광고 서비스 개발 연대기
김진실
2022-05-18
입사하자마자 2달 만에 서비스 출시 한 썰 푼다.
안녕하세요. 저는 브랜디에서 3년 같은 4개월 차를 맡고 있는 개발자 김진실입니다.
브랜디에 입사한 지 어느 날이 좋은 이틀 차, 팀장님으로부터 광고 시스템을 1분기 안에 출시해야 한다는 이야기를 들었습니다.
??? : 녜??? 잘 못 들었습니다?

어떻게 만들어졌는지 많이 궁금하셨을 거로 생각합니다. 브랜디 조직 내에 생긴 지 얼마 안 된, 이 개발조직이 대체 뭐 하는 곳일까요? 그들이 만든 광고 시스템이 어떤 구조로 움직이고 있는 걸까요?
Introduce My Service!
먼저 광고 서비스의 도메인을 소개를 드리고 싶습니다.
유저를 위한 도메인
유저에게 광고를 노출하기 위해서는 송출과 로그 처리가 필요합니다. 송출은 보여줄 데이터를 선정하고, 로그는 보여준 데이터를 수집합니다.
송출
송출은 말 그대로 유저에게 어떤 것을 어떻게 보여줄 것 인가입니다.
- Catalog : Commerce Data와 광고 Data를 어떻게 조립할 지를 결정합니다.
- Delivery : ETL이 제시해주는 Catalog Set을 통해 광고 송출 List를 생성합니다.
- ETL : 어떤 광고 소재를 사용할지 데이터를 Picking하고, Scoring과 Ranking을 통해 노출 위치를 결정합니다.
로그 처리
로그 수집은 유저의 행동 로그를 수집 후 분석합니다. 이 유저가 어떤 상품을 보았나, 클릭했나, 구입한 거를 추적합니다. 그래서 로그를 처리하는 과정에서는 1개의 API 서버와 2개의 워커 군단이 움직이고 있습니다.
- Stream : Raw Data 수집기
- Cleansing(Worker) : Raw Data 정제기
- Pricing(Worker) : Clean Data 기반 정산기
Seller를 위한 도메인
Seller의 상품을 광고 소재로 만들기 위해서는 상품, Pay 도메인이 있습니다.
- 상품 : Seller가 광고주로 가입하면, Seller 상품을 광고 소재로 등록 후 관리합니다.
- Pay : Seller 인입 시 계좌를 만들어 유상, 무상 포인트의 입출금을 관리합니다.
AS-IS에는 어떤 문제점이 있었을까?
- 각 지면 데이터가 중복이 너무 심했어요.
- 성능이 너무 느려요.
- 송출 데이터 생성
- 로그 수집
- 몇 번째 페이지에서 호출이 오는 건지 알 수가 없어요.
TO-BE는 어떻게 문제를 개선했나요?
- 각 지면의 데이터 생성을 ETL이라는 데이터 생성 구조를 만들었어요.
- 각 서비스를 분리하고, 작업을 단순화 했어요.
- 송출 도메인이 가지고 있는 세부 도메인이 무려 3개! (데이터 생성, 데이터 조회, 데이터 조립)
- 로그 수집을 하는 서비스 도메인을 3개로! (수집, 정제, 정산)
- App에서 호출 할 때, 호출 시 page_num를 추가로 받는 작업을 요청했어요.
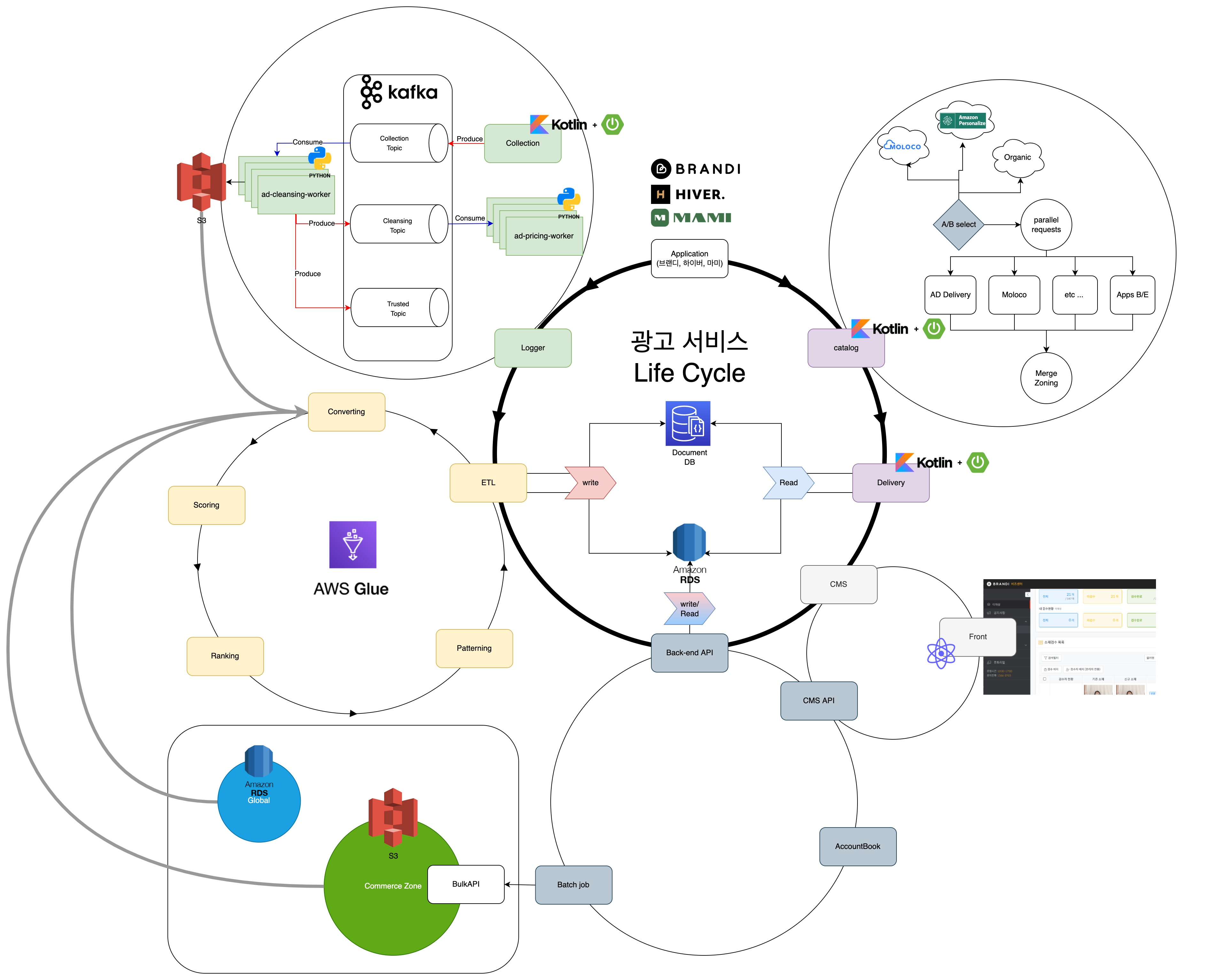
Kotlin을 Back-end 언어로 도입했습니다.
기존에 서비스들은 Python을 베이스로 백엔드 개발을 진행하고 있었습니다. 하지만, 일부 서비스들은 특성상 대규모 트래픽을 받아야 하는 순간에 적합하지 않다고 생각했고, Kotlin으로 전환했습니다.
어떤 이유로 도입한 거죠?
누군가는 묻습니다. 굳이. 하필이면. 왜 Kotlin이었냐 했는지 말입니다.

