AWS Elasticsearch + Python을 활용한 '검색' 도전기
이경희
2021-07-08
Overview
브랜디는 동대문 기반의 풀필먼트 서비스를 통합 관리할 수 있는 시스템 ‘FMS(Fulfillment Management System)’를 개발하여 서비스를 운영하고 있습니다.
그 중 상품관리를 하는데 점점 상품수가 증가함에 따라 RDBMS + DynamoDB + Cache 만으론 상품검색시 성능 이슈가 있어 관계형 데이터베이스(RDBMS: mysql, oracle, mariadb)를 대신하여 검색엔진 Elasticsearch를 이용하면 좋을 것 같아 이번 글에서 상품관리 개선을 위한 AWS Elasticsearch Service 설정 및 예제를 통한 사용 방법에 대해 알아보겠습니다.
Contents
- Elasticsearch 소개
- FMS(Fulfillment Management System) 상품관리에 사용중인 방식
- AWS Elasticsearch 구축하기
- AWS Elasticsearch Service 연결 및 사용방법
- AWS Elasticsearch Service 연결
- Index Create & Mapping 설정
- Document 추가
- Search 검색
- 마무리
Elasticsearch 소개
Apache Lucene(아파치 루씬) 기반의 java 오픈소스 분산 검색 엔진이며, 전체 텍스트 검색에 뛰어납니다. 방대한 양의 데이터를 신속하고 거의 실시간으로 저장, 검색, 분석할 수 있습니다.
데이터 저장소가 아니기 때문에 관계형 데이터베이스(RDBMS: mysql, oracle, mariadb)를 대체할 수 없습니다.
FMS(Fulfillment Management System) 상품관리에 사용중인 방식
최초 상품 조회시 검색조건과 검색값을 RDBMS에서 조회하여 DynamoDB에 등록한 후 다음 조회시 5분 이내 기준으로 동일한 검색조건이 있을 경우, 데이터를 DynamoDB에서 조회하는 방식을 사용하고 있습니다.
하지만 점점 데이터양이 많아질수록 RDBMS에서 조회하는 속도가 점점 느려지는 문제가 있습니다.
아래 문제점들을 개선하기 위해 Elasticsearch 기술 도입을 생각하게 되었습니다.
- 문제점
- 상품검색시 MySQL에 LIKE ‘%단어%’ 검색시 인덱스를 사용하지 않기 때문에 검색속도가 느리다.
- 검색 조건으로 Cache Key를 등록하는데 검색조건이 다양하여 Cache 성능이 떨어진다.
AWS Elasticsearch 구축하기
Amazon Elasticsearch Service 개발자 가이드 를 참고하여 ES 도메인 생성을 합니다.
