개발1팀의 AWS Personalize 도전기
상시요청과 위메프 상품연동과 11번가 상품연동과 브랜디 스프린트와 병행하기
곽정섭
2019-10-04
INTRO
요즘 서비스들을 이용하면 사용자 개인에 초점을 맞춘 ‘개인화&추천’ 기술을 흔히 접할 수 있습니다. 단순히 인기 콘텐츠를 추천해주는 것 보다 개인의 취향 및 성향을 기반으로 콘텐츠를 추천해주었을 때 소비자의 만족도가 높다는 것은 이미 많은 연구 결과를 통해 검증되었습니다.
하지만 기계 학습을 바탕으로 개인화&추천 기술을 개발한다는 것은 대부분의 조직에는 멀게만 느껴졌습니다. 우리가 원하는 대로 결과가 잘 나올 것인지, 서비스에 접목했을 때 제대로 퍼포먼스를 일으킬 것인지 등등 비용 대비 효율적인 방법을 찾는 데 많은 고민을 했습니다.
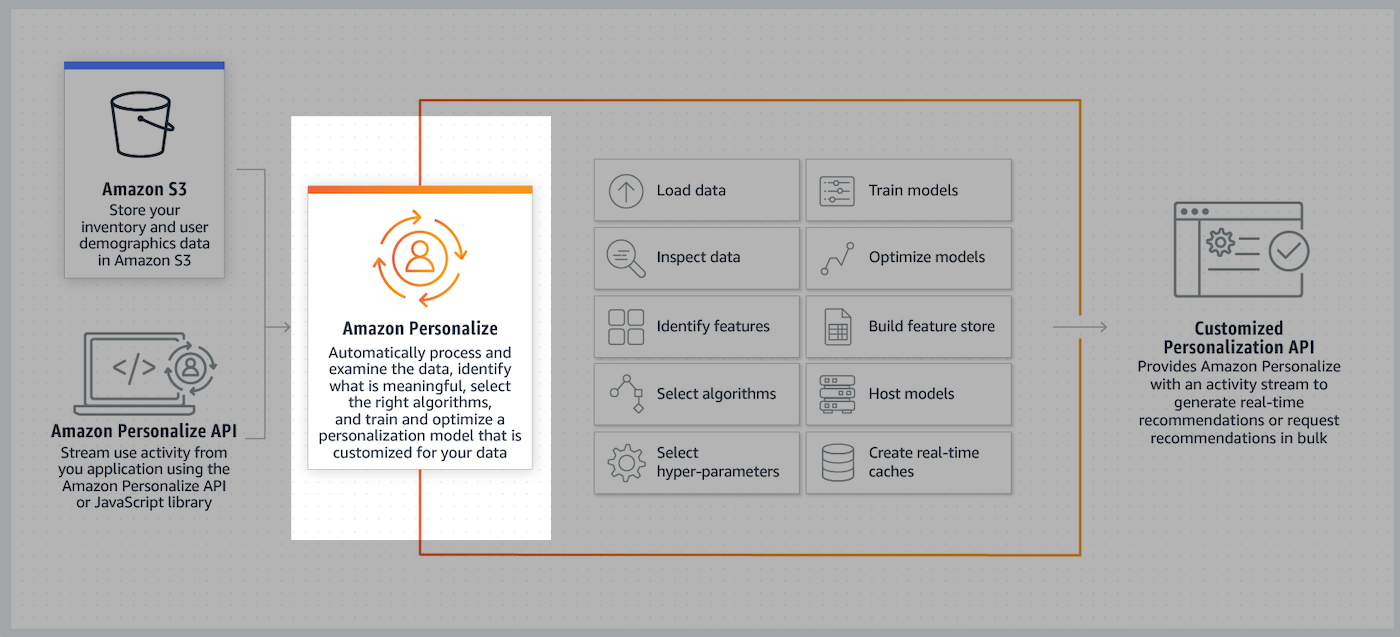
AWS Personalize(이하 Personalize)는 바로 이러한 부분을 해소해주기 위해 나온 서비스입니다.
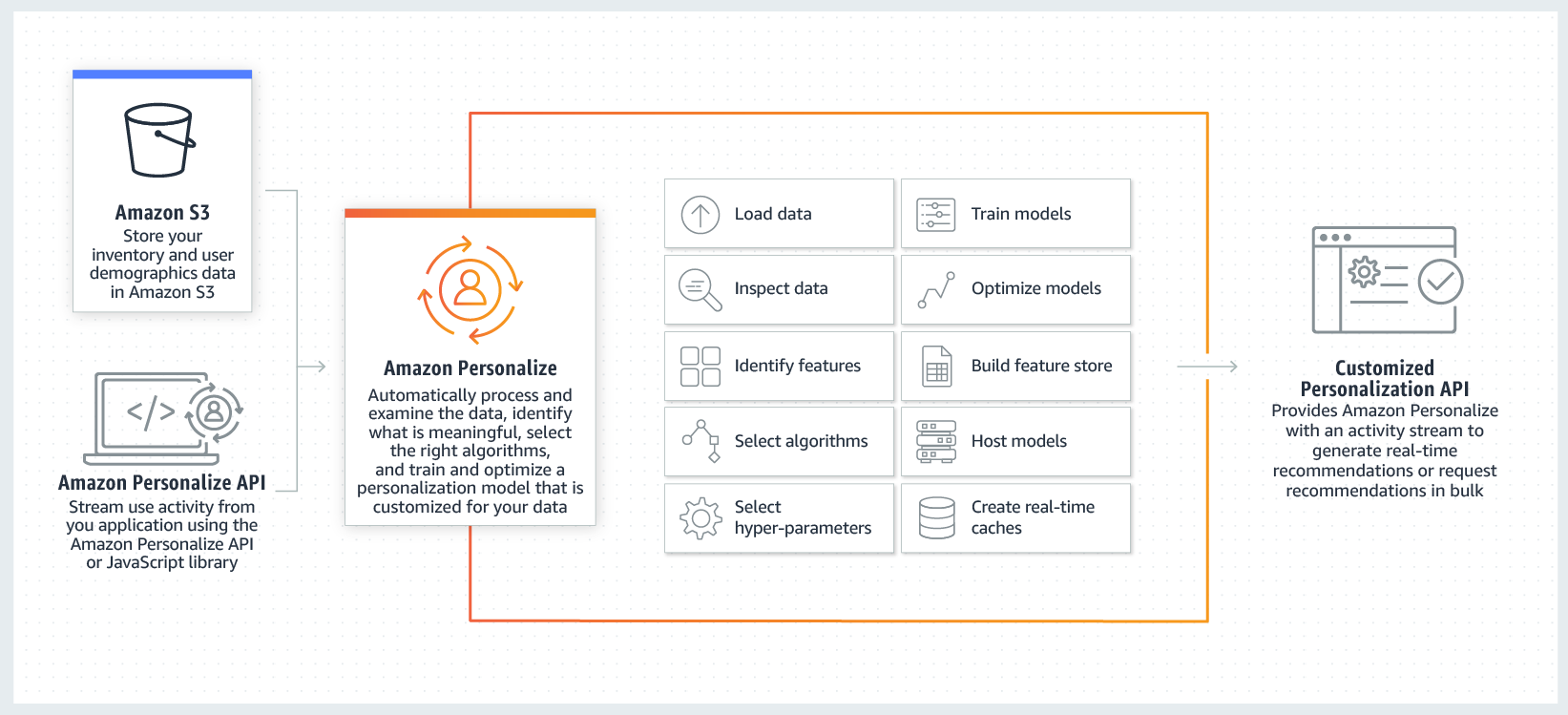
이번 시간에는 Personalize를 이용하여 사용자에 개인화된 상품을 추천하고, 그것을 기반으로 한 ‘상품 인기 순위’를 얻어보도록 하겠습니다.
