 빠른 대시보드 설계를 원했습니다. 그래서 데이터 아키텍처상 주요 저장소가 S3 기반인 AWS 내 브론즈 데이터와 실버 데이터를 Unity Catalog를 통해 데이터브릭스에 연결하였는데요. Unity Catalog와 연동된 Databricks SQL 서비스에 접근 가능했습니다. 작업 이후 자유롭게 정현님과 SQL 문법을 통해 주요 페이지 단위 대시보드를 제작할 수 있었습니다.
다만 전사 공유가 필요한 순간이 오면서 데이터브릭스 내 대시보드는 확장성이 떨어졌습니다. 왜냐하면 저희팀을 제외한 나머지 모든 팀은 태블로를 통해 데이터 및 대시보드 공유를 진행하기 때문입니다. 그래서 현재는 AWS 서비스와 태블로를 결합하여 의미 있게 발견한 데이터 인사이트를 대시보드로 제공하고 있습니다.
🏈 대시보드를 실제로 어떻게 구성했나요?
지금까지 대시보드 작성 전 지표의 선정 및 개발 과정을 소개하고, 그 이후 데이터 파이프라인을 통한 자동화 과정을 순철님이 설명드렸습니다. 이번에는 데이터와 지표가 준비된 상황에서 대시보드를 구성하고 지표를 시각화하는 과정을 말씀드리려 합니다.
좋은 시각화란?
이 단계에서 중요한건 “어떻게 데이터를 효과적으로 시각화할 것인가”의 문제입니다. 좋은 시각화란 무엇인지 몇가지 원칙을 설정하고 이에 맞게 각 차트를 구성하고자 하였습니다.
- 하나의 차트에서는 하나의 메시지를 전달해야 함
- 과한 색깔 사용 등으로 독자의 시선이 분산되지 않아야 함
- 색깔을 제한적이고 효과적으로 사용하기, 텍스트의 정렬을 통일하기 등
- 사람이 옆에서 설명하지 않고 차트만 보았을 때에도 의도한 정보를 읽을 수 있어야 함
- 결국 비즈니스 의사결정에 직접적인 도움이 되는 인사이트를 제공해야 함
위의 사항을 고려한 몇가지 예시를 살펴보겠습니다.
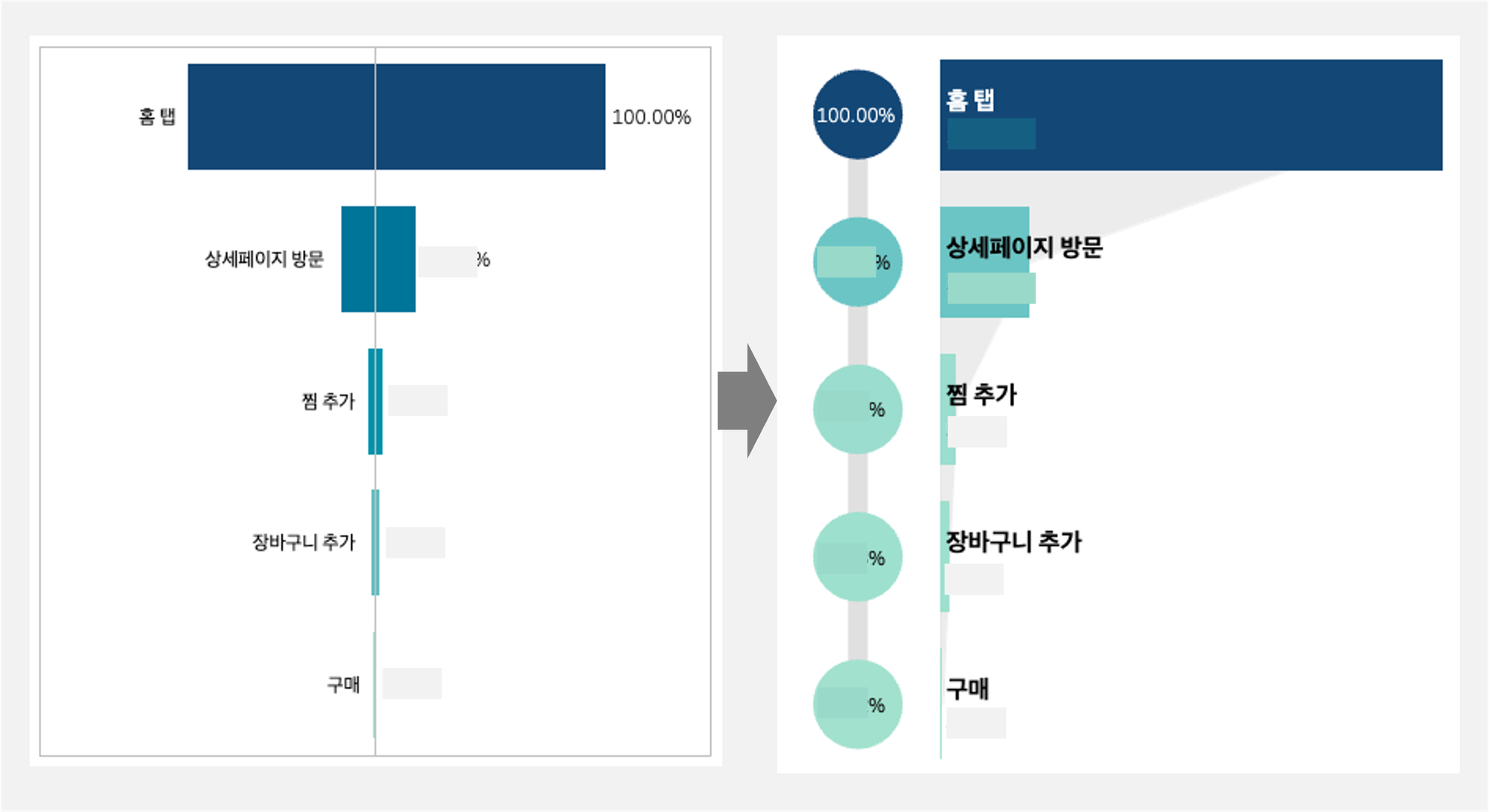
(1) 하나의 차트에서 하나의 정보만을 전달하기 위해 왼쪽과 같이 두 가지 내용이 한꺼번에 들어가있는 그래프를 오른쪽과 같이 두개의 그래프로 쪼개서 수정하였습니다.
