AWS Lambda와 SQS를 이용한 대용량 엑셀 처리
이정필
2020-06-09
Overview
브랜디의 빠른 성장과 함께 관리자 페이지 내 주문과 상품 등록 건수 또한 기하급수적으로 증가해왔습니다. 브랜디 구성원의 업무에 관리자 내 엑셀 다운로드 기능이 사용되는 만큼 많은 건수의 데이터를 빠른 시간 내 엑셀로 다운로드할 수 있는 기능의 필요성이 대두되었습니다. 이에 상품 혹은 주문 목록 몇 십만 건을 엑셀을 통해 빠르게 다운로드 가능하도록 만들어 업무 효율을 증진시키고 브랜디의 성장 속도에 박차를 가하고자 이번 프로젝트를 기획하게 되었습니다.
우리는 수십만 건의 데이터를 가져오면서 데이터베이스에 부하를 줄일 수 있는 방안을 고려하며 상품 관리 이후, 주문 관리부터 정산 관리까지 많은 메뉴 탭의 엑셀 다운로드 기능을 개선해 나가야 하기에, 필요에 따라 메뉴 별 템플릿을 만들어 해당 메뉴의 템플릿을 통해 요청 값을 검증하고, 그 요청 값을 이용하여 쿼리를 돌려 결과를 추출 해내도록 해야 했습니다. 아키텍처를 살펴보며 어떻게 개발할지 그려 보도록 하겠습니다.
#0. 아키텍처를 통해 미리 살펴보기
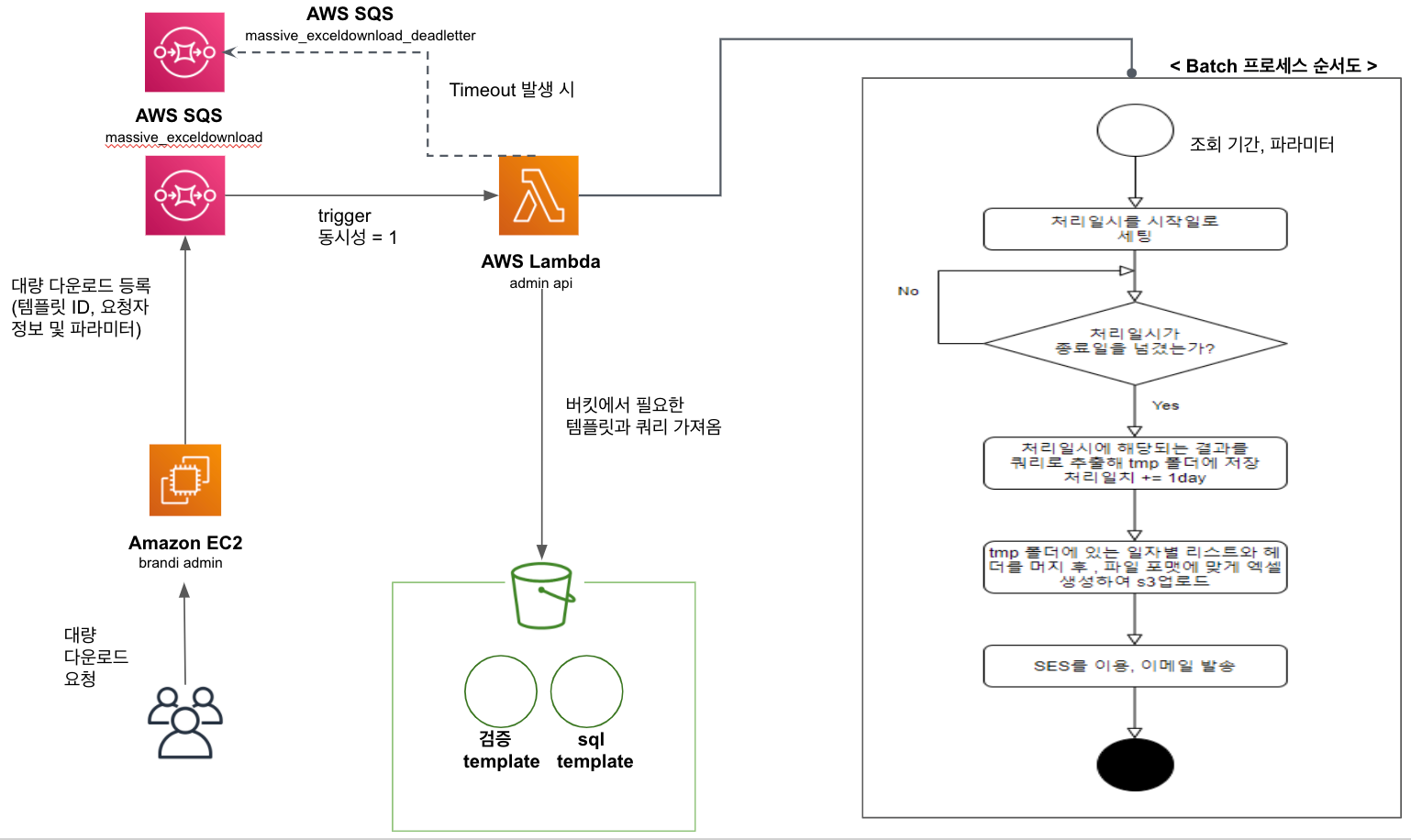
위처럼 모식도를 그려 보았습니다. 브랜디 관리자의 상품 관리 탭을 주제로 하는 시나리오를 이용하여 위의 모식도를 살펴보겠습니다.
1) 브랜디 관리자 페이지에서 엑셀 다운로드 버튼 클릭 시 JSON 형식의 데이터 SQS 대기열에 등록
2) SQS에서 앞에 마지막 요청이 끝났다면 Lambda 트리거 발생. 이때 동시성이 1이므로 한 번에 하나씩만 람다로 들어가도록 되어있음