레츠 고! 🤜
목차
-
STEP1: 학습 데이터 준비하기
- 1-1. S3 Bucket을 통해 과거 데이터 제공하기
-
STEP2: 학습시키기
-
2-1. 데이터 세트 생성
-
2-2. 추천 레시피를 선택하여 솔루션 생성
-
2-3. 캠페인 생성
-
-
STEP3: 실시간 데이터 수집하기
-
3-1. 이벤트 트래커 생성
-
3-2. 샘플 코드 생성
-
STEP1: 학습 데이터 준비하기
기계 학습의 궁극적인 목표는 과거와 현재의 데이터를 가지고 미래를 예측하는 것입니다. Personalize가 높은 수준의 분석 결과를 도출할 수 있도록 우리는 학습 데이터를 준비해야 합니다. Personalize에게 학습 데이터를 제공하는 방법은 2가지가 있는데요. 먼저 S3 Bucket을 통해 과거 데이터 부터 제공을 해보겠습니다.
1-1. S3 Bucket을 통해 과거 데이터 제공하기
먼저 과거 데이터를 업로드 할 S3 Bucket을 생성하고 Personalize가 접근할 수 있도록 정책을 설정해줍니다.
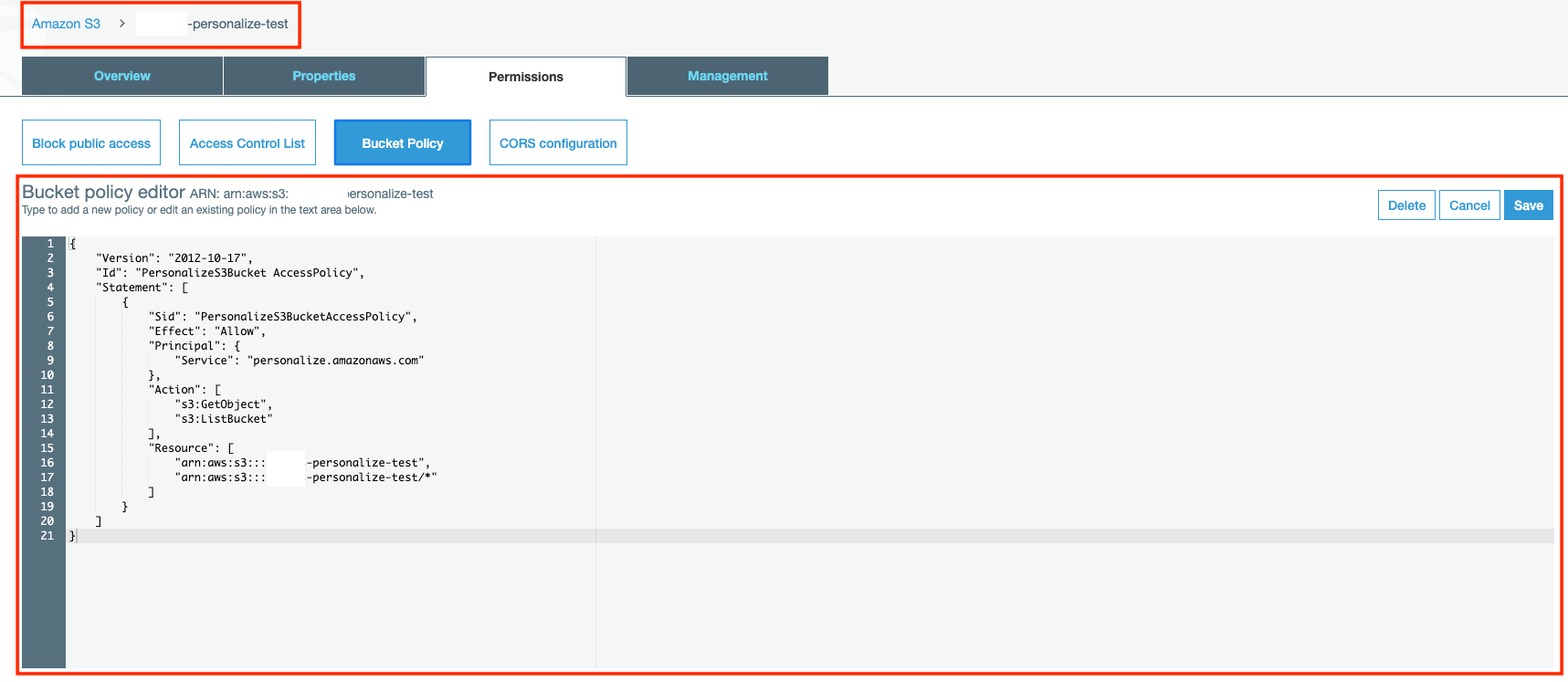
이제 과거 데이터만 업로드를 해주면 되는데요, 여기서 꼭 주의해야 할 점이 있습니다.
과거 데이터는 CSV 파일이어야 하고 첫 행은 데이터 세트의 스키마와 일치해야 합니다.
갑자기 나타난 데이터 세트는 무엇이고 스키마는 무엇일까요? 🤔 이것은 다음 STEP에서 차근차근 알려드릴 테니 우선은 넘어가도 좋습니다.
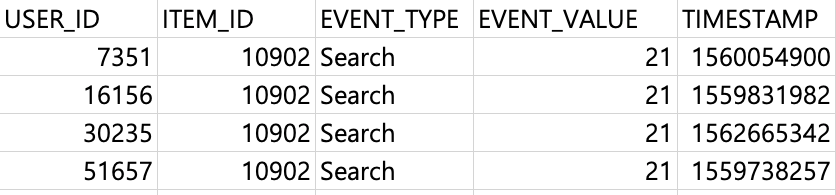
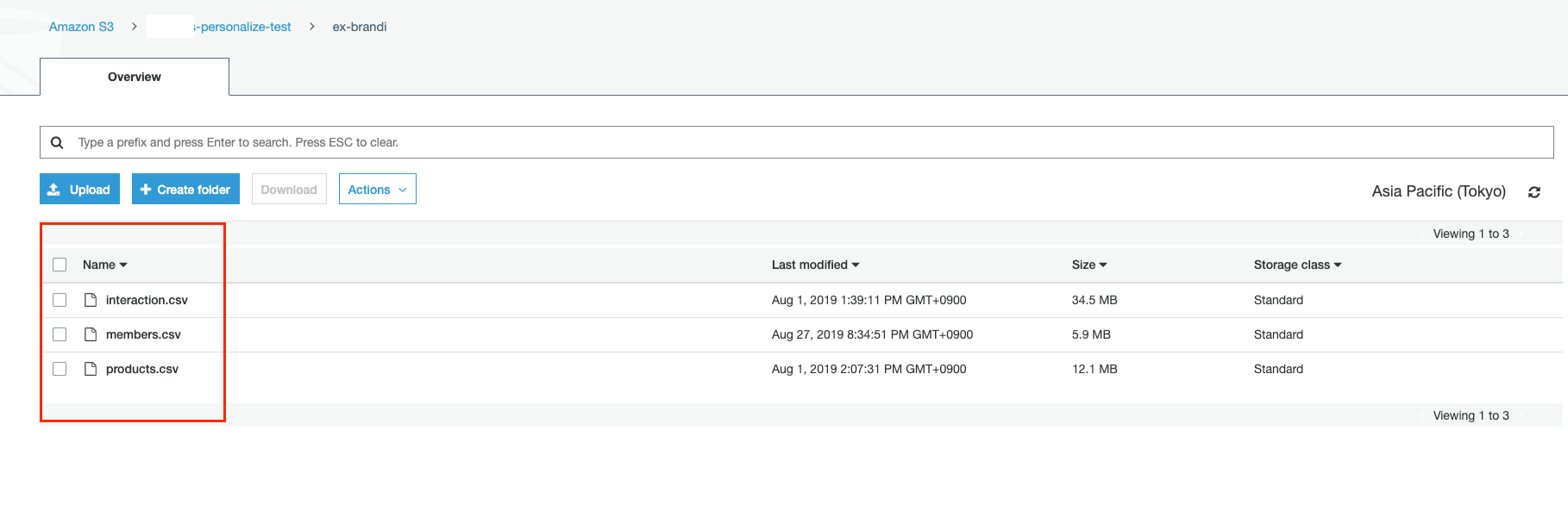
User-to-Item 상호작용 데이터(interaction.csv)와 각각의 메타데이터(members.csv , products.csv)를 업로드 했습니다. 이 3가지의 파일을 가지고 Personalize는 우리가 원하는 결과를 도출할 수 있게 열심히 학습할 것입니다. 🤓