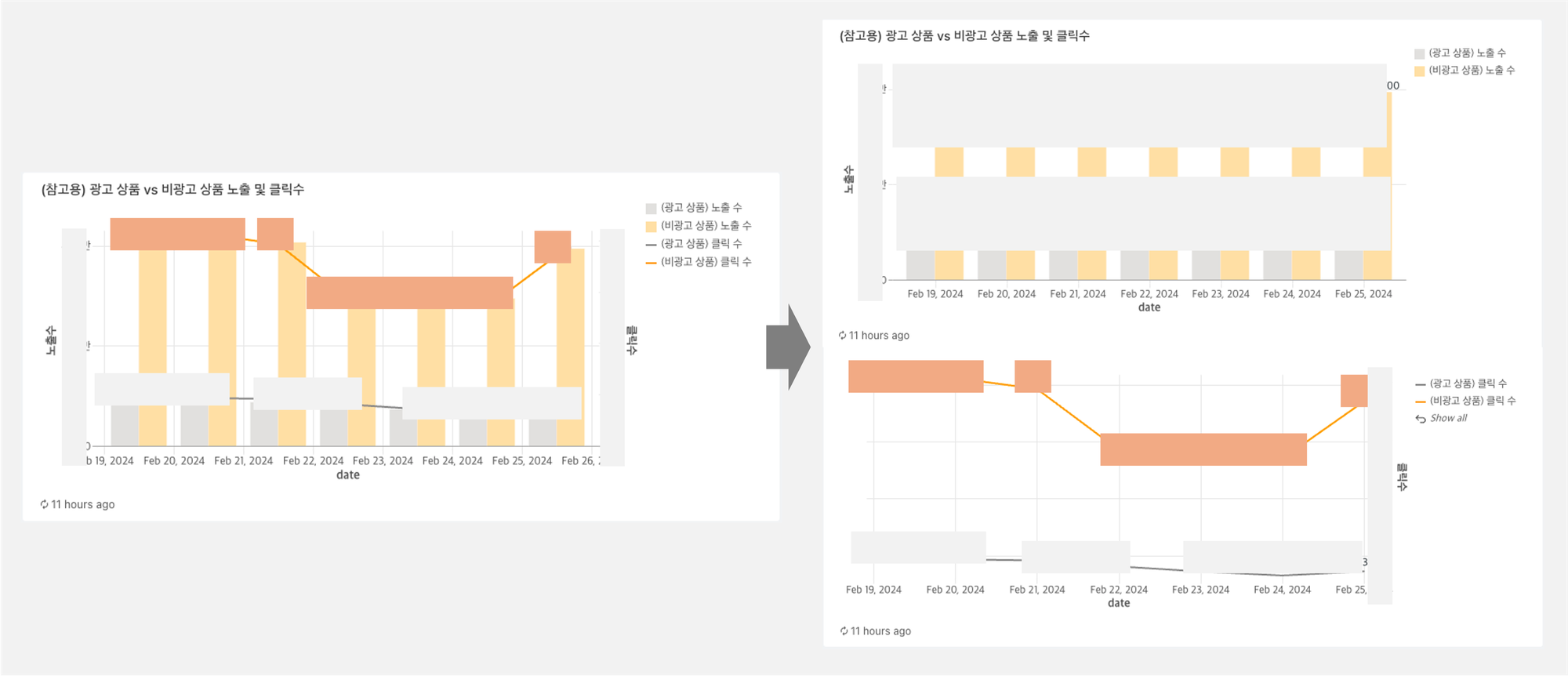
(2) 독자의 시선을 분산시키지 않기 위해 차트의 형식을 변형하였습니다. 아래와 같이 텍스트의 정렬이 바뀌며 시선을 분산하여 한 눈에 알아보기 어려운 왼쪽 그래프를 오른쪽의 방식으로 개선하였습니다.
DATABRICKS SQL VS ATHENA + TABLEAU
대시보드는 두 차례에 걸쳐 각기 다른 툴을 사용하여 제작하였습니다. 첫 번째로는 팀 내부 공유 용으로 데이터브릭스를 활용했고 그 다음으로는 전사 공유를 위해 아테나와 태블로를 사용하여 제작했습니다.
데이터브릭스는 여러 데이터 소스를 연결하여 데이터를 관리할 수 있을 뿐 아니라 ML 파이프라인을 구성해 자동화를 진행하거나 BI 툴로써 시각화 및 대시보드 작성이 가능합니다. 한편, 아테나는 AWS의 S3에 적재된 데이터를 분석할 수 있는 쿼리 서비스이며 태블로는 데이터 시각화에 특화되어 있는 전문 툴입니다.
(1) 데이터브릭스
데이터 브릭스 시각화의 큰 장점은 빠르고 간편하다는 것입니다. 데이터 브릭스 툴 안에서 SQL로 쿼리를 작성하면 한 창에서 바로 시각화가 가능하고, 해당 차트를 그대로 대시보드에 추가할 수 있습니다. 게다가 쿼리 결과가 적절한 형태로 주어졌을 때, 시각화 타입을 골라서 몇가지 값만 작성해주면 알아서 차트를 그려줍니다.
