깃발 올려, Git Effect!
Git의 특징과 Hashing
오연주
2018-02-26
안녕하세요, 개발 2팀에서 단아함을 맡고 있는 오연주입니다. 평소에 관심이 많았던 깃(Git)을 공부하면서 알게 된 내용들을 글로 쓰려고 합니다. ‘어떤 닝겐이 만들었나’ 궁금할 정도로 천재적인 깃은 도대체 누가 만든 것일까요? 바로 리누스 토발즈(Linus Torvalds)입니다. 이름에서부터 OS의 느낌이 가득합니다. 네, 맞습니다. 그는 리눅스(Linux)의 창시자이기도 합니다. 리누스는 말했죠.
“My name is Linus, and I am your God.”

그가 깃을 만들기 전에는 보통 중앙집중식 VCS(Version Control System)를 사용했었습니다. 예를 들면 다음과 같은 도구들로요.
- CVS
- SVN(Subversion)
- …
반면에 깃은 분산 버전 관리 시스템(DVCS, Distributed Version Control System)입니다. 그렇다면 중앙집중식의 대표주자인 Subversion(VCS)에 비해 무엇이 더 좋을까요?
- 속도가 빠르다.
snv logsvn diff -rNsvn commit등 대부분의 명령어가 네트워크 연결이 되어야 실행 가능한 명령어입니다. 그러나git pushgit clone등 몇몇 명령어를 제외하고는 네트워크에 연결되어 있지 않아도 로컬에서 실행할 수 있습니다. - 용량이 적다.