STEP2: 학습시키기
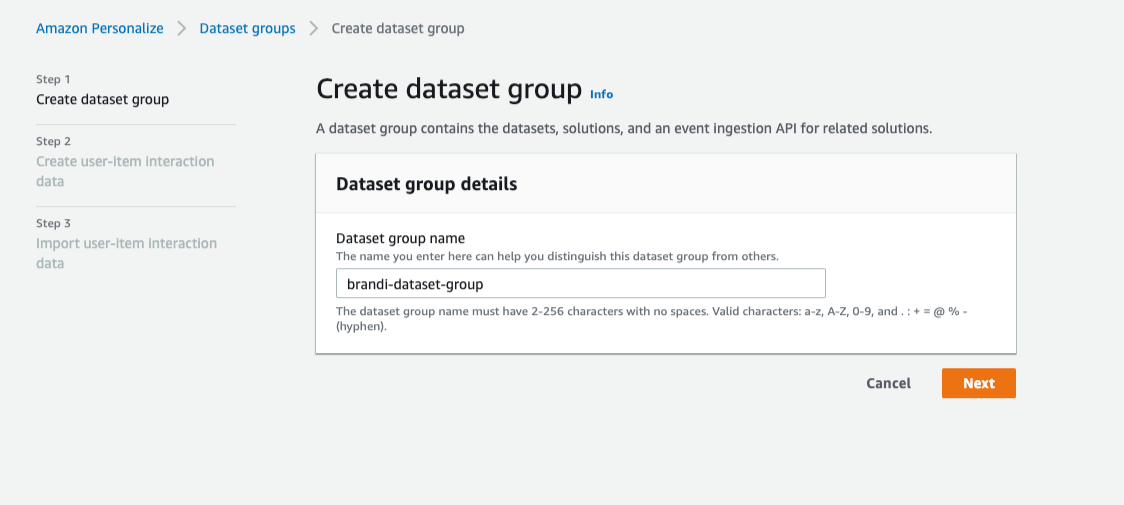
2-1. 데이터 세트 생성
우리가 방금 만들어 놓은 3개의 과거 데이터는 각각의 데이터 세트가 될 수 있습니다. 쉽게 말하면 csv 파일은 아주 기본적인 골격만 맞추어진 로우 데이터(raw-data)이고 데이터 세트는 Personalize가 실제로 읽고 학습할 수 있는 형태의 데이터라고 이해하면 됩니다.
이 데이터 세트들을 묶을 수 있는 데이터 세트 그룹을 먼저 생성합니다.
[Next] 버튼을 누르면 아래와 같이 바로 데이터 세트를 생성할 수 있는 화면이 나옵니다.
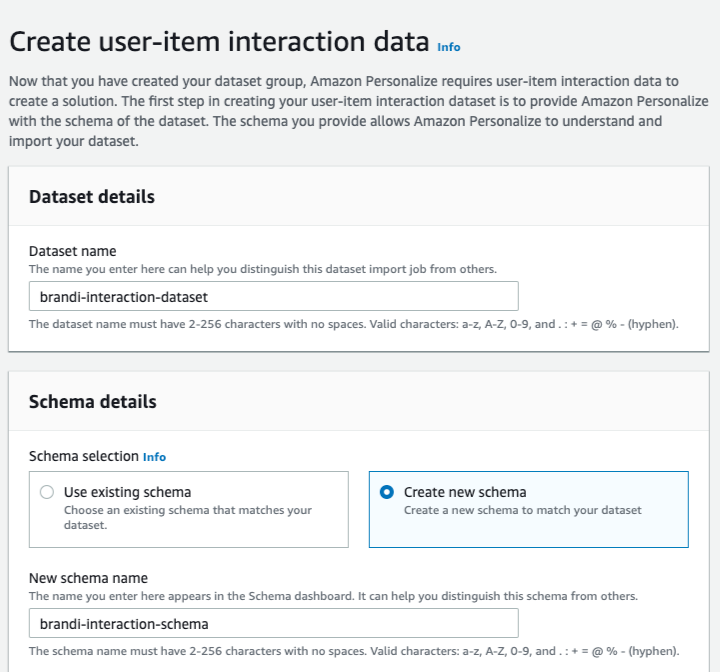
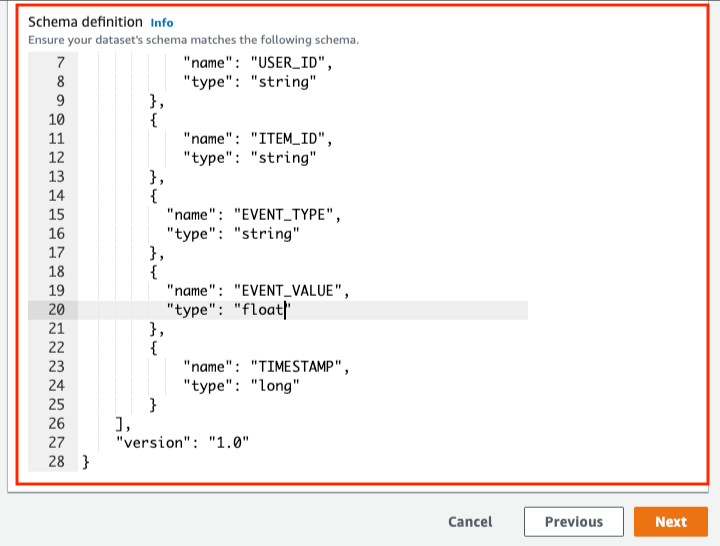
(참고. 2019년 9월 2일 기준 AWS Personalize 개발자 안내서의 예시에는 EVENT_VALUE의 type 이 ‘string’ 으로 나와 있으나 실제로는 type이 float가 아닐 경우 에러가 발생한다.)
이 화면에서 가장 중요한 부분이 바로 스키마 정의(Schema definition) 입니다. STEP1에서 과거 데이터를 업로드할 때 꼭 주의해야 할 점 기억하시나요?
과거 데이터는 CSV 파일이어야 하고 첫 행은 데이터 세트의 스키마와 일치해야 합니다.
저 주의사항을 지키지 않으면 데이터 세트는 생성되지 않습니다. 그뿐만 아니라 사용하는 레시피에 따라 반드시 선언되어야 할 스키마나 데이터 타입이 정해져 있기 때문에 제대로 인지한 후에 데이터 세트를 생성하도록 합니다. (그렇지 않으면 [Next] 버튼을 영원히 누를 수 없습니다!)
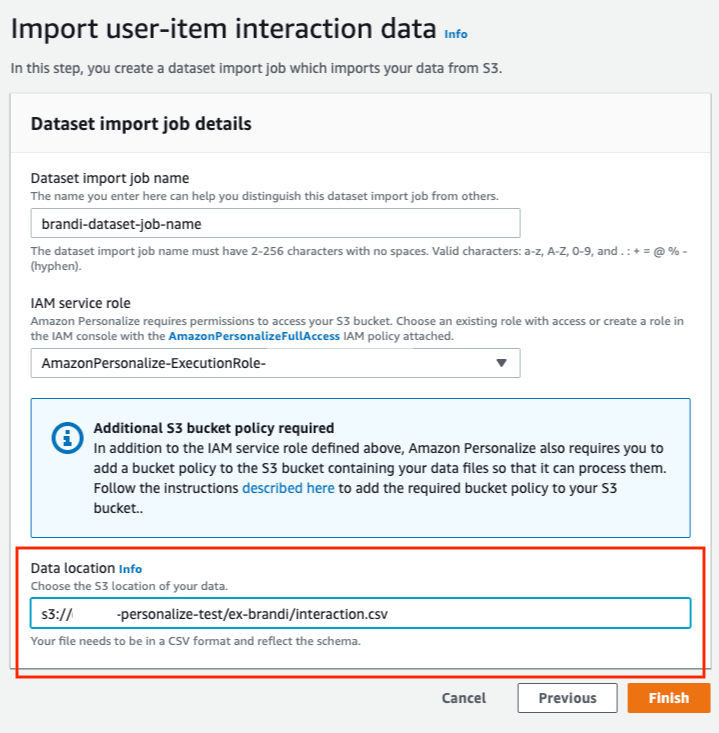
마지막으로 과거 데이터의 S3 Bucket 경로를 지정해준 후 [Finish]를 클릭합니다.