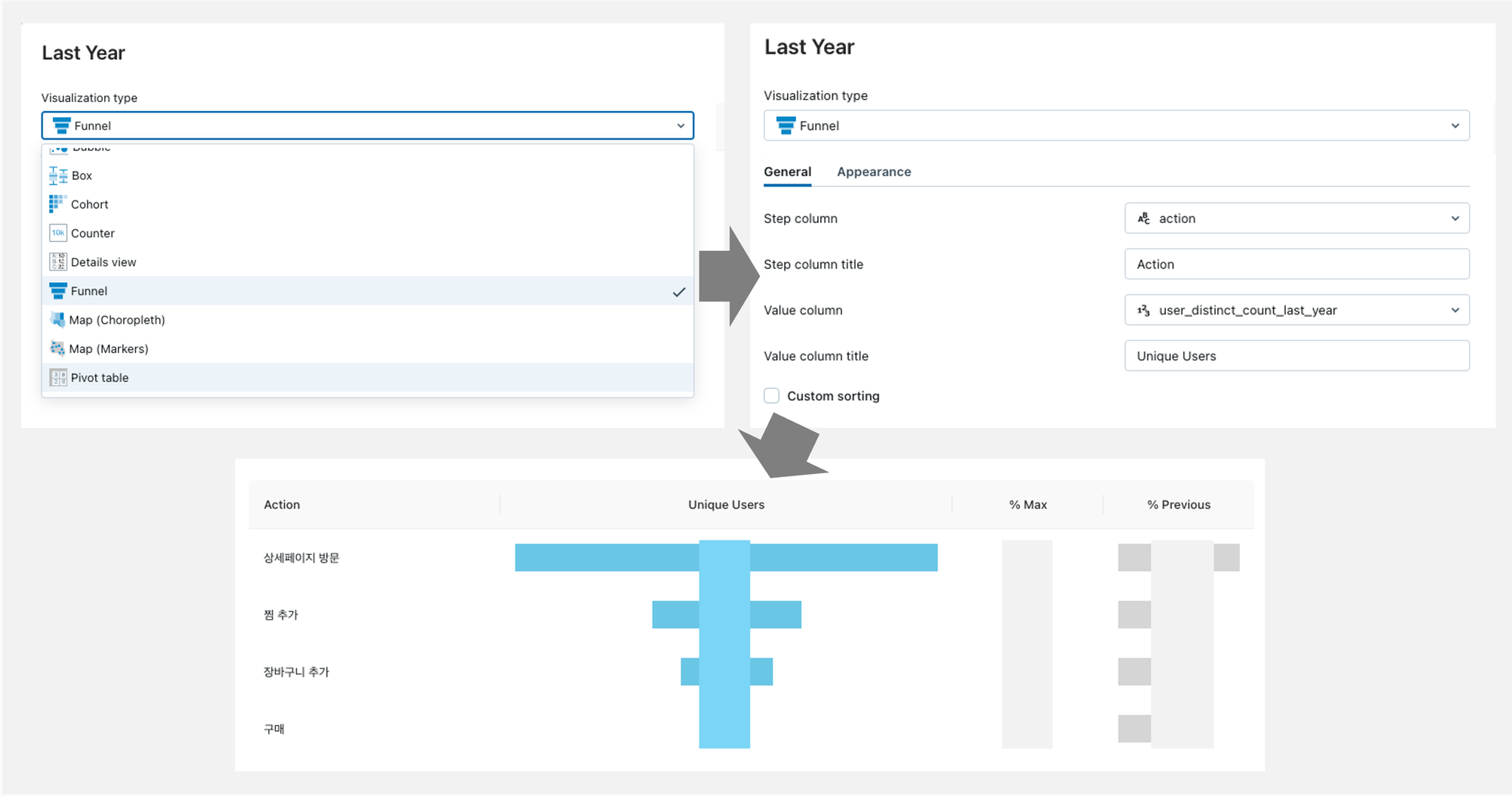
그러나 차트를 그리거나 대시보드를 구성하는 데에 있어서 자유도는 적은 편입니다. 예컨대 퍼널 차트를 그리고 싶다면 반드시 아래 예시와 같은 형태로만 그릴 수 있으며, 텍스트나 이미지 작성 역시 HTML 기본 문법을 통해서만 수정이 가능했습니다.
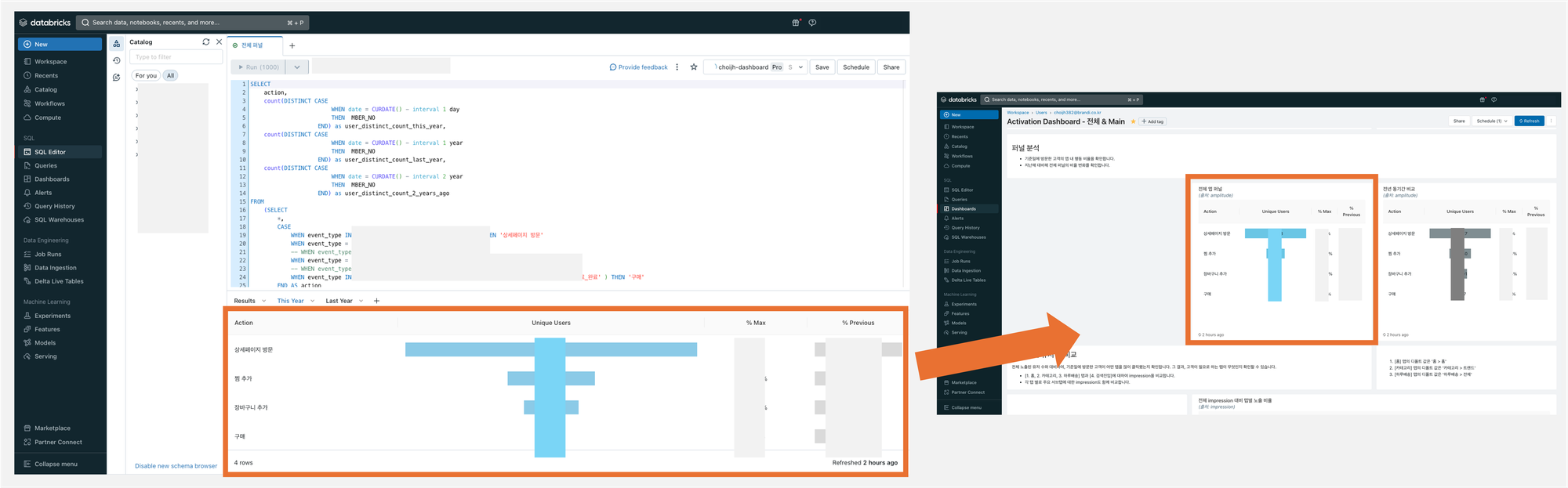
사실 기존 다른 팀은 모두 태블로로 데이터 및 대시보드를 공유해왔는데요. 데이터브릭스 대시보드로 바로 전사 공유가 가능할지 검토해보았지만 권한 문제가 있었습니다. 대시보드를 ‘볼 수 있는 사람’과 ‘데이터 테이블에 접근 가능하고 쿼리를 수정할 수 있는 사람’ 간의 권한 차등 부여가 까다로웠습니다. 대시보드를 보려면 반드시 새로고침이 필요했는데, 이를 위해서 쿼리 및 테이블에 대한 접근 권한 모두가 필요했기 때문이죠. 결국 확장성과 권한 부여 문제로 인해 전사 공유를 위한 대시보드는 태블로로 작성하기로 결정하였습니다.
