서비스 캐싱 적용
이상근 실장
2020-01-14
Overview
서비스의 규모가 커지고 이용자 수가 늘어날수록 데이터의 양은 급증하게 됩니다. 이에 따라 발생하게 되는 서비스 지연을 감소시키기 위해 브랜디 개발팀은 오늘도 파이팅 하고 있습니다! 👨💻👩💻이번 시간에는 매일 예쁜 옷을 신속하게 제공할 수 있도록 브랜디 서비스의 캐시 범위를 확장 적용한 내용을 정리해 보려고 합니다.
참고
- 적정 수준 이상의 성능이 나온다면 구현 이후 최대한 관리가 필요하지 않을 방향으로 고민했습니다.
- 현재 사용량이 가장 많은 상품목록과 상품상세를 대상으로 적용하기로 했습니다.
- 본 글에서는 상품목록을 중점적으로 다루었습니다.
STEP1. 솔루션 검토
검토하기에 앞서 브랜디 홈 화면의 경우 이미 File Cache가 적용된 상태였습니다.
File Cache는 적용하기가 매우 간편하고 관리가 거의 필요하지 않다는 장점이 있으나 아래와 같은 문제점을 갖고 있습니다.
- 인스턴스 별로 각각 생성되어 관리되기 때문에 인스턴스의 수만큼 오리진 데이터 조회가 필요
- 동일 데이터에 대한 생성 시점 및 생명 주기가 일정하지 않아 서비스에 혼선이 생길 수 있음
이러한 문제점들은 상품목록에 적합하지 않다고 판단하였고, key-value 타입으로 운영할 수 있는 다른 방법을 찾아보기로 하였습니다.
- Redis용 AWS ElastiCache
- 인 메모리 위에서 동작하기 때문에 속도가 매우 빠른 강점이 있음