(나머지 2개의 메타데이터도 동일한 방식으로 데이터 세트를 생성합니다.)
2-2. 추천 레시피를 선택하여 솔루션 생성
개인화&추천에 사용되는 알고리즘은 여러 가지가 있지만, 기계 학습에 대해 잘 모르는 사람에게는 적절한 알고리즘을 선택 후 구현을 하는 것이 어렵습니다. 하지만 Personalize는 상황별로 적절한 알고리즘을 제공해줘서 우리는 선택만 하면 됩니다. 이것을 레시피(Recipes)라고 하고 이것을 사용하여 교육된 모델 결과물이 바로 솔루션(Solutions) 입니다.
AWS 에서 제공하는 레시피는 아래와 같고, 더욱 자세한 설명은 ‘AWS Personalize 개발자 안내서’ 에서 확인할 수 있습니다.
-
USER_PERSONALIZATION 레시피
사용자가 상호 작용할 항목을 예측합니다.- HRNN : 사용자-항목 상호 작용의 시간적 순서를 모델크할 수 있는 계층적 반복 신경망입니다.
- HRNN-Metadata : 사용자 및 항목 메타데이터(사용자 및 항목 데이터 세트)와 함께 상황별 메타데이터(상호 작용 데이터 세트)에서 파생된 추가 기능이 포함된 HRNN입니다.
- HRNN-Coldstart : HRNN 메타데이터와 비슷하게 새 항목들을 개인 설정에 따라 탐색합니다. 카탈로그에 새 항목을 자주 추가하며 항목을 권장 사항에 즉시 표시하려는 경우에 권장됩니다.
- Popularity-Count : 사용자-항목 상호 작용 데이터 세트에서 해당 항목에 대한 이벤트 수를 기반으로 항목의 인기도를 계산합니다. 다른 사용자-개인화 레시피를 비교할 때 기준으로 사용합니다.
-
PERSONALIZED_RANKING 레시피
결과를 개인 설정합니다. 맞춤화된 순위검색 결과 또는 선별된 목록의 개인 설정된 순위 재결정과 같이 사용자의 결과를 개인 설정할 때 이 레시피를 사용하십시오. -
RELATED_ITEMS 레시피
주어진 항목과 유사한 항목들을 예측합니다.- SIMS : 항목 간 유사점(Item-to-item Similarities, SIMS)은 사용자-항목 상호 작용 데이터 세트의 사용자 기록에 있는 해당 항목의 동시 발생에 근거하여 주어진 항목과 유사한 항목들을 생성합니다. 항목에 대한 사용자 동작 데이터가 충분하지 않거나 지정된 항목 ID를 찾을 수 없는 경우, 알고리즘은 인기 항목을 권장 사항으로 반환합니다.세부 정보 페이지에서 사용하거나 항목 검색 가능성을 개선하는 데 사용합니다. 빠른 성능을 제공합니다.
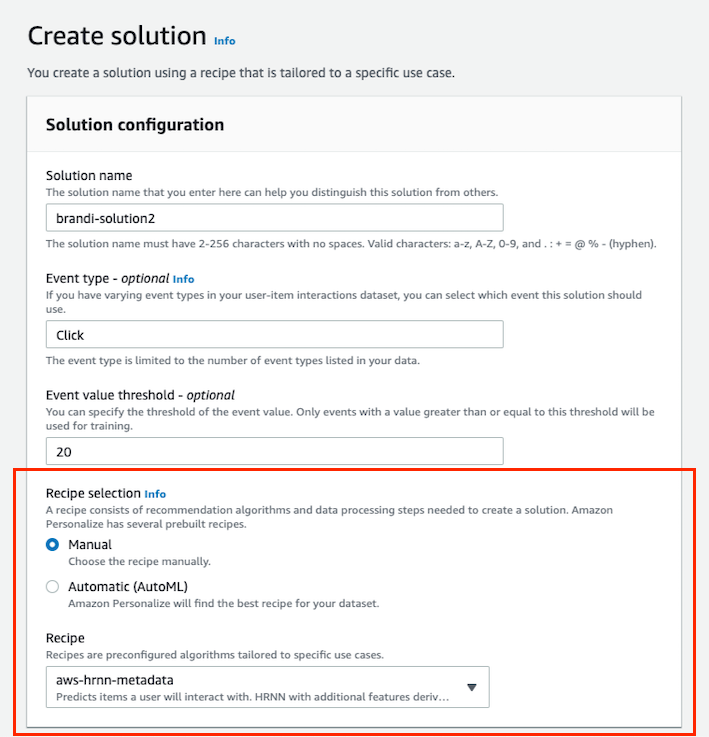
- Solution name (필수) : 솔루션을 구별하기 위한 이름입니다.
- Event type (선택) : 다양한 이벤트 유형(ex. Click, Search)이 있는 경우 필요한 이벤트를 선택합니다.
- Event value threshold (선택) : 이벤트값의 임계 값을 지정합니다. 이것을 설정해 두면 임계 값보다 크거나 같은 이벤트만 학습합니다.
- Recpe selection (필수) : AWS에서 제공하는 레시피를 선택합니다.
우리는 먼저 User-to-Item 상호작용인 추천 상품을 얻어야 하므로 ‘aws-hrnn-metadata’를 선택 후 [Next]를 클릭합니다.
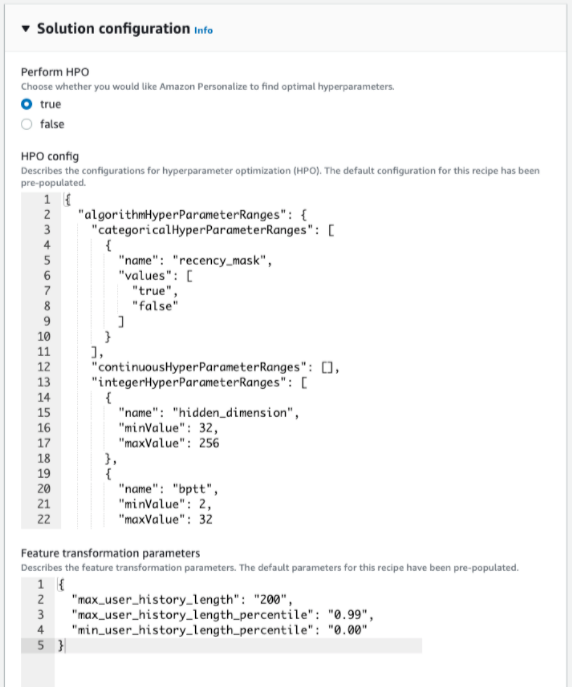
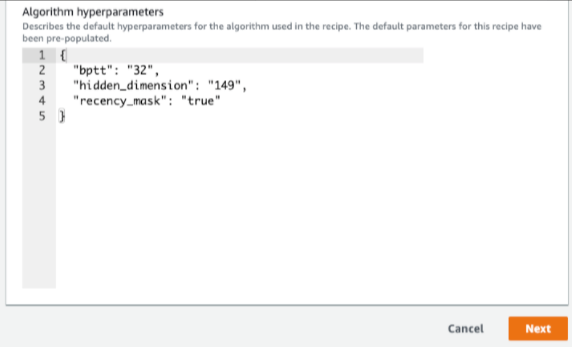
하이퍼파라미터 최적화(이하 HPO) 화면입니다. 기계 학습을 할 때 관련 전문가들은 성능 또는 학습 결과물을 최적화시키기 위해 HPO를 합니다. 기본적으로 Personalize에서는 HPO를 수행하지 않지만 사용하고 싶을 경우에는 performHPO를 true로 설정하고 hpoConfig 객체를 포함해야 합니다.