(2) 아테나 + 태블로
대시보드를 제작하기 위해 사용한 원본 데이터 소스는 S3에 적재되어 있습니다. 이 테이블을 곧바로 태블로에 연결하여 태블로 내에서 수억건의 row를 읽어와 쿼리로 작업을 하게 될 경우 속도가 매우 느려지는 문제가 있습니다.
그래서 Silver Layer내 다른 태스크를 위해 이미 피처가 생성되는 경우 중복으로 계산하지 않았습니다. 그리고 중복 데이터를 활용하여 쿼리를 두번 이상 사용하는 경우 미리 데이터를 Silver Layer에 정제하여 적재하였습니다.
아테나에서 쿼리 작업을 하는 것은 데이터브릭스 SQL의 쿼리 작업과 동일했어요. 다만 둘은 지원하는 문법이 달라 약간의 수정을 거쳐야 했습니다. 아테나는 프레스토 DB 기반 표준 SQL 문을 지원하는 반면, 데이터브릭스는 Databricks SQL이라는 Spark SQL 기반 변형 문법을 사용합니다. 그래서 아래와 같이 쿼리 간의 차이가 존재합니다.
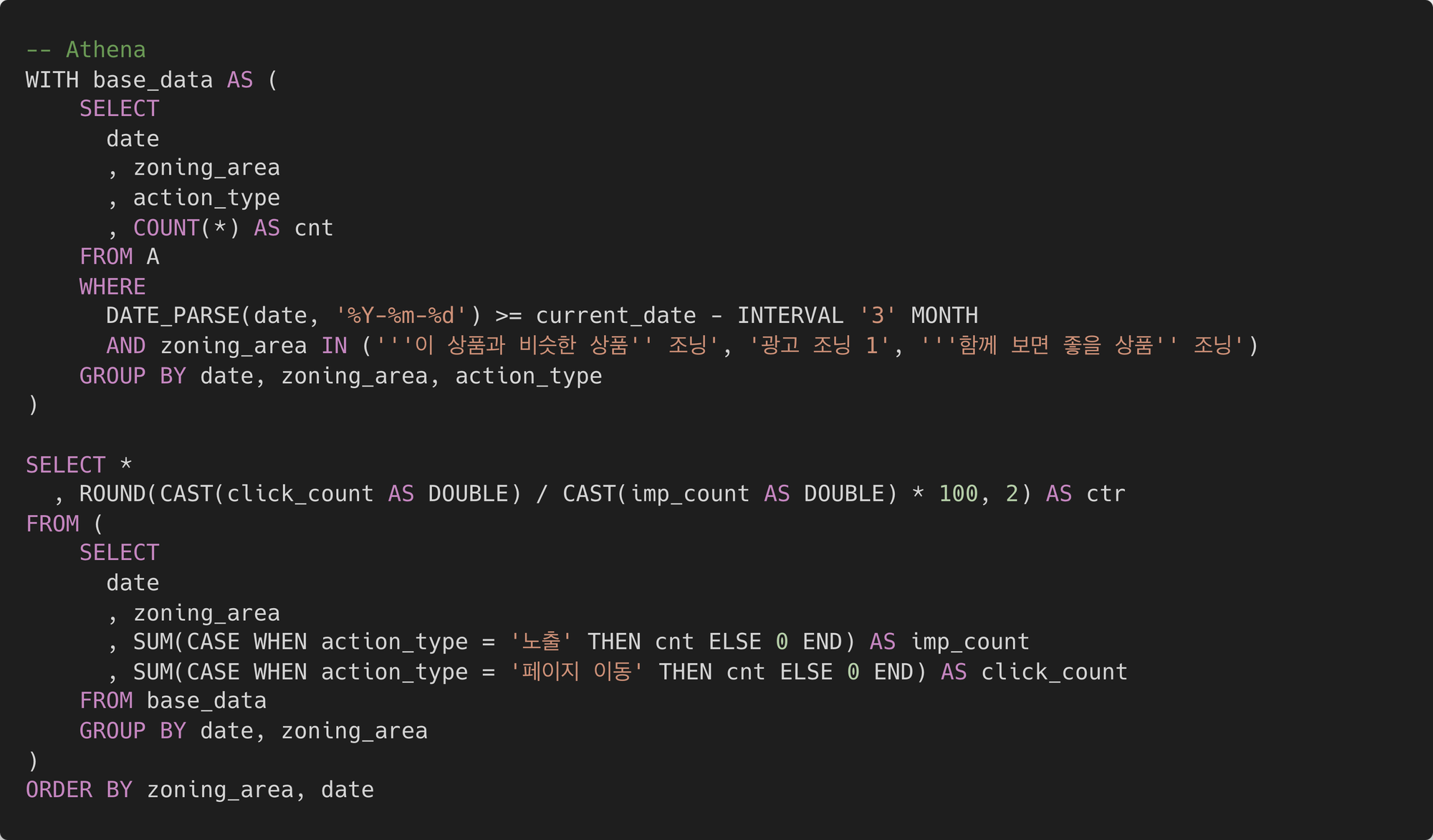
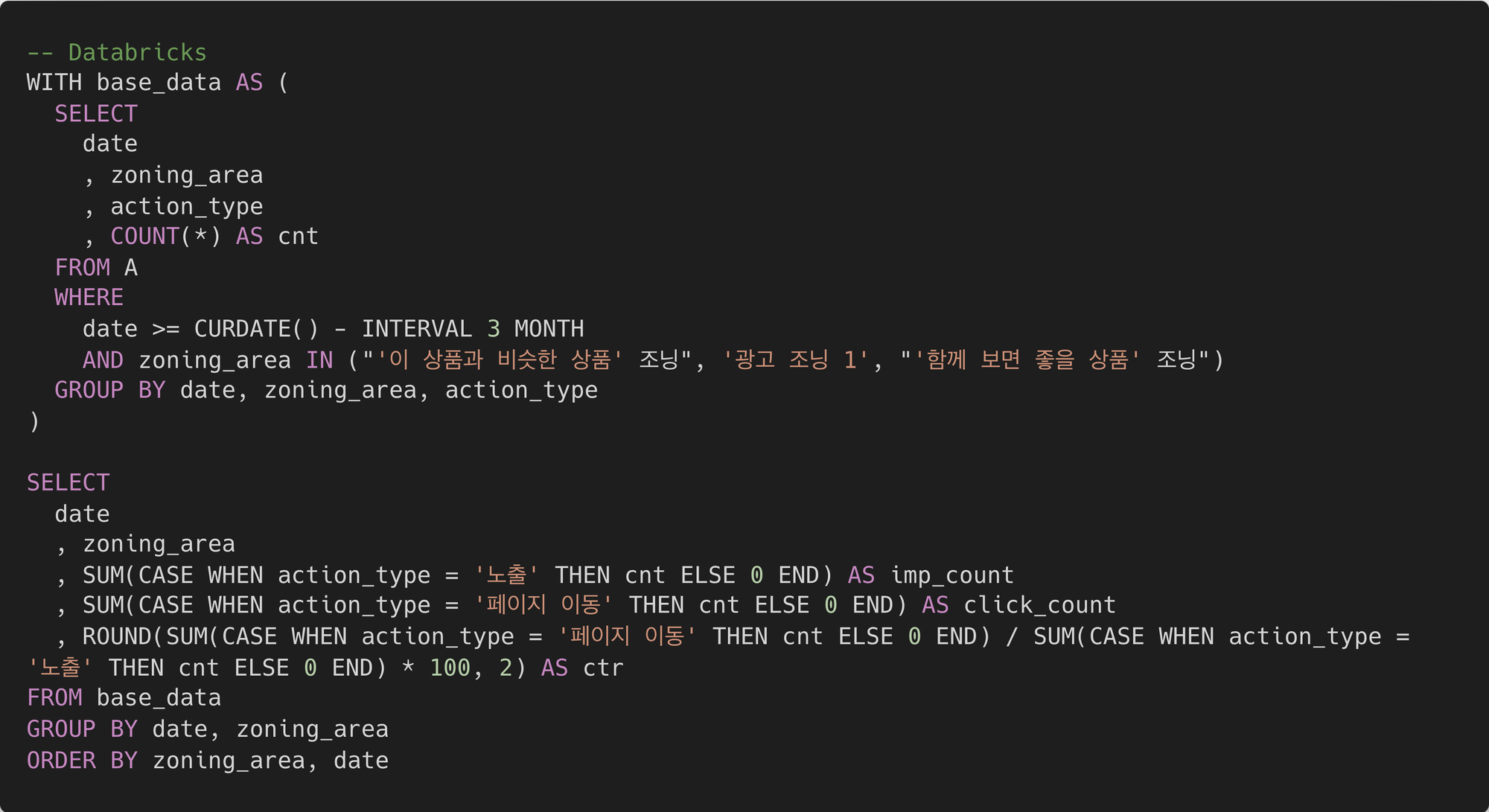
- 날짜 계산 쿼리 차이

- 따옴표 쿼리 차이

- 나눗셈 연산 쿼리 차이

적재한 테이블을 기반으로 태블로에서 시각화를 했습니다. 태블로는 데이터브릭스의 시각화보다 훨씬 많고 다양한 기능을 제공합니다. 정확히는 자유도가 높습니다. 예컨대 똑같은 퍼널을 그릴 때에도 데이터브릭스는 정해진 형식으로 차트를 그려주는 반면 태블로는 보여줄 내용과 방식, 디자인 등 모든 것을 사용자가 지정할 수 있습니다. 데이터브릭스보다 사용법을 익히기 훨씬 복잡하지만, 그만큼 더 정교한 시각화가 가능한 셈입니다.