Mozilla의 SVN Repository는 126GB인데 반해 Git Repository은 420MB입니다. 왜냐하면 해쉬, 스냅샷을 이용한 효율적인 파일 변화 관리가 가능하기 때문입니다. - 브랜치를 만드는 작업이 수월하다.
SVN은 diff를 전부 적용해서 파일을 생성한 뒤 네트워크에서 내려받는 반면, 깃은 스냅샷을 가리키는 링크(Commit Object)만 만들면 됩니다.
어떠한 특징을 가지고 있길래 이런 차이점이 생기는 걸까요?
- 분산 저장소로, 로컬에서도 중앙 저장소와 연결되지 않은 상태에서 지지고 볶기가 가능하다니!
여러 개의 다른 저장소를 생성할 수 있고 서로서로 연결되어 독립적으로 개발 프로젝트를 진행할 수 있고 유기적인 업데이트가 가능합니다. - 델타 기법이 아닌 스냅샷 방식을 사용합니다.
SVN의 경우 파일 변화를 diff로서 추적한 반면, Git은 각 시점의 파일 상태를 모두 스냅샷을 찍어 관리합니다.
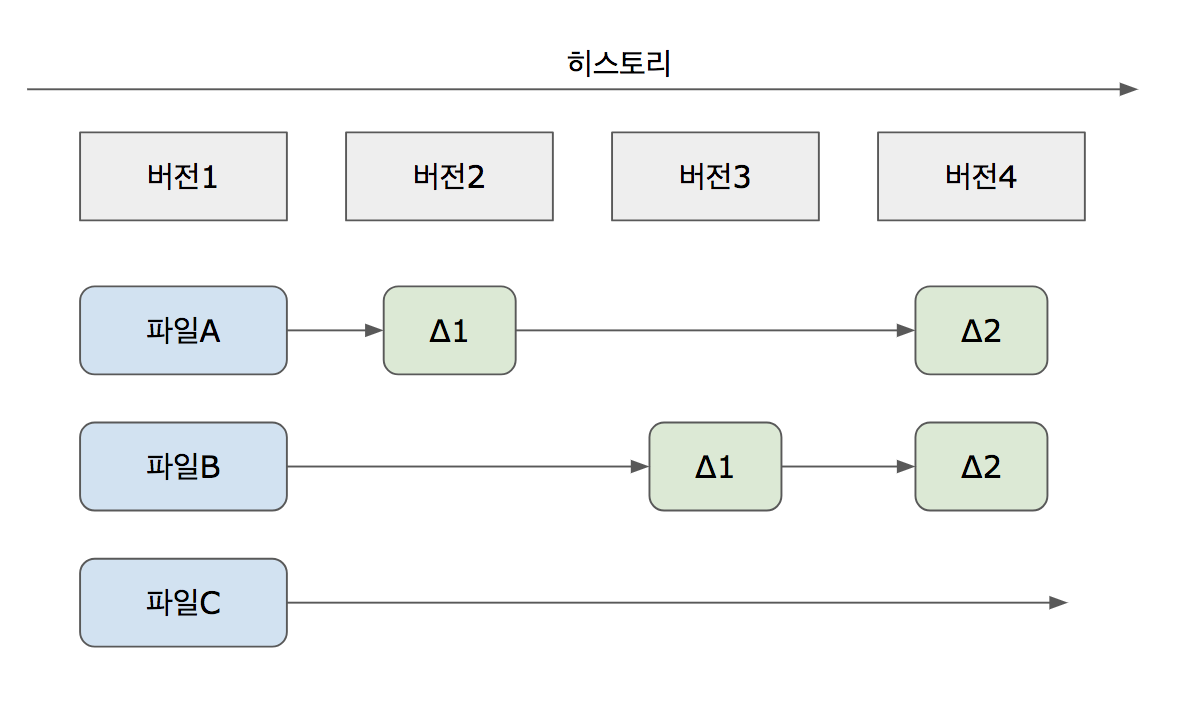
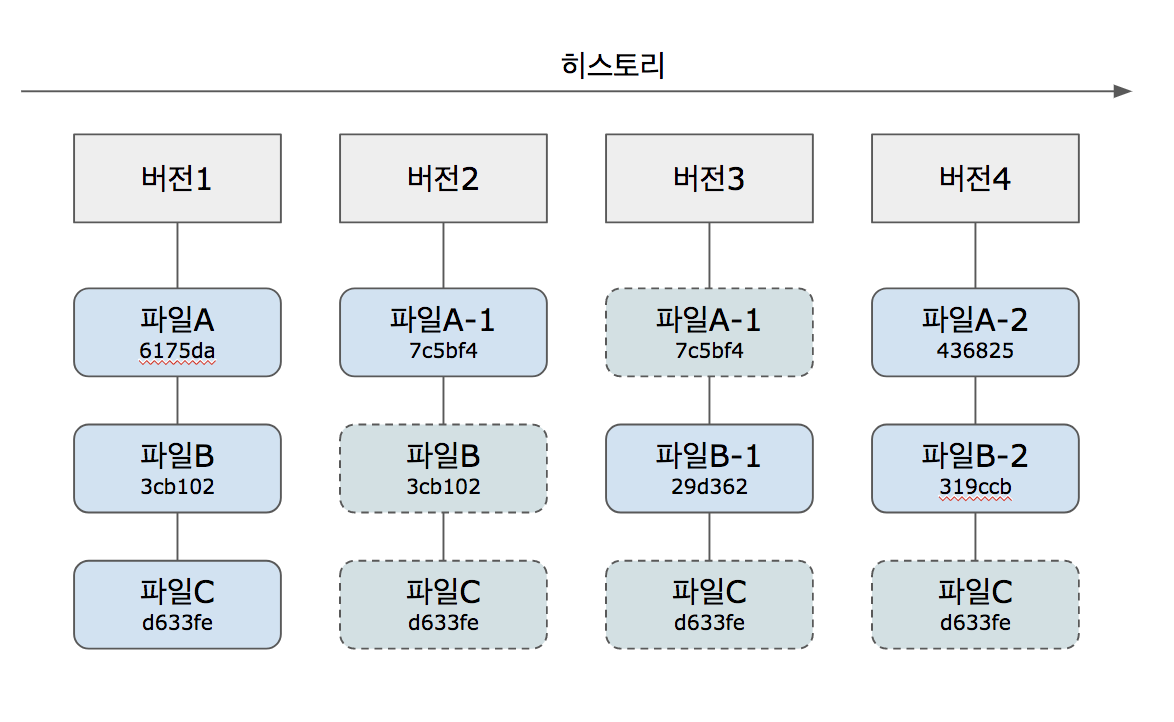
두 가지 특징을 살리려면 깃이 여타 다른 VCS와는 다른 방식으로 정보를 관리할 필요가 있습니다. 예를 들어 Revision number로 히스토리를 관리했던 Subversion으로 분산된 저장소의 히스토리를 관리하려고 하면 ‘시점 충돌’ 문제가 발생합니다.