3) 람다에서 SQS 메시지에 들어있는 templateId로 템플릿 읽어온 뒤, 템플릿에 매칭되어있는 sql도 같이 읽어서 가져옴
4) Lambda 내부의 로직에 따라 요청 값과 템플릿을 검증
5) **시작일자부터 종료일자까지 끊어 읽는 단위로 쿼리를 실행시켜 엑셀 파일을 생성한 뒤, SES를 이용하여 엑셀파일이 저장되어 있는 URL을 클라이언트에게 발송
6) 15분으로 설정되어 있는 timeout 발생 시 SQS deadletter로 기존에 받은 메시지를 보내고 deadletter SQS에서 람다로 다시 트리거를 발생 시키면, 타임아웃 메일 규격을 통해 발신자에 실패 메일 발송
다음으로 4번의 검증 로직에 대해 조금 더 자세히 살펴보겠습니다.
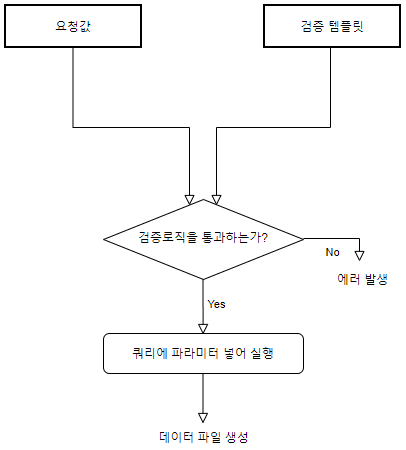
요청 값과 검증 템플릿의 depth가 2인 필드들은 반드시 1:1로 매칭되어야 합니다. 요청 값은 무조건 검증 로직을 통과해야 쿼리의 파라미터로 넘어가기 때문에, 템플릿에 설정되어 있지 않은 파라미터는 검증이 되지 않은 것으로 판단되어 쿼리의 인자로 들어가지 않도록 설계되어 있습니다. 이번 프로젝트에서 하루 단위로 끊어 쿼리를 실행시켜 데이터 파일을 만들기로 했으므로, 잘못된 요청 값이 쿼리의 인자로 전달된다면 90일치의 조회 시 90번의 쿼리를 날려 잘못된 90개의 데이터 파일을 생성하게 되므로 검증을 매우 철저하게 해야 합니다.
#1. 요청값에 따라 템플릿 설정하기
0-1번의 엑셀 다운로드 버튼을 클릭하게 되면 SQS로 메시지를 등록하게 됩니다. 상품 관리 페이지의 필터 조건을 이용했을 시에는 다음과 같은 JSON 값이 SQS 요청 규격에 알맞게 변형되어 람다로 흘러 들어가게 됩니다.