아래는 생성 마지막 검토 단계 화면입니다.
도메인 상태가 활성화 되면 엔드포인트와 Kibana 주소가 생성됩니다. 엔드포인트 주소로 Elasticsearch에 접속 할 수 있고, Kibana 주소로 Kibana에 접속 할 수 있습니다.
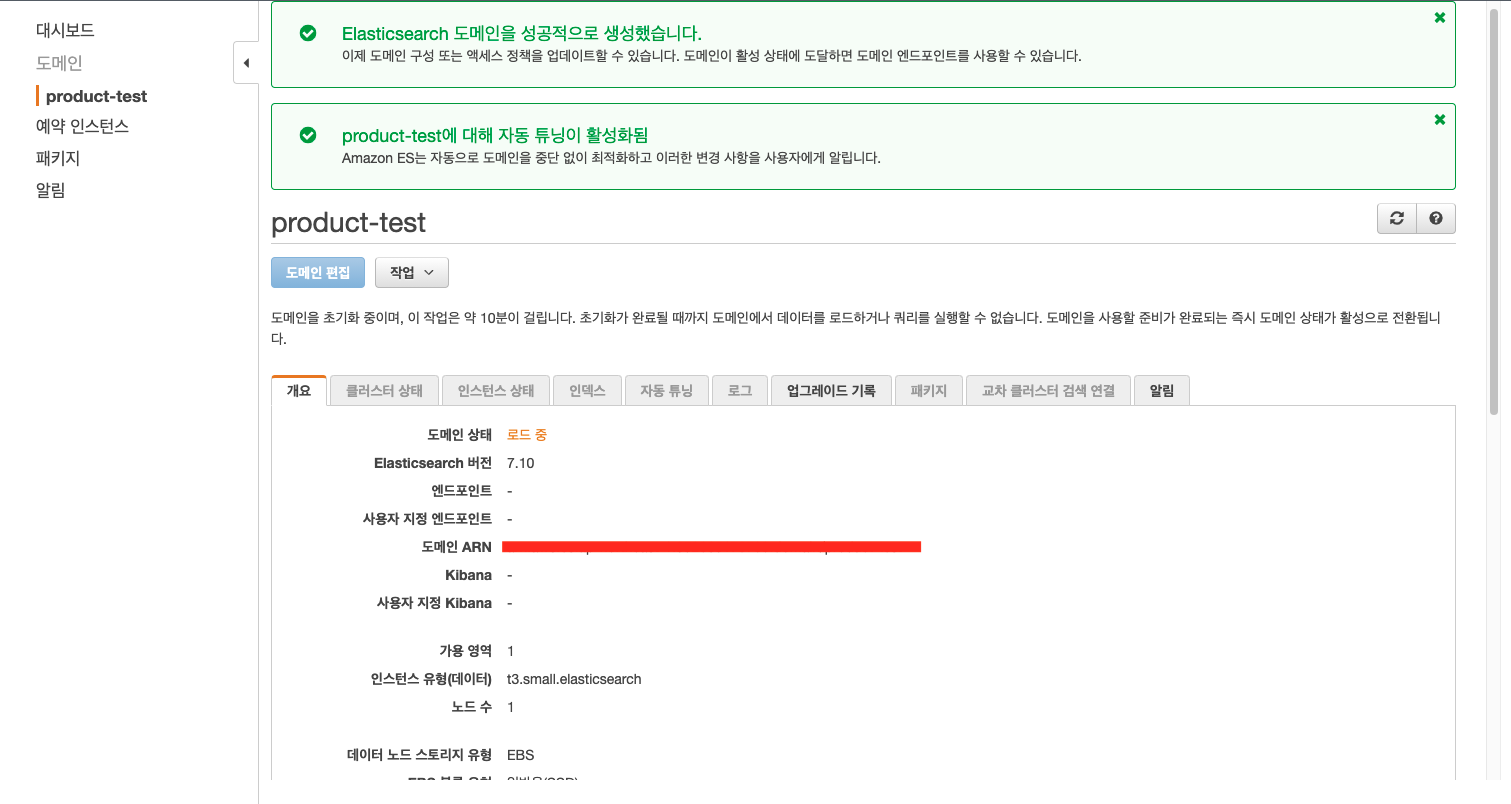
엔드포인트 주소로 접속한 화면입니다. 아래 화면이 보이면 도메인 생성이 완료된 것입니다.
AWS Elasticsearch Service 연결 및 사용방법
AWS Elasticsearch Service 연결
- 설치
pip install elasticsearch
pip install requests-aws4auth
- ES 접속
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
AWS_ACCESS_KEY = 'AWS_ACCESS_KEY'
AWS_SECRET_KEY = 'AWS_SECRET_KEY'
AWS_REGION = 'AWS_REGION'
AWS_SERVICE = 'es'
HOST = '엔드포인트 주소'
awsauth = AWS4Auth(
AWS_ACCESS_KEY,
AWS_SECRET_KEY,
AWS_REGION,
AWS_SERVICE,
)
es = Elasticsearch(
hosts = [{'host': HOST, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
_index = "product_index" # index name
Index Create & Mapping 설정
인덱스를 생성해 보겠습니다.
resp = es.indices.create(index=_index, body={
"settings" : {
"index":{
"analysis":{
"analyzer" : {
"korean" : {
"type" : "custom",
"tokenizer" : "seunjeon"
}
},
"tokenizer" : {
"seunjeon" : {
"type" : "seunjeon_tokenizer"
}
}
}
}
},
"mappings": {
"properties": {
"product_name": {
"type": "text",
"analyzer": "korean"
}
}
}
})
- Tokenizer
인덱스를 설정하기에 앞서 어떤 데이터를 검색 할 것인지에 따라 설정 방법이 달라집니다. 본문에서는 한글 상품명인 데이터 검색 테스트를 진행할 예정입니다. 그러나 Elasticsearch 검색엔진은 한글에서는 성능을 발휘하기 쉽지 않은 검색엔진입니다.