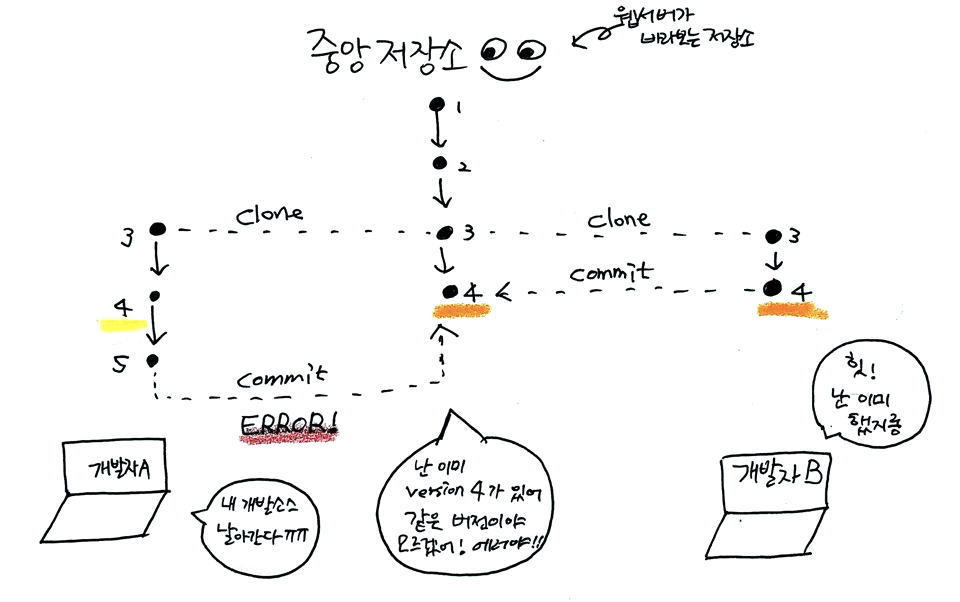
금융 프로젝트에 참여했을 때의 일입니다. VCS 중 H사 툴을 사용하였는데 한 소스의 버전을 받고 개발하는 과정에서 커밋의 횟수가 많아지니 중앙 저장소 입장에서는 ver 1 → ver 9로 갑자기 타임워프하는 일이 생겼습니다. 그래서 개발자 스스로 본인의 버전을 모두 삭제한 후 ver 9였던 파일을 수동으로 ver 2로 바꿔주는 것이 관례였습니다. 소스가 모두 날아가는 경우가 있어 소스 commit 과정이 공포스러웠죠. 깃은 해쉬(hash)를 이용한 정보 관리를 통해 이런 문제를 말끔하게 해결합니다.
Git의 핵심, 정보 Hashing!
git reset --hard 3269aecad9ffea81763a42b9fff34c76a0aa4cf0
브랜디 소스 코드를 pull 했는데 특정 시점으로 돌아가 할 일이 생겨 위의 명령어를 입력했던 적이 있습니다. 명령어로 깔끔하게 원하는 시점으로 되돌아올 수 있었죠. 뒤에 붙는 40자리의 기괴한 문자열은 바로 깃이 정보를 관리하는 데에 사용하는 해쉬값입니다. 해쉬값이 제일 많이 보이는 곳은 git log 가 아닐까 싶은데요.