{
"templateId":"*****ProductList",# 검증을 위해 사용할 버킷에 저장된 템플릿
"downloadTitle":"", # 다운로드 시 지정될 다운로드 파일명
"requestInfo": {
"name":false, # 요청자의 이름
"email":"p*****n@brandi.co.kr", # 요청자의 이메일 주소
"mdId":"p*****@brandi.co.kr", # 요청자의 ID 주소
"serviceSection":"브랜디", # 요청서비스 브랜디/하이버
"accountNo":"*****", # 계정 번호
"mdNo":false. # 셀러 번호 ( 관리자 계정은 false )
},
"parameter": {
"templateId":"*****ProductList", # 검증을 위해 사용할 버킷에 저장된 템플릿
"filter": {
"mdSeNo":["1","2","3","4","5","6","7"], # 셀러 속성
"mdPartnerYn": "Y", # 셀러 구분
"useYn":"Y", # 상품 등록 여부
"sellYn":"Y", # 상품 판매 여부
"exhibitionYn":"Y", # 상품 전시 여부
"mdPrtnrNo":1, # 셀러 구분 번호
"productName":"셔츠", # 상품명
"registDate":{
"startDate":"2020-05-01", # 조회 기간 시작일
"endDate":"2020-05-03" # 조회 기간 마감일
},
"serviceSectionNo":"1", # 브랜디/하이버 서비스 구분
"_matchProductName":"+셔츠", # FullText 서치를 위한 상품명 정규식화
"isMaster":"Y" # 셀러/관리자 구분자
}
}
}
S3에 저장된 쿼리는 Jinja2 템플릿을 이용하여 요청 값에 값이 들어 있다면 쿼리 내에서 분기하여 필터를 거쳐가도록 아래와 같이 작성되어 있습니다. 아래의 쿼리는 설명을 위해 쿼리를 일부 발췌하여 가져왔습니다. 여기서 요청 값의 requestInfo는 프론트 단에서 조건에 따라 검증해 줄 것이며, 검증 로직에서는 쿼리에 들어가게 될 parameter 부분을 주요하게 검증할 것입니다.
{% if filter._matchProductName and filter.productName %}
-- _matchProductName은 PHP에서 말아준 상품명의 정규식 ( MySQL 정규식 미지원 )
-- FullText 서치에서 사용하기 위해 PHP 에서 보내 줌.
AND MATCH(상품명 칼럼) AGAINST (%(filter._matchProductName)s IN BOOLEAN MODE)
AND (상품명 칼럼) LIKE CONCAT('%%', %(filter.productName)s, '%%')
{% endif %}
{% if filter.productNo %}
AND (상품 등록번호 칼럼) = %(filter.productNo)s
{% endif %}
AND (상품 등록일자 칼럼) >= %(filter.registDate.startDate)s
AND (상품 등록일자 칼럼) < %(filter.registDate.endDate)s
#2에서 다시 언급하겠지만, 요청 값에 등록 일자는 필수 값이기에 조건이 없습니다. 상품명과 상품 번호는 필수 값이 아니기에 검색 필터를 통해 검색된 리스트에 한해 값이 들어있다면 쿼리의 조건문으로 실행됩니다.
#2. 템플릿을 통해 검증하기
그렇다면 위의 요청 값을 검증할 템플릿을 만들어야 합니다. 템플릿은 추후 상품 관리 탭 이외에 주문 관리, 정산 관리 등 다양한 탭의 템플릿을 제작하여 갈아 끼우기만 하면 대용량 엑셀 다운로드가 가능하도록 기능해야 하기에 설계 단계에서 매우 고심해서 만들었습니다.
createDate:2020-05-24
version:2
templateName:"상품관리_*****_엑셀다운로드_{%Y%m%d}"#downloadName미지정시대체
description:상품대용량다운로드입니다.
queryFile:***** admin_product_list.sql # 사용할 쿼리파일
options:
exportFormat:xlsx#내보내기포맷입니다.