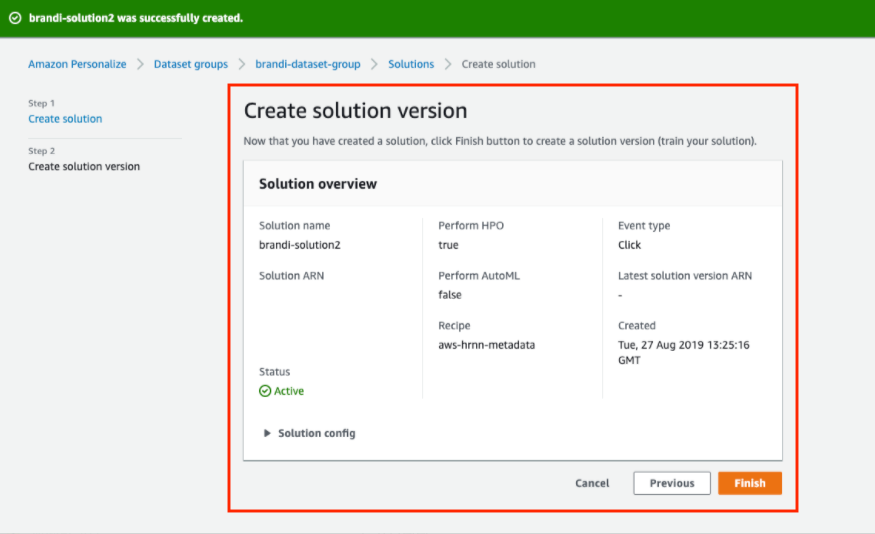
드디어 솔루션 생성까지 완료되었습니다! 하지만 바로 솔루션을 배포하고 사용할 수 있는 것은 아닙니다. Personalize가 학습을 다 완료할 때까지는 꽤 오랜 시간이 소요되므로 그 동안에는 다른 업무를 보면 됩니다. 🏃♂️
2-3. 캠페인 생성
생성된 솔루션을 활용하려면 배포를 해야 하는데 이것이 바로 캠페인(Campaign) 입니다. 캠페인은 과거 데이터를 변경할 경우 재배포해야 하며 STEP3에서 다루게 될 실시간 이벤트 수집 시에는 해당하지 않습니다.
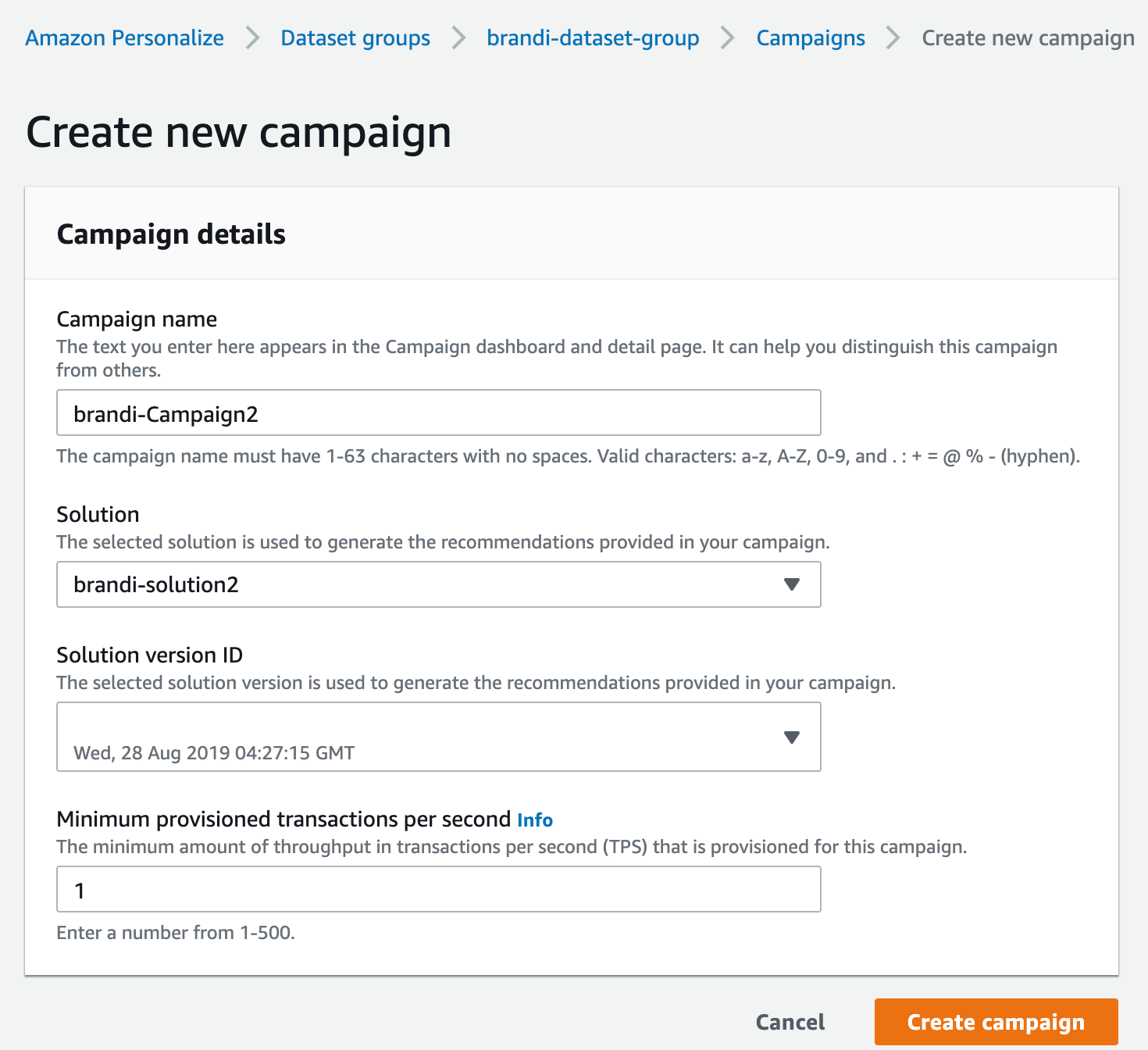
- Campaign name : 캠페인을 구별하기 위한 이름입니다.
- Solution : 캠페인에 제공되는 권장사항을 생성하는 데 사용합니다.
- Minimum provisioned transactions per second : 해당 캠페인에 프로비저닝 된 초당 트랜잭션(TPS)의 최소 처리량을 의미합니다.
설정 값을 입력 후 [Create campaign] 버튼을 클릭합니다.