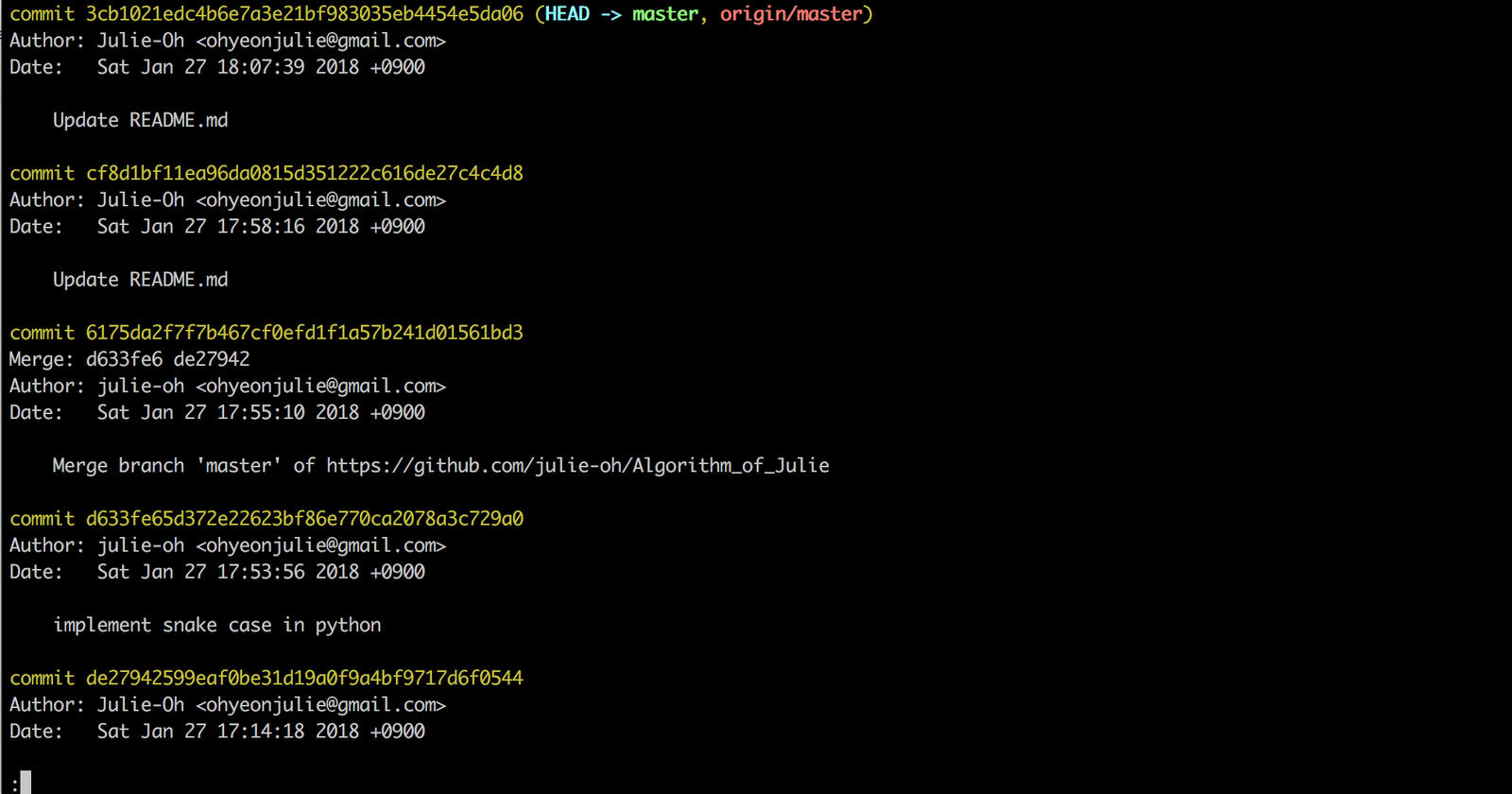
깃은 소스 코드를 포함해서 히스토리를 관리하는데 필요한 모든 정보를 이런 해쉬로 저장 및 관리합니다. 이 해쉬값은 40자리 16진수 숫자이며 SHA-1 알고리즘으로 생성됩니다. SHA-1 알고리즘은 보안 표준 해쉬 알고리즘 중 하나입니다. 충돌할 확률은 1 / 10^45로, 매우 매우 낮기 때문에 수많은 정보를 저장 및 관리하기에 안전하고 적합합니다.