- 완전관리형 서비스이기 때문에 관리이슈가 거의 없으나 지속적인 모니터링 및 노드, 클러스터 관리 필요
- DynamoDB
- On-Demand 기능이 추가되어 처리량 관리가 필요 없음
- ElastiCache만큼은 아니더라도 10밀리초 미만의 성능을 제공
검토 결과, DynamoDB를 이용하여 캐싱을 적용하면 관리이슈가 적고 안정적이며 유연하게 사용할 수 있을 것으로 판단하였습니다. 👍
STEP2. 제약조건 정리
먼저 브랜디의 카테고리 상품목록 화면을 보여드리도록 하겠습니다.
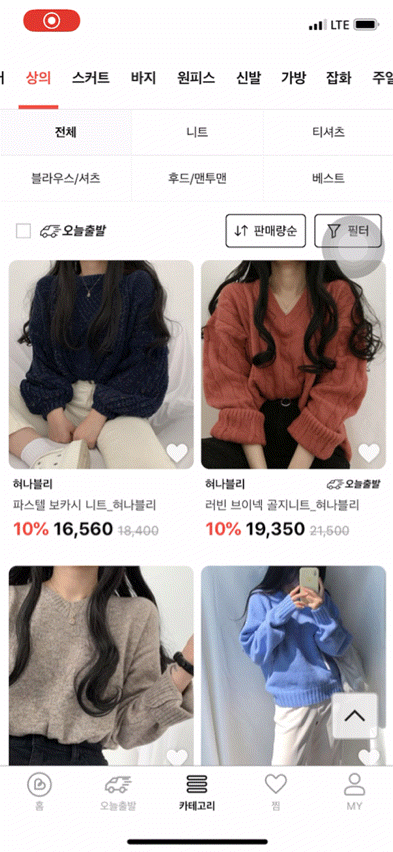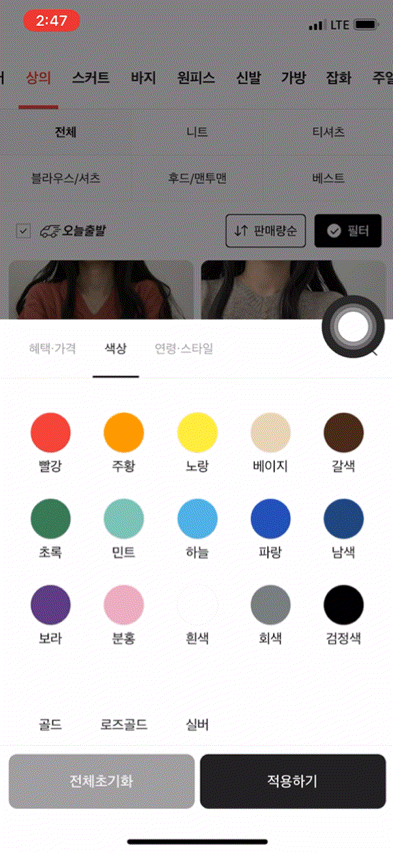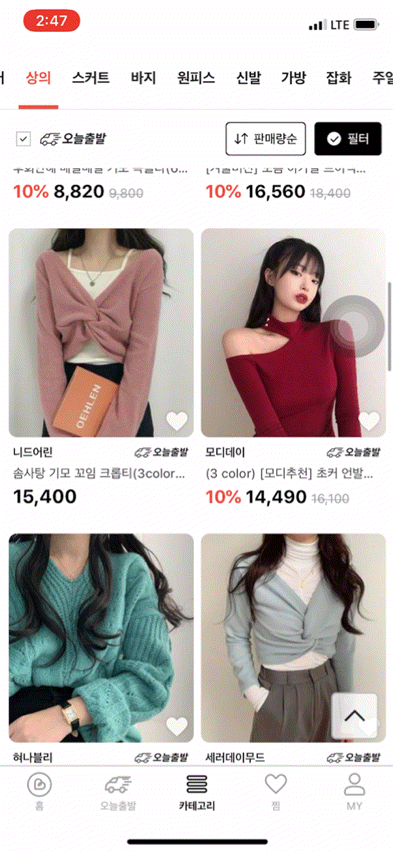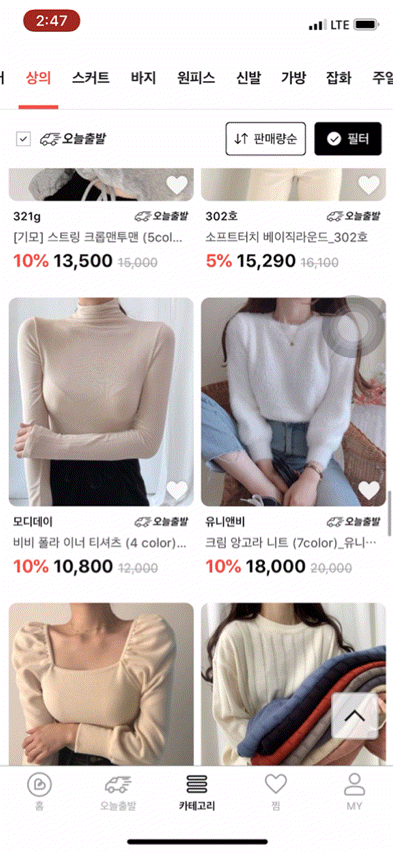
보시다시피 다양한 필터와 페이지네이션 기능이 존재하기 때문에, 기존에 캐싱이 적용된 홈 화면 대비 생각해야 할 점이 많았는데요. 정리한 제약조건 및 해결방안은 아래와 같습니다.
✔️동일한 조건의 상품목록은 한 시점에 생성되어야 한다.
페이지마다 생성 시점이 다르면 중복 상품이 노출되는 등의 문제가 발생될 수 있습니다. 캐시로 관리할 최대 상품 개수를 정하여 한 번에 상품목록을 요청한 후 조회 시 데이터가 너무 커지지 않도록 나누어 저장하도록 구성합니다.
✔️DynamoDB의 최대 항목크기는 제한이 있다.