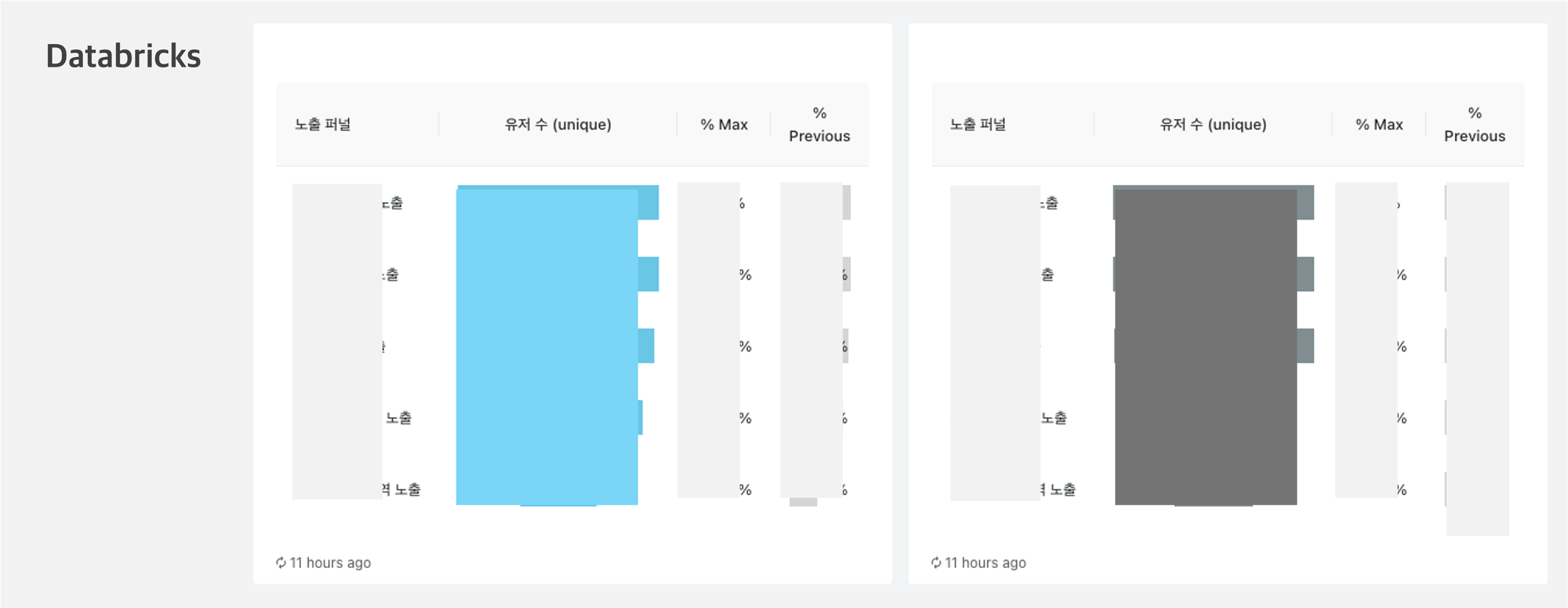
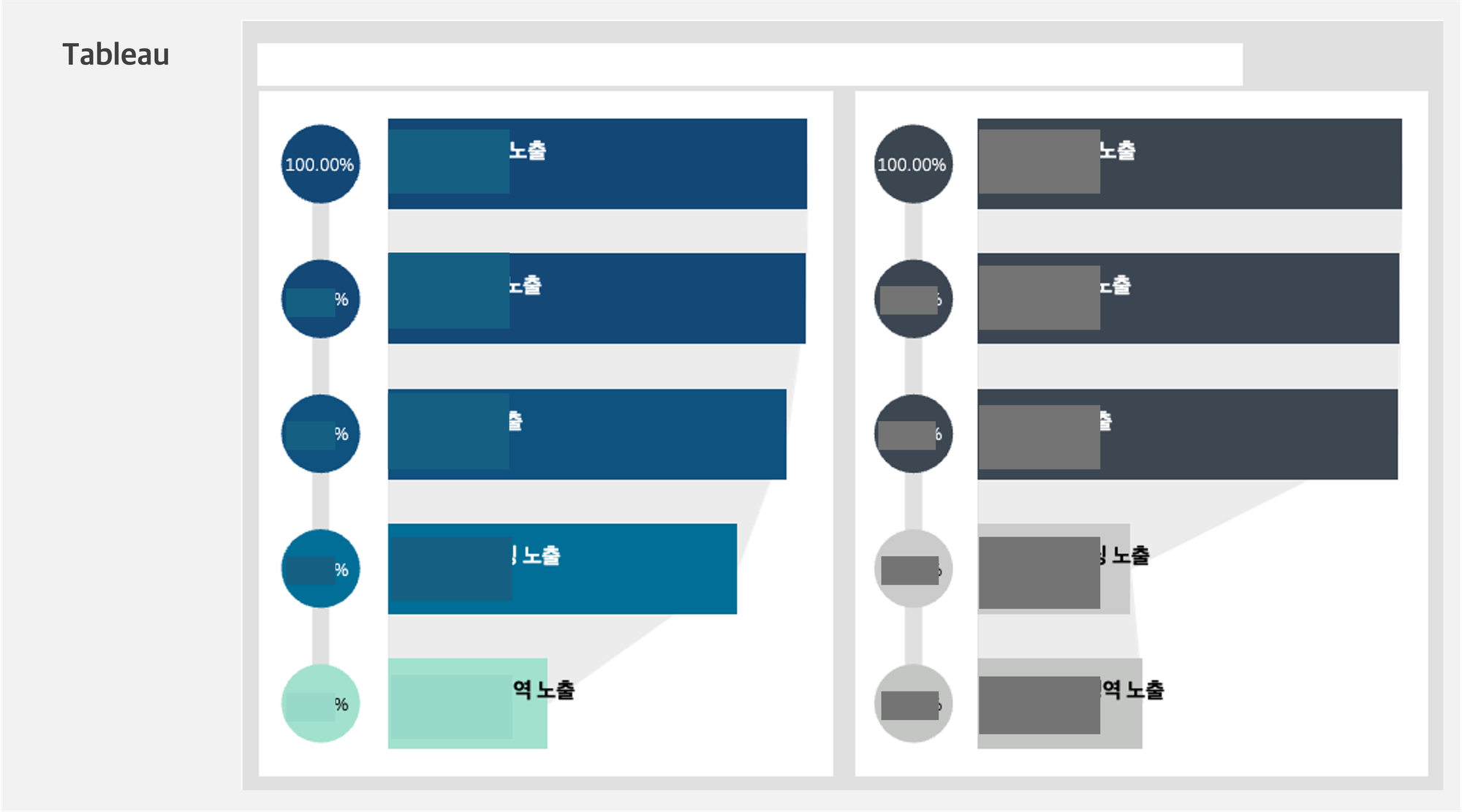
🏀 그래서 어떻게 돈이 됐는데요?
대시보드 제작 이후 지속적으로 지표를 트래킹하며 몇 가지 크고 작은 이슈를 발견하게 되었어요. 그리고 이 문제를 해결함으로써 추가적인 수익을 낼 수 있었습니다.