앞서 SHA-1 해쉬값으로 모든 정보를 저장한다고 말씀드렸는데, 과연 어떤 정보를 어디에, 어떻게 저장하고 있는 것일까요? 각 해쉬 값은 깃이 내부적으로 저장하는 파일 이름이 되기도 하는데, 이 파일들은 .git/objects 경로에서 전부 찾아볼 수 있습니다.
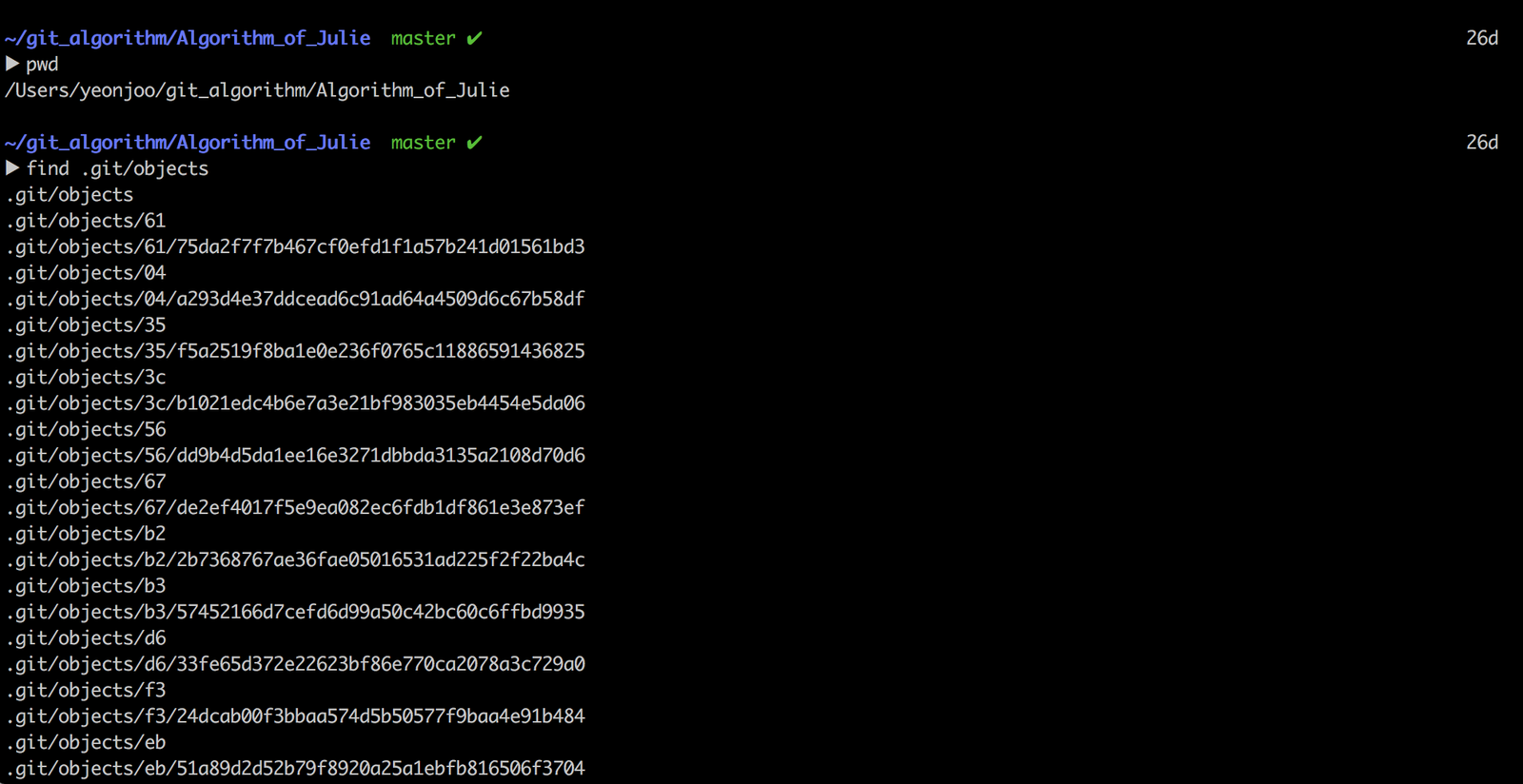
해쉬값 40자리 중 앞 2자리를 디렉토리 이름으로 따고, 뒤 38자리를 파일 이름으로 지정합니다. 각 파일 안에는 서로 다른 정보가 담겨 있습니다. 해쉬값으로 표현되는 이 파일들은 정보의 종류에 따라 3가지 객체로 분류됩니다.
- Blob Object
- Tree Object
- Commit Object