DynamoDB의 최대 항목 크기는 400KB로 제한되기 때문에 캐시 데이터는 S3에 저장하고 해당 경로를 DynamoDB 칼럼으로 관리합니다.
정리하면 최대 상품 개수만큼 상품목록을 조회하여 N개씩 나누어 S3에 저장하고, S3 객체를 CloudFront에 연결하여 Cache Hit 시 CloudFront로 접근하게 하면 됩니다.
STEP3. 시스템 구성 및 설계
시스템 구성은 크게 캐시를 (1)생성하는 과정과 (2)조회하는 과정 두 단계로 보여드리겠습니다.
- [시스템 구성]
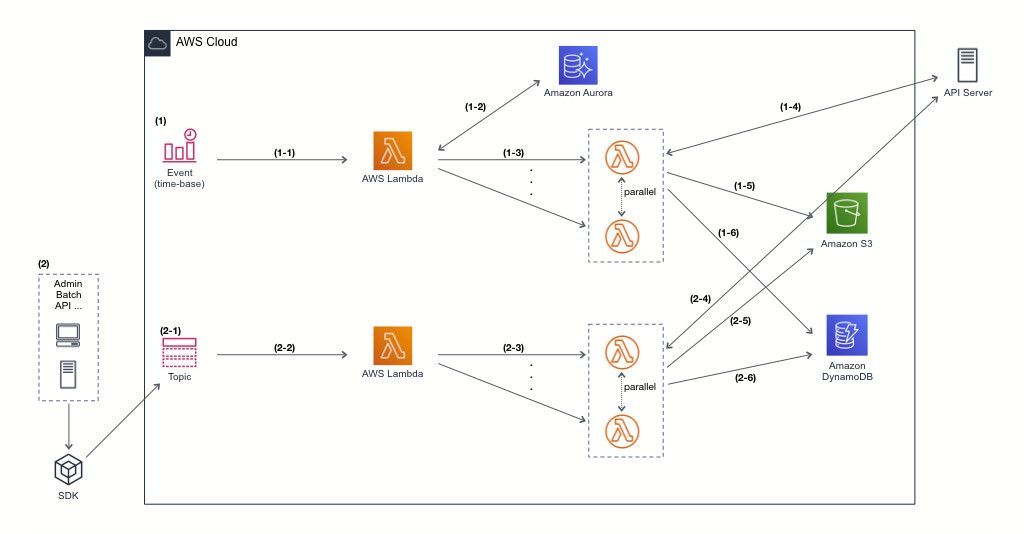
(1) CloudWatch 에 Event Rules 를 등록하여 정해진 시점에 상품목록 캐시 생성 이벤트를 발생시킵니다.
(1-1) Event에 의해 Lambda Consumer(이하 Consumer)가 실행됩니다.
(1-2) Consumer가 캐시 관리 대상 상품목록 API 목록을 조회합니다.
(1-3) Consumer는 API 목록과 함께 Lambda Worker(이하 Worker)를 병렬호출합니다.
(1-4) Worker는 넘겨받은 API 목록을 이용하여 각 API 서버에 데이터를 요청합니다.
(1-5) API 서버로부터 받은 상품목록 데이터를 특정 개수로 나누어 S3에 저장합니다.
(1-6) 저장된 S3 경로 및 정보를 DynamoDB에 저장합니다.
(2) 상품상세 데이터의 경우 상품목록 데이터와 특성이 다르므로 상품 등록/수정이 일어날 경우 SNS Topic을 이용해 이벤트를 발생시켜 캐시를 생성/갱신 합니다.