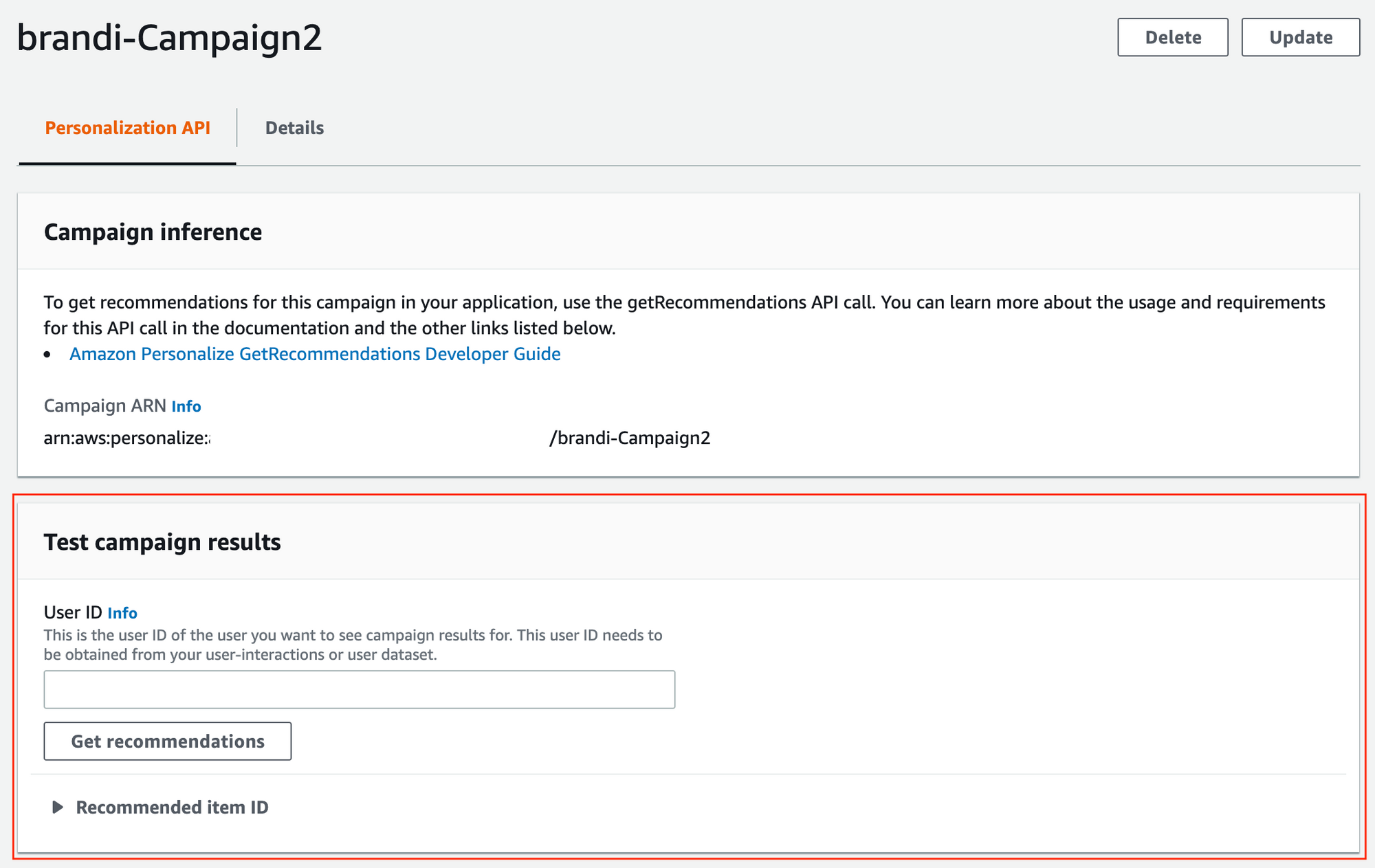
캠페인이 생성되면 AWS 콘솔을 통해 바로 사용자의 고유 값(USER_ID)을 입력함으로써 추천 상품 번호들을 (PRODUCT_ID)를 확인할 수 있습니다. 바로 이렇게 말이죠!
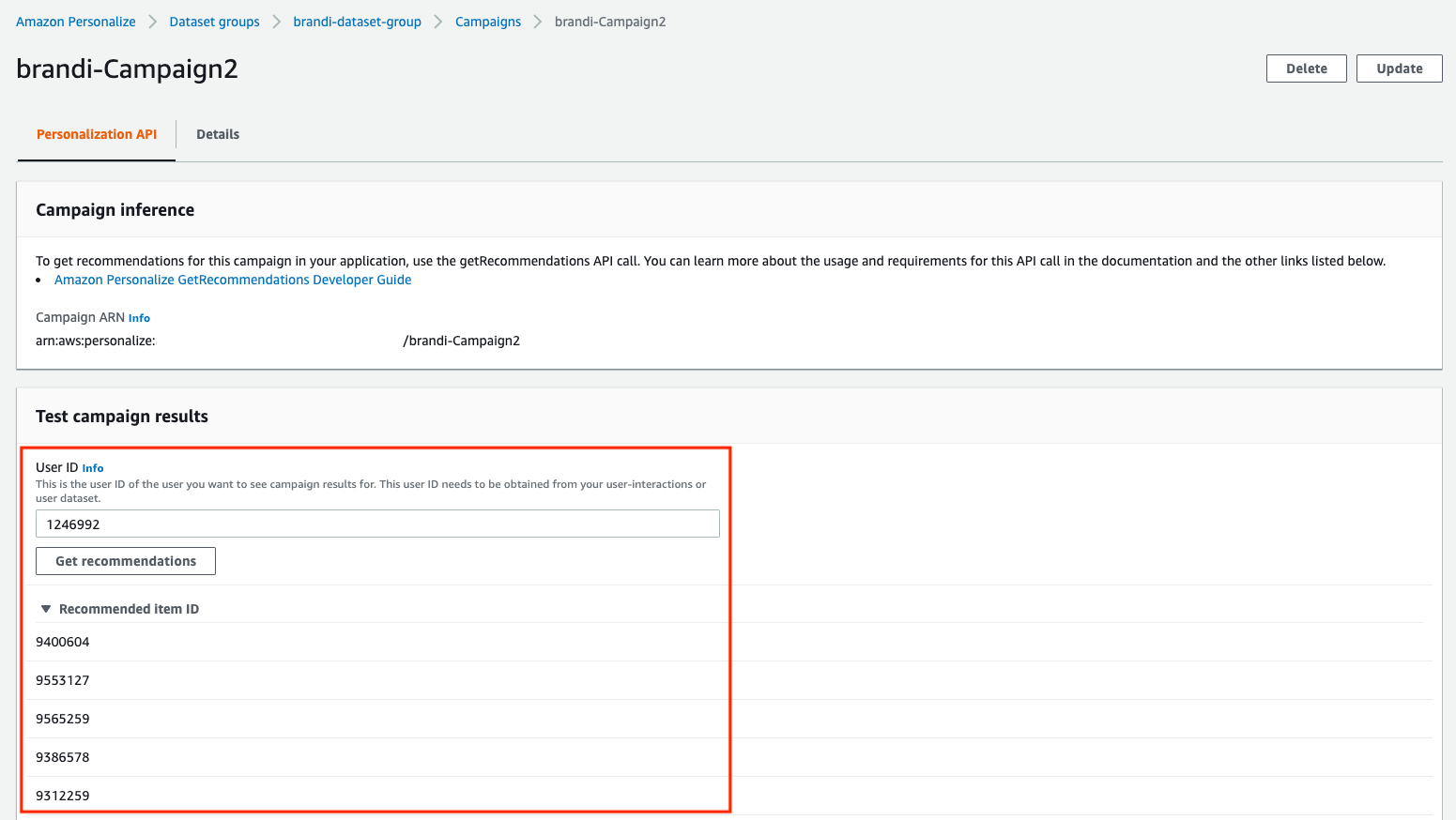
참 쉽죠?
추천 상품 결과를 얻었으니 이제는 이것을 기반으로 ‘순위’ 를 매겨 보도록 하겠습니다. 순위를 매기기 위해서는 ‘Personalized Ranking’ 레시피를 사용한 새로운 솔루션을 생성해야 합니다. 레시피만 다를 뿐 생성하고 배포하는 방식은 지금까지 한 것과 동일하기 때문에 이 글에서는 과정을 생성하고 바로 진행하도록 하겠습니다.