reservedService:***** # 다운로드시사용하는포맷.미지정시대체
requestInfo:
emailAddress:
sender:labs-brandi@brandi.co.kr
type:string
required:true
downloadStep:
required:true
type:date #date,datetime
stepRange: # 시작일로부터 끊어 읽기 단위
days:1
target:
-filter.registDate.startDate
-filter.registDate.endDate
validation:
filter.mdSeNo:
name:셀러속성
type:array
required:true
filter.registDate.startDate:
name:시작일시
required:true
type:date #format:YYYY-mm-dd#2020-04-12#날짜포맷
filter.registDate.endDate:
name:종료일시
required:true
type:date
dateDiff:
target:filter.registDate.startDate
maxRange: # 최대 다운로드 가능 기간
days:92 # 3개월의 maxRange설정
hours:0
minutes:0
seconds:0
filter.mdPartnerYn:
name:파트너여부
required:false
filter.mdName:
name:셀러명
required:false
maxLength:20
minLength:1
filter.productName:
name:상품명
max:200
min:10
filter.productCode:
name:상품코드
required:false
filter.productNo:
name:상품번호
required:false
filter.useYn:
name:등록여부
required:false
filter.discountYn:
name:할인여부
required:false
filter.sellYn:
name:판매여부
required:false
filter.exhibitionYn:
name:진열여부
required:false
filter.whsalStatus:
name:도매처상태
required:false
filter.mdPrtnrNo:
name:셀러구분
required:false
filter.todayInventoryYn:
name:배송구분
required:false
filter.mdNo:
name:셀러번호
required:false
filter.recommendPriceCd:
name:권장가격
required:false
filter.serviceSectionNo:
name:서비스구분
required:true
filter.isMaster:
name:마스터구분
required:false
filter._matchProductName:
name:상품명정규식
required:false
filter.isHelpi:
name:셀러구분
required:false
여기서 몇 가지 필드들을 검증하는 검증 로직의 코드를 발췌하여 살펴보겠습니다.
# 코드 일부 발췌
config['requestInfo'] = template_data['requestInfo'] # 템플릿의 requestInfo부분
request_info = config['requestInfo']
match = re.search('^[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$',
request_info['emailAddress']['sender'])
if match is None:
raise ApiException('VL00003', '발신 메일이 이메일 형식이 아닙니다.')
이 부분은 정규식을 이용하여, 발신자의 이메일 주소가 잘못 설정되는 것을 미연에 방지하기 위함입니다. 요청자에게 메일을 보내주는 발신자의 이메일 주소에 잘못된 이메일 주소가 기입되는 것을 방지하는 것으로, 템플릿의 오류 메시지는 클라이언트에게 노출되지 않고 실행 시 개발자에게 노출됩니다.
# 코드 일부 발췌
if 'stepRange' in request_info['downloadStep']:
# 끊어서 저장하는 범위가 있는지 확인
step_range = request_info['downloadStep']['stepRange']
# 템플릿 내 시간 범위가 잘못 설정된 경우 발생
if 'days' in step_range:
if step_range['days'] < 0:
raise ApiException('VL00002', '다운로드 유효기간 일자 설정이 잘못되었습니다.')
elif 'hours' in step_range:
if step_range['hours'] not in range(0, 24):
raise ApiException('VL00002', '다운로드 유효기간 시간 설정이 잘못되었습니다.')
elif 'minutes' in step_range:
if step_range['minutes'] not in range(0, 60):
raise ApiException('VL00002', '다운로드 유효기간 분 설정이 잘못되었습니다.')
elif 'seconds' in step_range:
if step_range['seconds'] not in range(0, 60):
raise ApiException('VL00002', '다운로드 유효기간 초 설정이 잘못되었습니다.')
else:
raise ApiException('VL00001', '다운로드 유효기간 내 기간 설정이 되어있지 않습니다.')
else:
raise ApiException('VL00001', '다운로드 가능한 유효기간이 설정되어있지 않습니다.')
우리는 시작 일자로부터 마감 일자까지 하루 단위로 끊어 읽도록 템플릿에 설정하였습니다. 템플릿의 시간 범주를 명확하게 하여 쿼리에 잘못된 datetime 형식으로 파라미터가 넘어가지 않도록 하기 위하여 위와 같이 끊어 읽는 단위를 검증하게 되었습니다.