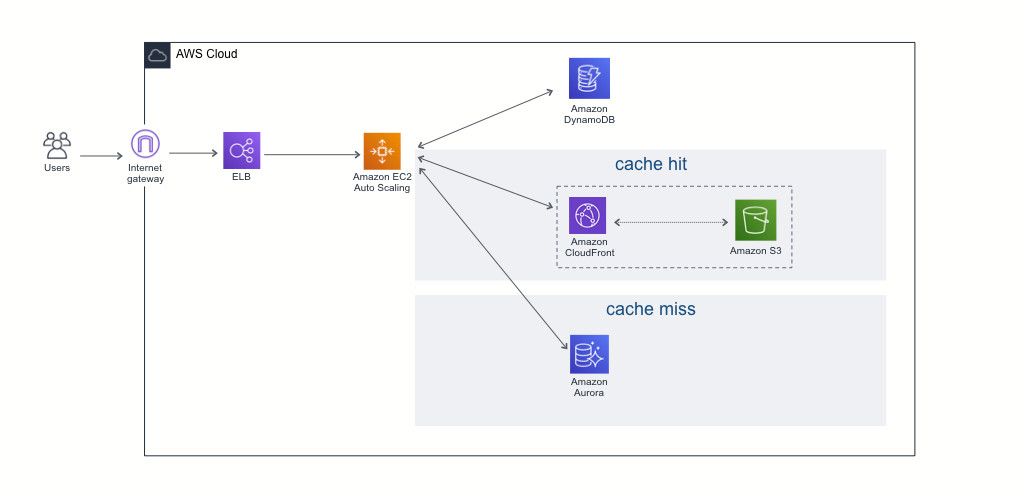
API 서버(EC2)에 캐시 적용 대상 URI 로 접근할 경우, 캐시 정보가 저장되어 있는 DynamoDB를 통해 캐시 데이터가 확인되면 대상 경로의 CloudFront 로 접근하여 데이터 조회 및 응답 처리합니다.
-
[설계]
DynamoDB
- capacity : On-Demand
- table : CACHE_PRODUCT
- cache_key (partition key)
- String
- 캐시 조회 기준 키
- version (sort key)
- Number
- 버전
- count
- Number
- 캐싱된 상품목록 수
- content_path_list
- List
- 300개씩 분리된 S3 저장 경로
- 응답데이터 4MB 초과하므로 칼럼에 내용저장 못함 (최대 항목 크기 400KB 제한)
- s3에 300개씩 분리하여 저장
- ex) product_list/{random-key}/products_{max_count}.json
- regist_datetime
- Number
- 등록일시 timestamp
- ex) 예시 데이터
- cache_key (partition key)
{
"cache_key": {
"S": "/v1/categories/46327/products"
},
"version": {
"N": "1"
},
"count": {
"N": "5000"
},
"content_path_list": {
"L": [
{
"M": {
"max": {
"N": "300"
},
"min": {
"N": "1"
},
"path": {
"S": "product_list/3209dksj-4fh5-y3tb-83c3-94jfks4jf9sd/products_300.json"
}
}
},
{
"M": {
"max": {
"N": "600"
},
"min": {
"N": "301"
},
"path": {
"S": "product_list/3209dksj-4fh5-y3tb-83c3-94jfks4jf9sd/products_600.json"
}
}
}, ...
]
},
"regist_datetime": {
"N": "1576750358"
}
}
S3
- 버킷 : cache-product
- 경로
- product_list/{random-key}/products_{max_count}.json
- product_list/{random-key}/products_{max_count}.json
Conclusion
트래픽의 대부분을 차지하던 상품목록과 상품상세 API에 캐시를 도입함으로써 평균 응답 속도가 1~2초에서 200밀리초로 대폭 감소하는 효과를 얻었습니다! 뿐만 아니라 AuroraDB 부하가 소폭 감소하였으며 안정성이 매우 높은 CloudFront-S3 를 이용하여 특별한 관리이슈 없이 잘 운영되고 있습니다. 😎
‘지연되지 않는 서비스’는 품질을 좌우하는 중요한 요소 중 하나입니다. 앞으로도 적절한 영역으로 서비스 캐시 범위를 더욱 확장함으로써 매일 예쁜 옷을 신속하게 보여드리도록 하겠습니다. 기대해주세요.
이상근 실장 | 랩스 2실
leesg@brandi.co.kr