한글은 다른 언어와 달리 조사나 어미의 접미사가 명사, 동사 등과 결합하기 때문에 기본 형태소 분석기로는 분석하기 쉽지 않습니다. 검색엔진을 한글에 적용하기 위해서 별도의 한글 형태소 분석기가 필요 하다고 생각하여 AWS 에서 제공하는 은전한닢(Seunjeon)을 사용할 예정입니다.
다른 분석기도 있으나 은전한닢(Seunjeon)을 선택한 이유는 Elasticsearch 클러스터가 설치될 때 자동으로 설치가 되어 사전 설치 단계 없이 사용이 가능하기 때문에 선택하였습니다.
인덱스 생성시 이를 직접 참조할 수 있으며, 사용하려면 인덱스에 어느 필드가 한국어인지 설정하여 사용할 수 있습니다.
- 매핑 정의
데이터가 입력되어 자동으로 매핑이 생성되기 전에 미리 먼저 인덱스의 매핑을 정의해 놓으면, 그 매핑에 맞추어 데이터가 입력됩니다. 인덱스 생성 이후 필드 추가도 가능합니다.
하지만 이미 만들어진 필드 삭제나 타입 및 설정 변경은 불가능하여, 인덱스 삭제 후 새로 정의하고 기존 인덱스의 값을 새 인덱스에 모두 재색인 해야 합니다. 필드 타입에는 문자열, 숫자, 날짜 등이 있습니다. 필드 타입에 자세한 상세 설명은 Elastic 가이드북을 참고하시면 됩니다.
Document 추가
테스트를 위해 인덱스에 다음 6개의 상품 데이터를 등록하겠습니다. 상품명은 브랜디에 있는 상품명을 이용해 보도록 하겠습니다.
- Bulk API
resp = es.bulk(
body=[
{"index": {"_index": _index, "_id": "1"}},
{"product_name": "허벅지 슬림 하이웨스트 코튼 밴딩 팬츠 반바지 (3color)_미우블랑"},
{"index": {"_index": _index, "_id": "2"}},
{"product_name": "코쿤 하이웨스트 핀턱 와이드 팬츠_유라타임"},
{"index": {"_index": _index, "_id": "3"}},
{"product_name": "( 4컬러 ) 톡톡 전체밴딩 3부 하이웨스트 쭈리 숏팬츠 반바지 _유어아운스퀘어"},
{"index": {"_index": _index, "_id": "4"}},
{"product_name": "[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g"},
{"index": {"_index": _index, "_id": "5"}},
{"product_name": "린넨크롭 베이직브이반팔가디건_302호"},
{"index": {"_index": _index, "_id": "6"}},
{"product_name": "린넨크롭 베이직브이반팔가디건"},
],
)
Search 검색
검색 테스트 진행은 일부 검색이나, 전체 검색이나 둘 다 검색 조건이 일치 하다고 판단되어 score 점수가 결과값 중 높게 나오는 것으로 목표로 하고 테스트를 진행해 보겠습니다. 검색 값은 아래 내용으로 진행하겠습니다.
- 상품명 일부 : 롱 와이드슬랙스
- 상품명 전체 : [하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g
먼저 상품명의 일부인 “롱 와이드슬랙스”를 **검색해 보겠습니다.
results = es.search(index=_index, body={'query':{'match':{'product_name':'롱 와이드슬랙스'}}})
총 2개의 상품이 검색 된 것을 확인 할 수 있습니다. 결과에 _score 부분을 확인해 보면 ‘코쿤 하이웨스트 핀턱 와이드 팬츠_유라타임’ 상품이 ‘[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g’ 상품보다 일치하다고 판단되어 점수가 더 높게 측정되었습니다. 제가 원하는 결과값은 롱 와이드슬랙스 가 포함된 상품이 score가 더 높게 나와야 합니다. 그래야 조회했을 때 가장 일치한 상품을 첫 번째로 노출할 수 있습니다.
- _score는 검색된 결과가 얼마나 검색 조건과 일치하는지를 보여주며, 각 검색 결과 항목마다 표시되어 점수가 높은 순으로 정렬하여 보여줍니다.