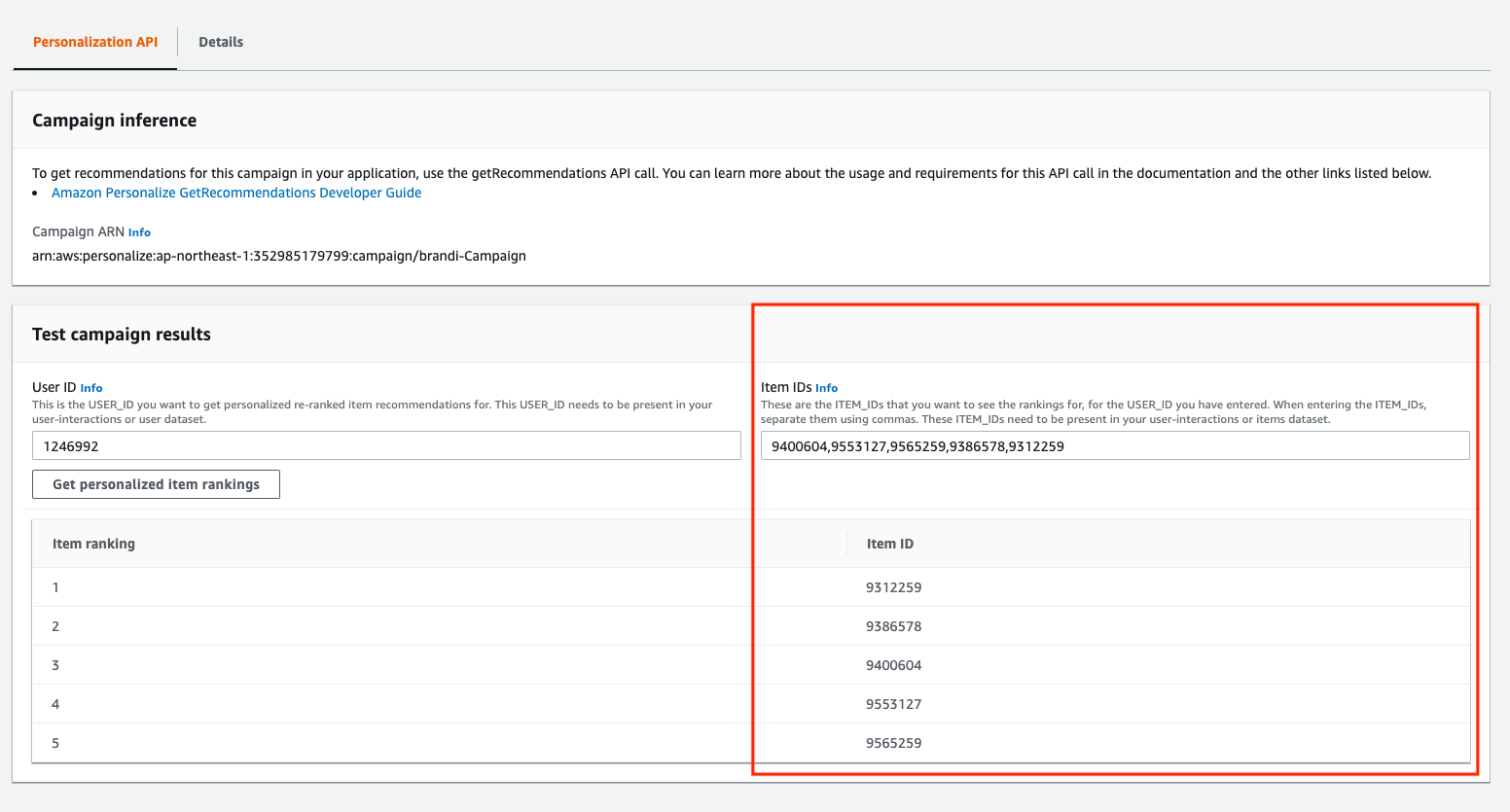
Personalized Ranking은 USER_ID와 특정 상품번호들(Item IDs)을 제공하면 해당 사용자에게 맞게 순위가 매겨집니다. 이 순위는 과거 데이터에만 의존하여 나온 결과물입니다. 다음 STEP3에서는 ‘실시간 데이터 수집’을 통해 순위가 바뀌는 것을 확인해 보도록 하겠습니다.
STEP3: 실시간 데이터 수집하기
STEP1에서 Personalize에게 학습 데이터를 제공하는 방법은 2가지가 있다고 알려 드렸습니다. 하나는 S3 Bucket을 이용해 과거 데이터를 제공하는 것이고, 나머지 하나는 바로 실시간 데이터 제공입니다. Personalize는 과거 데이터에만 의존하여 솔루션을 제공할 수도 있고 이벤트 수집 SDK를 사용하여 과거+실시간 데이터의 조합으로 솔루션을 제공 할 수 있습니다.
코드를 작성하기 전에 먼저 ‘Event tracker’ 를 생성합니다.
3-1. 이벤트 트래커 생성하기
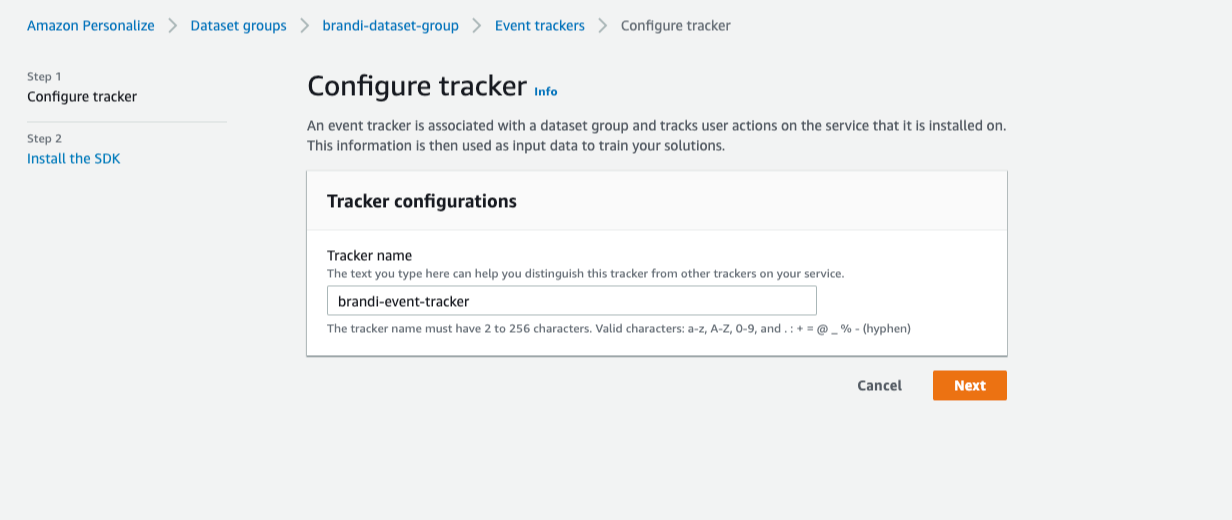
‘Event Tracker’는 첨부된 사진의 내비게이터에 보이듯 ‘Dataset groups’ 내에서 생성되기 때문에 간단히 이름만 지정 후 [Finish]를 클릭하면 손쉽게 실시간 데이터로 결과물에 영향을 줄 수 있습니다.
3-2. 샘플코드 작성하기
이제는 샘플 코드를 작성할 차례입니다. AWS SDK에서 제공하는 메소드와 파라미터만 제대로 지정해주면 Personalize가 다 알아서 하기 때문에 매우 짧고 간단한 코드입니다. 우리는 python SDK 모듈인 boto3를 사용하여 이벤트 발생 샘플 코드를 실행함으로써 상품 순위의 변화를 확인할 것입니다.
import boto3
import json
import time
timestamp = long(time.time())
personalize_events = boto3.client('personalize-events', 'ap-northeast-1')
data = personalize_events.put_events(
trackingId = 'XXXXXXXX-XXXX-abcd-efgh-12345678910', # 생성된 ID
userId = '1146992', # 사용자 ID
sessionId = 'session_id',
eventList = [{
'sentAt': timestamp, # TIMESTAMP
'eventType': 'Click', # 이벤트 유형
'properties': json.dumps({
'itemId': '9132854', # 수집 데이터
'eventValue': float('20') # 이벤트 값
})
}]
)
print(data)

샘플코드에 userId로 ‘1146992’, 상품번호 ‘9132854’를 넣고 몇 번 실행을 시켜주었습니다.
결과를 한 번 볼까요 ?