(1) 상품 노출 임프레션 누수 발견 후 해결
아래와 같이 예시페이지를 보면, 한 페이지 안에 여러 조닝이 보이는 것을 볼 수 있습니다. 그런데 이 조닝별 노출 유저 수를 퍼널 차트로 살펴보니, “A영역의 상품 노출 임프레션에 분명 노출이 되었는데도 노출 유저로 잡히지 않는 임프레션 누수가 생기고 있음”을 확인할 수 있었습니다. 해당 누수 발견 후 AOS / IOS의 UI를 변경함으로써 해당 문제를 해결하였고 그 과정에서 잡을 수 있게 된 임프레션 수 만큼의 실제 금전적인 효과를 얻게되었습니다. 아래 차트를 보시면 그 전에 비해 노출이 잘 잡히고 있네요.
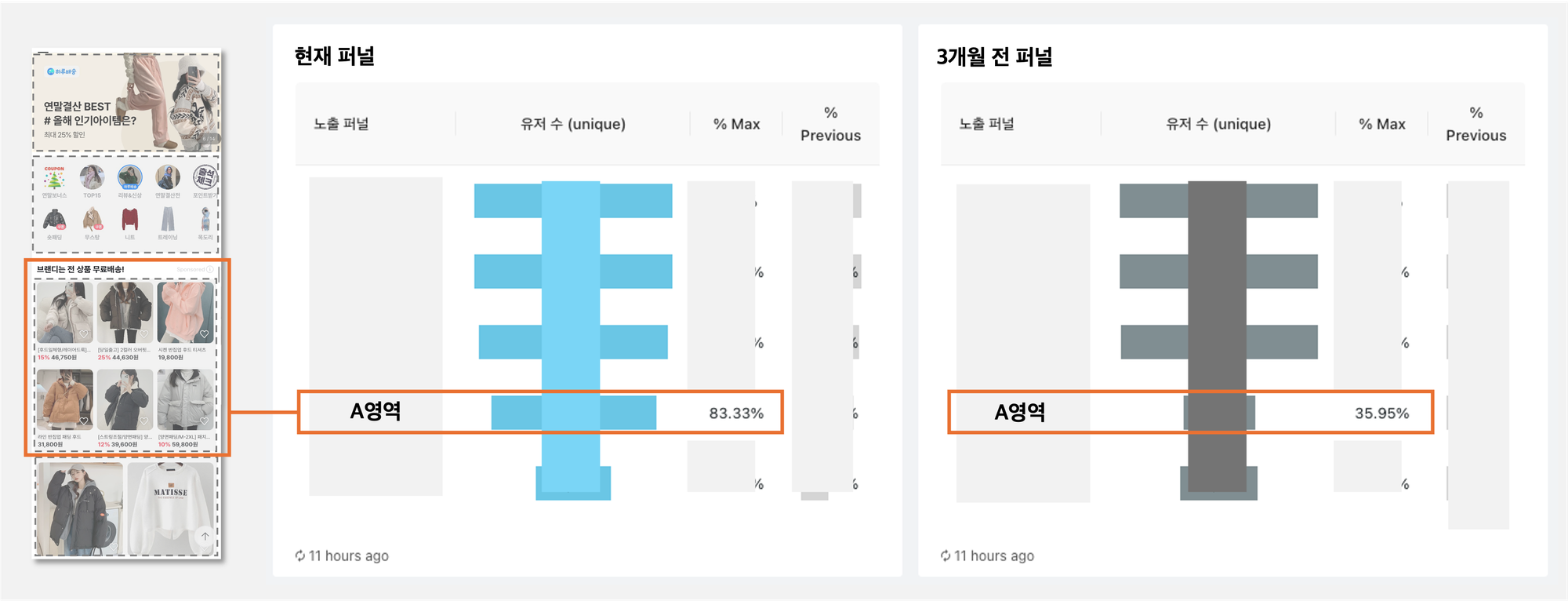
(2) 검색 및 추천 최적화 반영
검색 대시보드의 경우, 검색 팀내 피드백을 반영하여 검색 주요 지표 모니터링을 진행하고 있습니다. 그래서 슬롯 정책 변경으로 2024년 1월 말 대비 2주 평균 매출 21% 매출 상승, 3월에는 40%까지 매출 증가가 예상됩니다. 또한 CTR 및 검색 관련 지표의 추이를 확인한 결과 슬롯 정책 변화와 고객의 피드백 데이터 사이에 큰 차이가 없었습니다.
추가적으로 페이지 간의 관계성과 조닝 내 상품 진열에 대한 고객의 반응을 종합적으로 파악할 수 있었습니다. 트래픽을 많이 발생시키는 주요 페이지의 특징을 통해 검색 최적화 및 개인화에 대한 방향성을 잡을 수 있습니다.
(3) 새로운 앱 내 기능 도입 예정
앞에서 말씀드린 것처럼 회사의 비즈니스는 디스플레이 광고와 검색 결과 광고를 포함하는 리테일 미디어(Retail Media)를 포함하고 있습니다. 체류시간이 지속적으로 감소하는 현상 발견 이후, 이를 기반으로 새로운 앱 내 기능을 도입할 예정입니다.