폴더나 파일명이 어떤 오브젝트인지 힌트를 주지 않기 때문에 세 가지의 오브젝트 파일 내용의 캡처를 위해 복불복으로 열어봤는데요, 하나의 파일을 열 때마다 포춘쿠키를 까듯 심장이 쫄깃쫄깃했습니다.
Blob Object란 실제 파일을 뜻하며, 실제 소스파일을 가지고 있는 실세 오브젝트같은 느낌입니다.
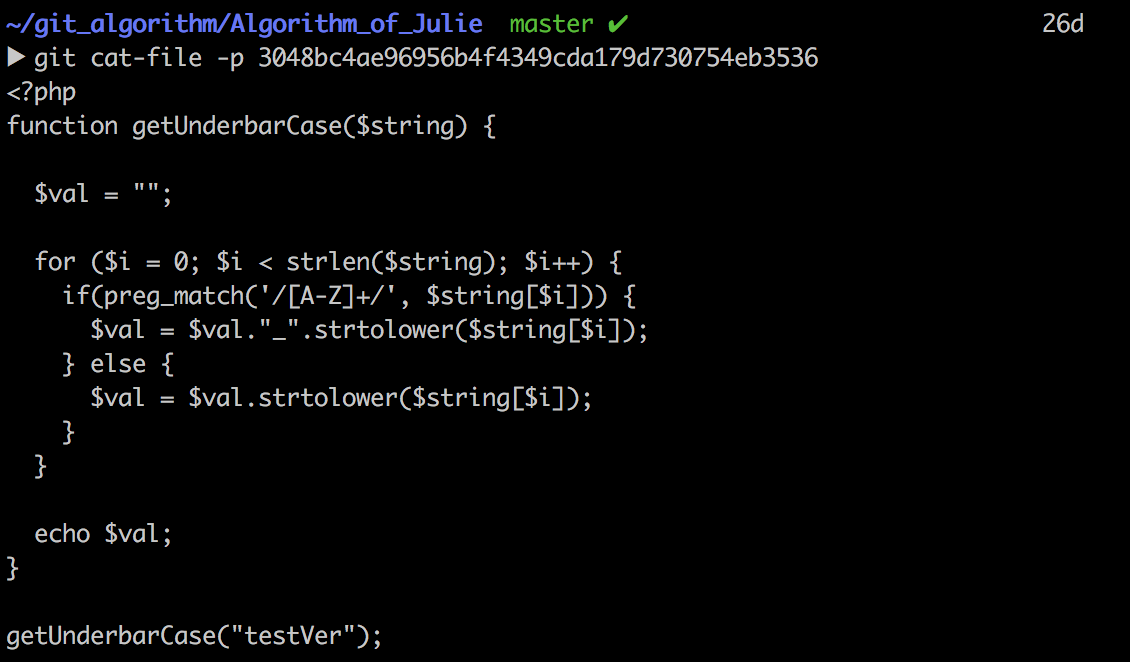
Tree Object 내부에는 프로젝트 구조의 각 디렉토리에 대한 정보가 담겨 있습니다. 하위에 어떤 폴더와 파일을 가지고 있는지 알려주고, 객체 해쉬 값을 저장하고 있습니다. 이 Tree Object의 제일 상위 객체는 root이며, 프로젝트의 최상위 폴더에 대한 정보를 담게 됩니다.