# 코드 일부 발췌
config['validation'] = template_data['validation'] # 템플릿의 검증 부분
for key in config['validation']:
column = config['validation'][key]
validation_keys = config['validation'].keys()
val = self.get_json_param(parameter, key, None)
plain_param = self.__json_to_plan_dict(parameter)
if 'required' in column and column['required'] is True:
if val is None:
raise ApiException('VL00001', '필수 칼럼인 ' + column.get('name')+' 값이 누락되었습니다.')
elif val is None:
continue
템플릿의 검증 부분에 있는 값들 중 required: true 로 되어있는 부분이 요청 값으로 들어오지 않았다면 에러를 일으키게 됩니다. 필수 값인 부분은 프론트 단에서 1차적으로 검수하여 입력이 되지 않는 다면 alert 화면이 노출되지만, 혹시 모를 상황을 대비하여 백엔드 단에서도 2차적으로 필수 값에 대하여 검증해 주었습니다.
위와 같은 검증 로직을 거치고 나면 요청 값에 들어있는 인자들의 JSON depth가 모두 같도록 쪼갠 다음 parameter로 묶어서 검증 로직 함수를 호출한 부분에 반환해 줍니다.
#3. 분리된 파일들 merge하여 엑셀 파일 만들기
위의 파라미터가 쿼리로 넘어와서 쿼리가 실행되면 일자별로 하여 data[00N].data 와 같은 리스트 파일과 컬럼 값이 들어있는 header.data 파일이 생성됩니다.
# 코드 일부 발췌
# 헤더 데이터 작성
if is_header_write is False and query_list is not None and len(query_list) > 0:
header_list = query_list[0].keys()
with open(folder_name + '/header.data', 'wt', encoding="utf-8") as w:
for k in header_list:
w.write(k)
w.write("\t")
is_header_write = True
# 결과 리스트 생성
with open(folder_name + '/data' + str(i).zfill(3) + '.data', "w") as f:
if query_list is not None:
for item in query_list:
for x in item.values():
if type(x) is str:
if '\t' in x:
# 상품명에 탭이 들어가는 경우 탭 제거
x = x.replace('\t', ' ')
f.write(str(x))
f.write("\t")
f.write("\n")
else:
pass
3일치를 조회하는 경우의 실행 결과는 아래와 같습니다.
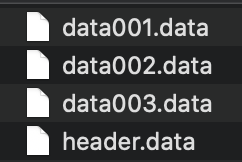
이렇게 파일들이 생성되면 다음의 절차를 통해 엑셀을 생성 후 S3 버킷에 업로드합니다.
1) Lambda의 tmp 폴더에 들어있는 각각의 파일들을 merge하여 tmp 폴더에 엑셀 파일 생성
2) 엑셀 파일을 제외한 모든 파일들을 삭제
템플릿 파일의 exportFormat을 지정하면 csv와 xlsx 포맷 중 택하여 사용할 수 있습니다.
-
CSV 장점 :: 콤마(,) 등으로 구분하여 텍스트 편집기로 열어볼 수 있는 단순 읽기 쓰기 형식을 제공
-
CSV 단점 :: 서식 지정 등이 어렵다는 단점이 있어 업무 중에 편집 등이 어렵다는 큰 단점이 존재
-
XLSX 장점 :: 앞의 CSV의 단점을 커버하여 서식 지정이 가능
-
XLSX 단점 :: 일반 텍스트가 아니기에 data를 merge하여 엑셀로 마는데 csv에 비해 시간이 오래 걸린다는 단점
생성 용량 등 각각의 장단점을 고려하여 하나를 택하여 포맷에 지정하면 다음의 헬퍼에서 메소드를 실행하여 엑셀 파일을 생성합니다.