{
'took': 8157,
'timed_out': False,
'_shards': {
'total': 5,
'successful': 5,
'skipped': 0,
'failed': 0
},
'hits': {
'total': {
'value': 2,
'relation': 'eq'
},
'max_score': 0.6785375,
'hits': [
{
'_index': 'product_index',
'_type': '_doc',
'_id': '2',
'_score': 0.6785375,
'_source': {
'product_name': '코쿤 하이웨스트 핀턱 와이드 팬츠_유라타임'
}
},
{
'_index': 'product_index',
'_type': '_doc',
'_id': '4',
'_score': 0.41182578,
'_source': {
'product_name': '[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g'
}
}
]
}
}
두번째로 전체 상품명을 검색한 결과값을 확인한 결과, 전체 상품명 검색시엔 ‘[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g’ 상품이 score 점수가 제일 높게 나왔습니다.
{
'took': 1081,
'timed_out': False,
'_shards': {
'total': 5,
'successful': 5,
'skipped': 0,
'failed': 0
},
'hits': {
'total': {
'value': 4,
'relation': 'eq'
},
'max_score': 4.436219,
'hits': [
{
'_index': 'product_index',
'_type': '_doc',
'_id': '4',
'_score': 4.436219,
'_source': {
'product_name': '[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g'
}
},
{
'_index': 'product_index',
'_type': '_doc',
'_id': '2',
'_score': 4.071225,
'_source': {
'product_name': '코쿤 하이웨스트 핀턱 와이드 팬츠_유라타임'
}
},
{
'_index': 'product_index',
'_type': '_doc',
'_id': '1',
'_score': 1.1829917,
'_source': {
'product_name': '허벅지 슬림 하이웨스트 코튼 밴딩 팬츠 반바지 (3color)_미우블랑'
}
},
{
'_index': 'product_index',
'_type': '_doc',
'_id': '6',
'_score': 0.77677083,
'_source': {
'product_name': '린넨크롭 베이직브이반팔가디건'
}
}
]
}
}
- Analyze API
전체 상품명과 일부 상품명 검색 결과 비교시 전체 상품명을 검색해야 더 정확하게 조회되는 것을 확인할 수 있었습니다. 그래서 일부 검색어인 ‘롱 와이드슬랙스’ 검색어가 어떻게 분석되는지 확인하여 인덱스 설정을 변경 후 테스트를 다시 진행해 보겠습니다.
분석은 Analyzer API를 이용해서 텍스트 분석을 할 수 있습니다. 검색어가 어떻게 인식되는지 Analyze API 를 사용하여 분석 결과를 확인해 보겠습니다.
results = es.indices.analyze(index=_index, body={'analyzer' : 'korean', 'text' : '롱 와이드슬랙스'})
아래는 분석 결과 데이터이며, 추출된 각 키워드들은 term 이라고 부릅니다. 단어 옆에 적혀 있는 영어는 형태소를 분석할 결과로, 품사 태그표를 이용하여 단어의 형태가 무엇인지 알 수 있습니다. 또한 score가 높게 나오려면 검색된 term이 많이 포함되어야 합니다.
아래 상품명에 포함된 term을 보면 각각 1개씩 포함되어 있습니다. 그러나 첫번째 상품이 score점수가 높가 나온 이유는 길이가 큰 필드 보다는 짧은 필드에 있는 term의 비중이 크기 때문입니다.
- 코쿤 하이웨스트 핀턱 와이드 팬츠_유라타임 (score 점수 : 0.6785375)
- [하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g (score 점수 : 0.41182578)
{
'tokens': [
{
'token': '롱/N',
'start_offset': 0,
'end_offset': 1,
'type': 'N',
'position': 0
},
{
'token': '와이드/N',
'start_offset': 2,
'end_offset': 5,
'type': 'N',
'position': 1
},
{
'token': '슬랙스/N',
'start_offset': 5,
'end_offset': 8,
'type': 'N',
'position': 2
}
]
}
- Token Filter
분석결과를 확인하였으니 토큰필터를 적용하여 인덱스 설정을 다시 해 보겠습니다. 기존 인덱스 삭제 후 > 인덱스 생성 > 데이터 등록을 다시 해야 합니다. 이번 인덱스에는 토큰필터를 추가하여 설정해 보겠습니다.
- 토큰필터는 토크나이저를 이용한 텀 분리 과정 이후 분리된 각각의 텀들을 지정한 규칙에 따라 처리를 해주는 과정을 담당합니다. 토큰 필터는 elasticsearch-py 공식문서에서 확인 가능합니다.
필자가 선택한 토큰필터는 shingle 입니다.
- shingle 타입 필터는 문자가 아니라 단어 단위로 문장을 분리해서 2개의 shingle 들이 생성됩니다. 디폴트 shingle 단어 개수는 2이기 때문에 아래 분석 결과를 보면 단어가 최대 2개로 묶여 있지 않은 것을 확인할 수 있습니다.