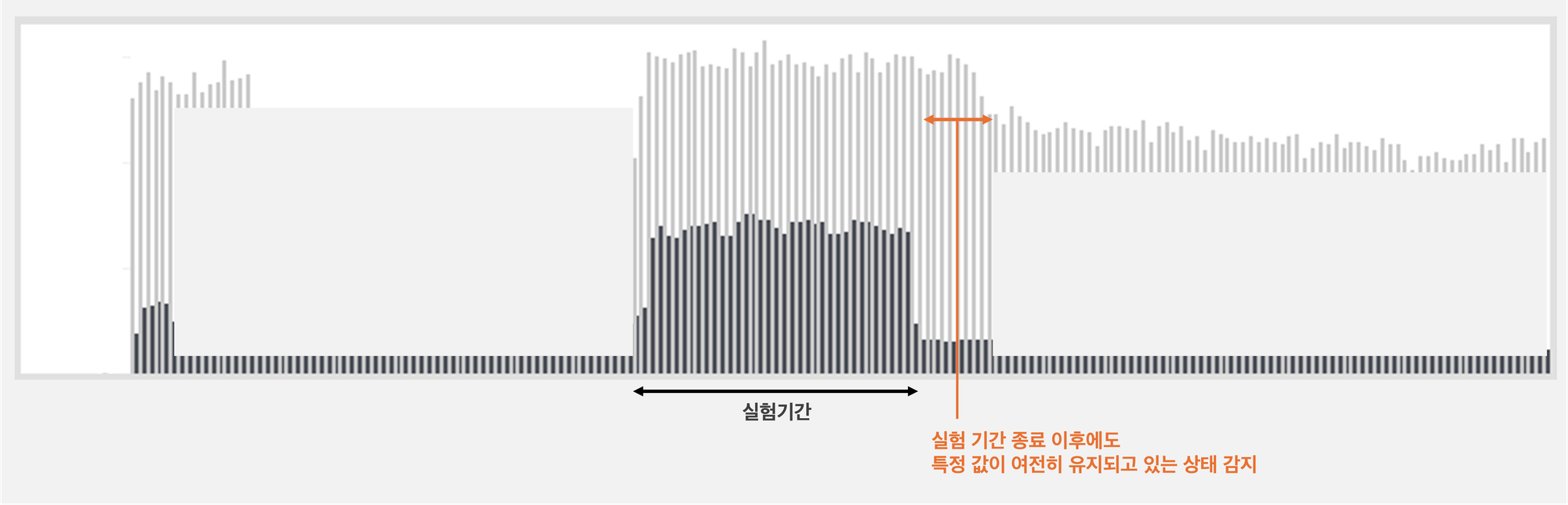
(4) 실험 비즈니스 로직 관련 이슈 발견 후 해결
“글의 초입에서 말씀드렸던 실험 결과, 비즈니스 로직을 제거하지 않기로 결정”했다고 말씀드린 바 있는데요. 실험 기간이 끝났는데도 실험 관련 로직이 포함된 채로 상품이 송출되고 있음을 발견했습니다. 이 문제를 대시보드를 통해 발견하고 즉시 수정함으로써 이슈를 빠르게 발견하고 해결할 수 있었습니다.
🎾 개선할 점은 무엇인가요?
지금까지 지표를 개발하고 데이터 파이프라인을 구성하고 최종적으로 대시보드를 만들어 수익을 창출한 과정을 말씀드렸습니다. 여기에는 몇 가지 남아있는 과제가 있습니다.
(1) 유저 세그멘테이션 모델이 반영된 세부 분석
현재 저희팀은 CRM 최적화 태스크를 위해 ML 모델을 도입 중에 있는데요. 구체적으로 구매 확률 예측 모델, RFM 그리고 상품 소재에 반응하는 유저 세그멘테이션 모델을 도입 중입니다. 대시보드에서도 도입된 ML 모델과 유저의 피드백 데이터를 활용해 세그멘테이션 별 세부적인 코호트 분석이 필요합니다.
현재 대시보드는 현황을 파악하고 문제를 발견하는 데에 초점이 맞춰져 있습니다. 위와 같이 다양한 코호트별 퍼널 분석 등 세분화된 분석이 추가된 이후에는 문제의 원인까지 파악할 수 있는 대시보드가 될 것입니다.
(2) 주요 페이지 및 조닝의 특성에 맞는 추천 최적화 및 세부 분석
주요 페이지를 분석하면서 같은 고객도 세션 및 맥락에 따라 다른 행동을 하는 것을 발견할 수 있습니다. 그래서 추천 모델 및 비즈니스 로직이 결합한 상품 진열과 고객의 피드백 데이터 사이에 어떤 관련성이 존재하는지를 지표를 통해 확인해야 합니다. 발견되는 지표를 통해 주요 조닝의 추천 모델을 최적화하여 고객에게 보다 나은 상품을 먼저 제공할 수 있습니다.
(3) Data Quality System
현재는 발생 가능한 정형 데이터와 비정형 데이터가 Data Lake에 모두 적재되는 구조입니다. 데이터 품질을 항상 체크하고 데이터 파이프라인 관련 이슈 발생시 빠르게 오류의 원인을 파악하는 것이 중요한데요. 현재는 운영을 하면서 빈번하게 다운 타임이 증가한 영역에 대한 부분적 데이터 검증(Data Validation)을 진행하였습니다. 이 부분을 확장하여 데이터 적재부터 고객의 피드백 과정까지 발생할 수 있는 미묘한 데이터 오류 부분을 빠르게 파악하고 대응할 수 있는 시스템이 필요합니다.
(4) 저희가 운영하고 있는 다른 서비스로 확장
현재 지표 기획, 데이터 파이프라인, 그리고 자동화 대시보드 제작은 브랜디 서비스를 대상으로 진행했습니다. 추후 운영하고 있는 다른 서비스로 확장이 필요합니다.
PS.지표를 기획하고 대시보드를 자동화하는 과정에서 도움 주시고 조언해 주신 AI검색팀과 데이터 개발팀에 감사드립니다. 그리고 플랫폼 관점에서 중요한 피드백을 주신 TECH 플랫폼 조직 상근님께 감사드리며 글을 맺습니다.
Reference
- 이커머스 데이터 분석과 개선을 위한 작은 실험(팀 내부 프로젝트)
- RFM 분석 적용 내용(팀 내부 프로젝트)
- CRM 최적화 프로젝트 - 쿠폰 발급 최적화(팀 내부 프로젝트)
- How to do data quality with DataOps
- How we deal with Data Quality using Circuit Breakers
- The New Rules of Data Quality
- A Deep Dive Into Data Quality
- 3 Steps to Improve the Data Quality of a Data lake
- How to monitor Data Lake health status at scale
- Automated Data Quality Testing at Scale using Apache Spark
- Testing data quality at scale with PyDeequ
- Implementing Data Quality with Amazon Deequ & Apache Spark
- python-deequ github
- Time Series Aggregations with Core PySpark
- Data Quality — You’re Measuring It Wrong
- Data Quality at Airbnb
- Analytics ICON
- Funnel Chart - Suggested Alternatives
- 7 Data Storytelling Techniques to Build Dashboards That Engage your Customers
- AARRR 의미 자세히 파헤쳐보기(퍼널 분석 이미지 출처)
최정현 | Tech Data AI검색 개발팀