import os
import glob
import pandas as pd
import xlsxwriter
# 코드 일부 발췌
class MassiveHelper:
"""대용량 처리 헬퍼
"""
def merge_csv(self, folder_name, output_format, template_name):
"""분리 되어있는 데이터 csv로 머징
:param folder_name:
:param output_format:
:return int:
"""
file_list = sorted(glob.glob(folder_name + '/data*'), key=os.path.getctime)
total = 0
x = 0
with open(folder_name + '/' + template_name + '.' + output_format, 'wt', encoding='utf-8') as w:
with open(folder_name + '/header.data', 'rt', encoding="utf-8") as r:
if total == 0:
w.write(r.readline())
w.write('\n')
for file_name in file_list:
if file_name.find('data') == -1:
continue
with open(file_name, 'rt', encoding='utf-8') as rf:
while True:
line = rf.readline()
if not line:
break
w.write(line)
total += 1
def merge_xlsx(self, folder_name, output_format, template_name):
"""분리 되어있는 데이터 xlsx로 머징
:param folder_name:
:param output_format:
:return int:
"""
total = 0
file_list = sorted(glob.glob(folder_name + '/data*'), key=os.path.getctime)
with open(folder_name + '/' + template_name + '.' + output_format, 'wb') as fout:
writer = pd.ExcelWriter(fout, engine='xlsxwriter', options=dict(constant_memory=True, in_memory=True))
# taken from the original question
workbook = writer.book
worksheet = workbook.add_worksheet()
header_format = workbook.add_format(
{'bold': True, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#D7E4BC'})
cell_widths = [] # 셀 너비
font_width = 1 # 글자 너비
font_width_h = 1.88 # 한글 한글자
padding = 1.12
y = 0
# header write
with open(folder_name + '/header.data', 'rt', encoding="utf-8") as rf:
datas = rf.readline().strip().split('\t')
for x, d in enumerate(datas):
text_cnt = self.__count_text_size(str(d))
cell_widths.append(text_cnt[0] * font_width_h + text_cnt[1] * font_width + padding)
worksheet.write(y, x, d, header_format)
y = 1
for file_name in file_list:
if file_name.find('data') == -1:
continue
with open(file_name, 'rt', encoding="utf-8") as rf:
while True:
line = rf.readline()
if not line:
break
datas = line.strip().split('\t')
for x, d in enumerate(datas):
worksheet.write(y, x, d)
text_cnt = self.__count_text_size(str(d))
width = text_cnt[0] * font_width_h + text_cnt[1] * font_width + padding
try:
if cell_widths[x] < width:
cell_widths[x] = width
except Exception as e:
raise e
total += 1
y += 1
x = 0
for w in cell_widths:
worksheet.set_column(x, x, w) # Column A width set to 20.
x += 1
writer.close()
위의 코드를 통해 엑셀 파일이 성공적으로 생성되면 아래의 코드로 S3에 업로드할 수 있습니다.
s3.upload_file(folder_name + '/' + template_name + '.' + output_format,
constants.MASSIVE_EXCEL_UPLOAD_BUCKET,
constants.MASSIVE_EXCEL_UPLOAD_FOLDER
+ '/' + str(uuid_name) + '/' + template_name
+ '.' + output_format
, ExtraArgs={'ACL': 'public-read'})
이때 ‘ACL’: ‘public-read’를 이용하는 이유로 클라이언트가 퍼블릭으로 설정되지 않은 버킷에 대하여 객체만 퍼블릭으로 설정하여 다운로드 링크를 통해 다운로드할 수 있도록 해주는 것입니다. 업로드를 완료하고 나면 tmp 폴더에 data[00N].data 파일들과 header.data를 삭제해주어야 합니다.
# 코드 일부 발췌
finally:
try:
if db:
db.close()
except Exception as e2:
raise ApiException('VL00001', '잘못된 추출 포맷입니다.')
finally:
# 엑셀 파일 포맷으로 추출 완료 후 기존 데이터 및 헤더 파일 삭제
file_list = sorted(glob.glob(folder_name + '/data*'), key=os.path.getctime)
file_list.append(folder_name + '/header.data')
for v in file_list:
if os.path.exists(v):
os.unlink(v)
self._logger.info('[헤더 및 데이터 삭제 처리 완료]', log_type='info')
이렇게 엑셀이 업로드되고, merge된 파일이 정상적으로 삭제되었다면 메일로 발송한 뒤 마무리해 주면 됩니다.
#4. 이메일을 통해 다운로드 URL 보내기
지금까지 python을 사용하여 코드를 작성했습니다. 그래서 AWS SES 또한 Python을 위한 AWS의 SDK인 boto3를 이용하여 메일을 발송할 것입니다. 아래와 같이 SES에서 SMTP 인증 메일로 인증을 해야 SENDER, 즉 발신자로 메일을 보낼 수 있습니다.