# 인덱스 삭제
es.indices.delete(index=_index)
resp = es.indices.create(index=_index, body={
"settings" : {
"index":{
"analysis":{
"analyzer" : {
"korean" : {
"type" : "custom",
"tokenizer" : "seunjeon",
"filter": "shingle_filter"
}
},
"tokenizer" : {
"seunjeon" : {
"type" : "seunjeon_tokenizer"
}
},
"filter": {
"shingle_filter": {
"type": "shingle"
}
}
}
}
},
"mappings": {
"properties": {
"product_name": {
"type": "text",
"analyzer": "korean"
}
}
}
})
위 인덱스 생성 후 ‘롱 와이드슬랙스’로 검색을 다시 해 보았습니다. 롱 와이드슬랙스가 포함된 상품과 와이드가 포함된 상품으로 총 2개의 상품이 검색되었습니다.
이번 검색 결과를 확인해보면 score 점수가 ‘[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g’ 상품이 더 높은것을 확인 할 수 있습니다.
{
'took': 32,
'timed_out': False,
'_shards': {
'total': 5,
'successful': 5,
'skipped': 0,
'failed': 0
},
'hits': {
'total': {
'value': 2,
'relation': 'eq'
},
'max_score': 1.3974984,
'hits': [
{
'_index': 'product_index',
'_type': '_doc',
'_id': '4',
'_score': 1.3974984,
'_source': {
'product_name': '[하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g'
}
},
{
'_index': 'product_index',
'_type': '_doc',
'_id': '2',
'_score': 0.903265,
'_source': {
'product_name': '코쿤 하이웨스트 핀턱 와이드 팬츠_유라타임'
}
}
]
}
}
분석 결과를 확인해보면 기본 한글 형태소 분석기 기준으로 분리되며, 2개의 단어씩 토큰 필터가 적용된 것을 확인할 수 있으며, 한국어 형태소 분석기 전처리를 통해 와이드와 슬랙스가 각각 분리되고 토큰 필터가 적용되어 롱 과 와이드슬랙스를 묶어준 케이스로 생각됩니다.
- 롱 + 와이드
- 롱 + 와이드슬랙스
- 와이드 + 슬랙스
또한 ‘하이웨스트/핏 보장] 베이직 핀턱 롱 와이드슬랙스 (3color)_321g’ 해당 상품명을 확인해 보면 검색된 term이 모두 포함되어 score 점수가 높게 나온 결과를 확인 할 수 있습니다.
{
'tokens': [
{
'token': '롱/N',
'start_offset': 0,
'end_offset': 1,
'type': 'N',
'position': 0
},
{
'token': '롱/N와이드/N',
'start_offset': 0,
'end_offset': 5,
'type': 'shingle',
'position': 0,
'positionLength': 2
},
{
'token': '롱/N와이드/N슬랙스/N',
'start_offset': 0,
'end_offset': 8,
'type': 'shingle',
'position': 0,
'positionLength': 3
},
{
'token': '와이드/N',
'start_offset': 2,
'end_offset': 5,
'type': 'N',
'position': 1
},
{
'token': '와이드/N슬랙스/N',
'start_offset': 2,
'end_offset': 8,
'type': 'shingle',
'position': 1,
'positionLength': 2
},
{
'token': '슬랙스/N',
'start_offset': 5,
'end_offset': 8,
'type': 'N',
'position': 2
}
]
}
마무리
AWS Elasticsearch 생성부터 검색 테스트까지 진행해 보았습니다. 테스트를 진행해보면서 인덱스 설계에 따라 검색 정확도, 조회 결과가 달라지는 것을 보고 인덱스 설계 최적화가 중요한 것을 확인 할 수 있었습니다. 다른 기업의 도입사례와 테스트를 통해 검색 결과의 정확도, 대량 데이터일 때 검색속도 측정 등 앞으로 테스트를 계속하여 FMS 시스템이 안정화 되도록 하는 것이 목표입니다.
이번 글을 통해 조금이나마 Elasticsearch에 대해 도움이 되셨으면 좋겠습니다. 긴 글 읽어주셔서 감사합니다!
참고
AWS Elasticsearch Service 개발자 가이드
이경희 | 풀필먼트 개발팀
leekh@brandi.co.kr