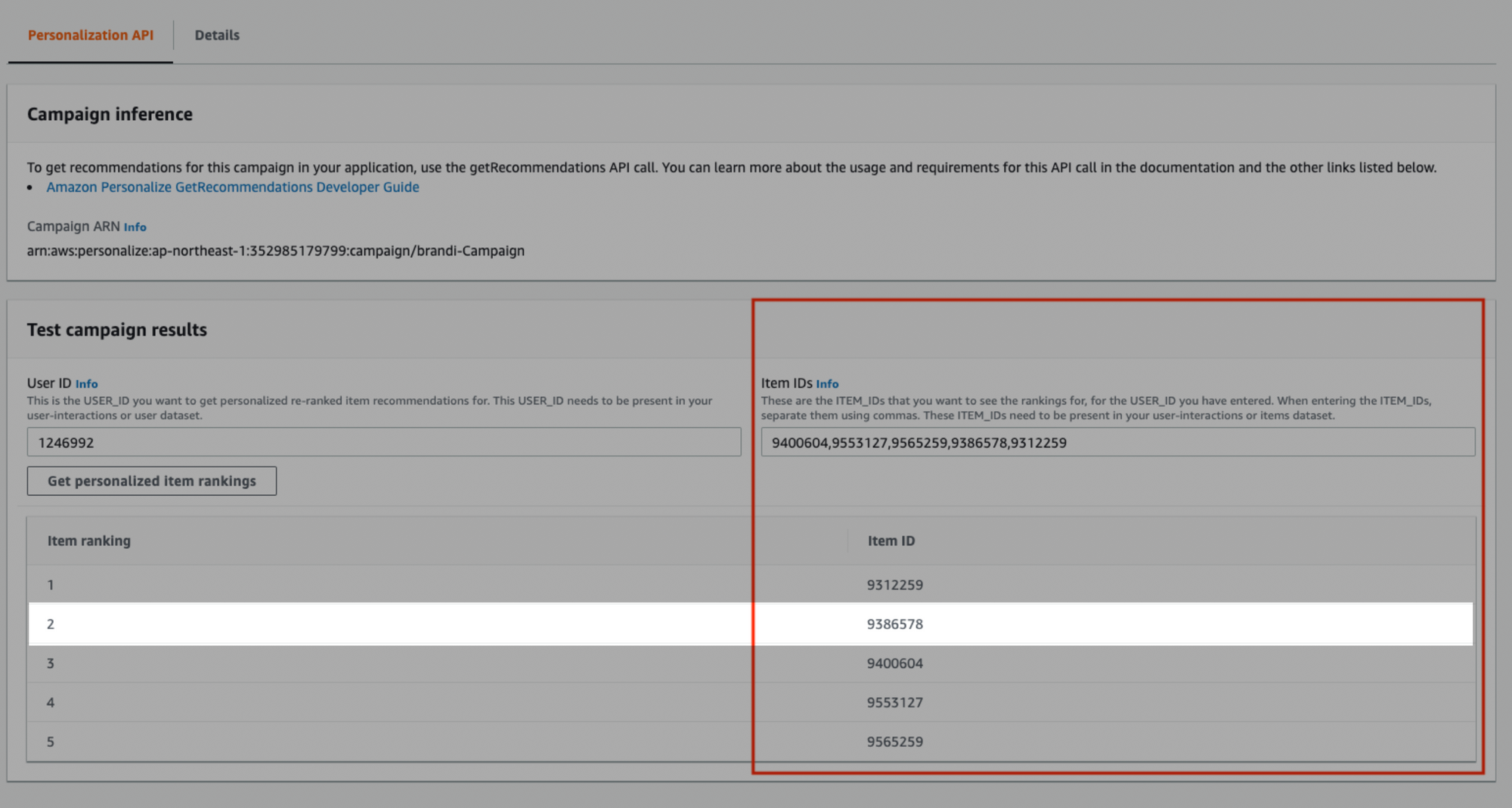
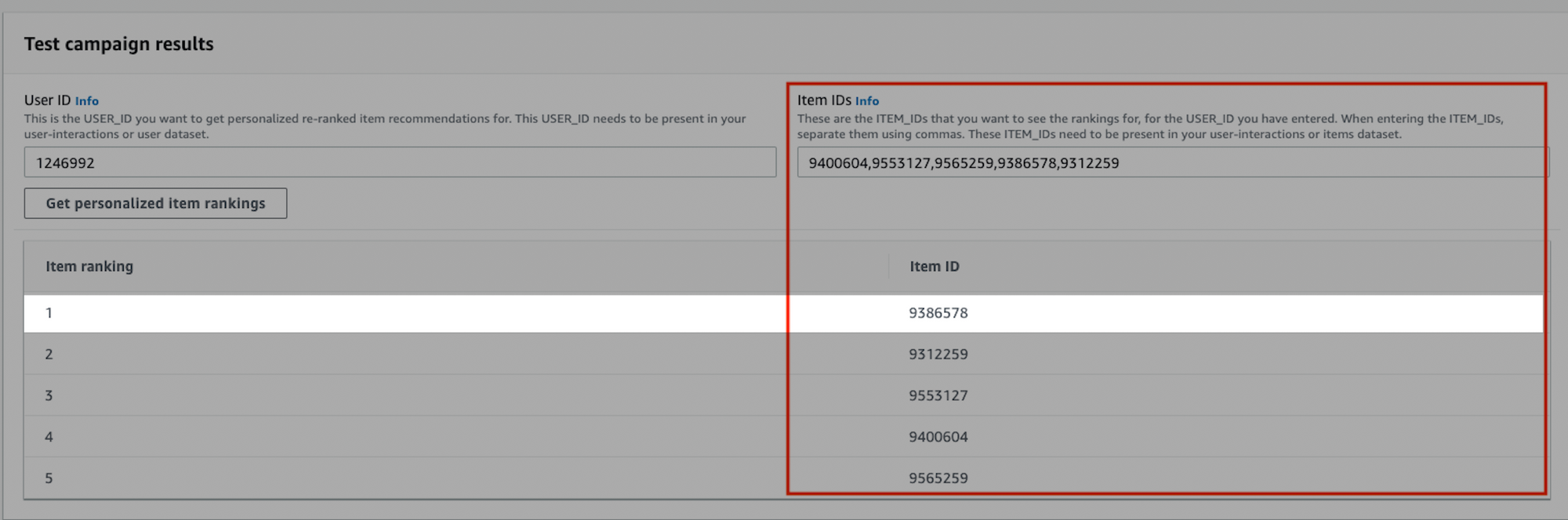
상품번호 Item ID ‘9386578’의 순위가 2위에서 1위로 올라간 것을 확인할 수 있습니다.
마무리
지금까지 AWS Personalize를 이용해 개인화 된 상품추천을 구현해보고 그것을 토대로 순위를 매겨보는 시간을 가졌습니다. Personalize 덕분에 우리가 과거 데이터와 실시간 이벤트 데이터만 제대로 준비, 제공하면 이렇게 쉽게 개인화 추천 기술을 누릴 수 있게 되었습니다.
하지만 순위를 매길 때 어떠한 조건에 대해 ‘가중치’를 준다든지, 좀 더 자유로운 형식으로 스키마를 생성한다든지 등등 커스텀 할 수 있는 부분이 많이 없어 아쉬움이 있었습니다. 그리고 사용자 입장에서 데이터만 제공해준 뒤 만들어져 있는 알고리즘으로 결과물을 얻기 때문에, 우리가 원하는 방향대로 결과물이 나왔는지 정확도와 신뢰도를 판단하는 데 시간을 더 투자해야 한다는 생각을 했습니다.
개발 1팀은 ‘일단은 해보자!’는 마음으로 매주 공부를 하고 의견을 나누는 시간을 가졌는데요. 이제는 더욱 심도 있게 접근하여 서비스에 적용 할 고민을 해봐야겠습니다. 😁
참고
https://optinmonster.com/ecommerce-personalization-examples/
https://swalloow.github.io/pyml-intro1
https://docs.aws.amazon.com/ko_kr/personalize/latest/dg/working-with-predefined-recipes.html
곽정섭 | 커머스 개발팀
kwakjs@brandi.co.kr