아래는 메일 전송을 위한 코드를 일부 발췌한 것입니다.
import uuid
import smtplib
import email.utils
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
import boto3
# 코드 일부 발췌
def __send_mail(...):
# Replace sender@example.com(opens in new tab) with your "From" address.
# This address must be verified.
sender = constants.SENDER
sender_name = constants.SENDER_NAME
# Replace recipient@example.com(opens in new tab) with a "To" address. If your account
# is still in the sandbox, this address must be verified.
recipient = mail_info['email']
# Replace smtp_username with your Amazon SES SMTP user name.
username_smtp = constants.USERNAME_SMTP
# Replace smtp_password with your Amazon SES SMTP password.
password_smtp = constants.PASSWORD_SMTP
# (Optional) the name of a configuration set to use for this message.
# If you comment out this line, you also need to remove or comment out
# the "X-SES-CONFIGURATION-SET:" header below.
# CONFIGURATION_SET = "ConfigSet"
# If you're using Amazon SES in an AWS Region other than 미국 서부(오레곤),
# replace email-smtp.us-west-2.amazonaws.com with the Amazon SES SMTP
# endpoint in the appropriate region.
host = constants.SMTP_HOST
port = constants.SMTP_PORT
# PORT = 465
# The subject line of the email.
body_text = """
안녕하세요. {0}입니다.
{1}에 요청하신 파일을 아래 URL을 통해 다운로드 가능합니다.
{2}
다운로드 기간 : {3} ~ {4}
* 본 메일은 발신 전용으로 회신이 불가합니다.
문의사항은 카카오 플러스친구 @{0}셀러를 이용해 주시기 바랍니다.
감사합니다.
""".format(...)
# Create message container - the correct MIME type is multipart/alternative.
msg = MIMEMultipart('alternative')
msg['Subject'] = subject
msg['From'] = email.utils.formataddr((sender_name, sender))
msg['To'] = recipient
# Comment or delete the next line if you are not using a configuration set
# msg.add_header('X-SES-CONFIGURATION-SET',CONFIGURATION_SET)
# Record the MIME types of both parts - text/plain and text/html.
part1 = MIMEText(body_text, 'plain')
part2 = MIMEText(body_html, 'html')
# Attach parts into message container.
# According to RFC 2046, the last part of a multipart message, in this case
# the HTML message, is best and preferred.
msg.attach(part1)
msg.attach(part2)
# Try to send the message.
try:
server = smtplib.SMTP(host, port)
server.ehlo()
server.starttls()
# stmplib docs recommend calling ehlo() before & after starttls()
server.ehlo()
server.login(username_smtp, password_smtp)
server.sendmail(sender, recipient, msg.as_string())
server.close()
# Display an error message if something goes wrong.
except Exception as e:
raise ApiException('VL00001', '메일전송에 오류가 발생하였습니다.')
else:
# 메일 전송 완료에 대해선 로그 처리
self._logger.info('[메일 전송 완료]', log_type='info')
위와 같이 메일을 보내주는 코드가 성공적으로 실행되면, 수신자는 아래와 같이 메일을 받게 됩니다.

이렇게 버튼을 클릭하여 엑셀 다운로드 요청부터 메일을 수신하는 것까지 성공적으로 완료했습니다.
Conclusion
이로써 대용량 엑셀 다운로드 문제를 해결했지만, 몇 가지의 고민거리는 잔재합니다.
- 동시성이 1로 제한되어 있어, 다수의 셀러 혹은 관리자가 동시에 대용량 엑셀 다운로드 요청을 보내는 경우의 대기 시간.
- 약 백만 건이 넘어가는 데이터를 엑셀 다운로드 해야 하는 경우
첫 번째 문제에 대해서는 replica 서버를 이용하여 동시성을 늘린 뒤 다양한 람다를 동시에 구동시킬 수 있도록 지속적으로 검토 중에 있습니다. 함께, 두 번째 문제에 대해서는 파워피벗 혹은 데이터베이스 테이블을 이용하는 등 다양한 고민을 지속해야 합니다. 뿐만 아니라 다건의 데이터를 내려받는 경우의 latency 등 여전히 풀어야 할 숙제가 많이 남아있습니다.
이정필 | 커머스 개발팀
leejp@brandi.co.kr