앞서 깃은 각 시점별 스냅샷을 찍어 관리한다고 했습니다. 스냅샷을 찍는 행위는 새로운 Root Tree Object를 만들고, 각 시점에 가지고 있는 Tree Object와 Blob Object로 새로운 트리 구조를 만드는 과정입니다.

Commit Object는 커밋 시점의 Repository Root Directory의 해쉬 값을 가지고 있는 녀석입니다. Parent는 내 커밋 전에 커밋이 누구인지를 뜻하는데요. 또한, 커밋할 때의 committer(user), commit message등의 정보도 가지고 있습니다.
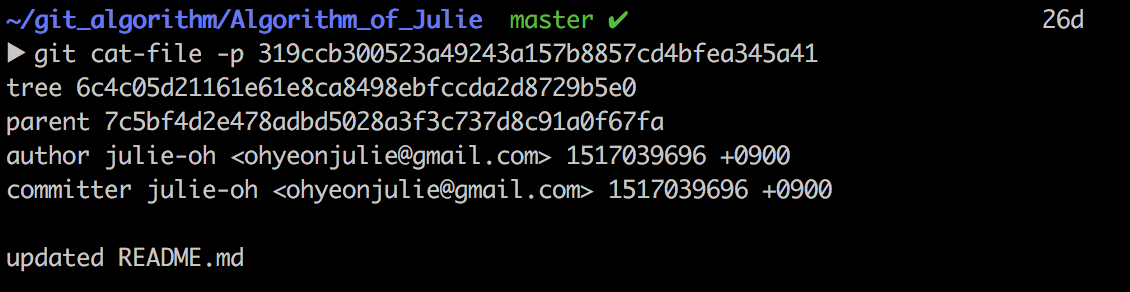
세 종류의 객체는 깃이 분산된 Repository 간의 소스 히스토리를 쉽게 관리하도록 도와줍니다. 해쉬값으로 관리되기 때문에 특정 스냅샷에 이동하거나, 히스토리를 변경 또는 추가하는 데에 적은 리소스만 필요합니다. 또 분산된 저장소 사이에 상호 시간 순서에 대한 모호함도 해결할 수 있었습니다. 이 정도면 갓누스….
깃을 공부하기 시작한 이유는 Git UI Tool을 쓰면서 습관적으로 commit, push 버튼을 눌렀기 때문입니다. 깃에 대한 이해도가 있는 상태에서 사용한다면 실수가 줄어들 거라 생각합니다. 다음 글은 Git branching Model을 다루겠습니다.
ps. Git, 협업과 원활한 커뮤니케이션을 위해 알고 씁시다! 우리 함께 깃빨 받읍시다!!
참고
- Scott Chacon and Ben Straub, ⌈Pro Git, 2nd Edition⌋, Apress(2014)
- Schneier on Security
- Probability of SHA1 collisions, stack overflow
- SVN 능력자를 위한 git 개념 가이드, Insub Lee, Slide Share
오연주 | 데브옵스팀
ohyj@brandi.co.kr