JVM 언어!
대용량 트래픽을 직접 받아내야 하는 서비스이기에, Runtime으로 운영되는 언어가 필요했고, PHP 기반의 서비스는 성능 측면에서 밀릴 수밖에 없습니다. 1 Request가 1 Process를 구성하면서 관계를 맺고 끊는 과정에서, 몇십에서 몇백 ms가 차이가 나게 되기 때문입니다. 반면 Java나 Kotlin은 그런 과정이 없기 때문에 MSA 형태의 서비스를 구축할 때 더 큰 이점으로 작용합니다.
Coroutine을 사용해 쉽게 Multi Thread를 구현
서비스 개발의 가장 궁극적 목표는 면을 구성하는 데이터를 가져와서 광고 데이터를 교체하는 것입니다. 그 과정에서 네트워크 통신 코스트를 효율적으로 쓰고 싶었고, Kotlin의 꽃 Coroutine을 사용하게 됐습니다.
Java보다 간결한 언어 컨셉
사실 개발하는 개발자분들이 Java, PHP, Python 등으로 모 언어가 각기 달랐습니다. 그래서 Kotlin으로 단결하기가 좋았는지도 모르겠습니다. Kotlin은 모든 언어의 가운데서 실용성이 뛰어나고, 객체지향 컨셉이 잘 잡힌 언어기 때문입니다. 그렇다고 허들이 없는 것은 아니었으나, 다행히 내부 구성원분들이 언어에 대한 이해를 잘 파악하고 개발을 진행해 주셨습니다.

MSA 저도 참 좋아하는데요. 그래서 한번 따라봤습니다.
도메인 기준으로 MS를 들어 A를 표합니다.
기존의 광고는 모놀리틱 구조의 서비스로 서비스 하나의 역할이 너무 컸습니다. 서비스에서 요구사항을 하나 충족하기 위해 변경된 부분이 오히려 버그를 일으키거나 정상적이지 못한 출력 결과를 주는 상황이 빈번했습니다. 모놀리틱 구조의 개발이 잘못된 게 아니라, 한 개의 서비스가 가지는 역할과 책임이 너무 무거웠던 탓에 담당 개발자의 통제력에서 벗어나곤 했습니다.
그래서 데스윙이 아제로스를 찢어발기듯 모놀리틱 서비스 구조를 역할이 필요로 하는 바에 따라 갈가리 찢어버렸습니다.

(??? : 안녕. 내 이름은 데스윙이야. 그냥 다 찢어.)
광고 Delivery(송출)는 읽기만 하면 됩니다.
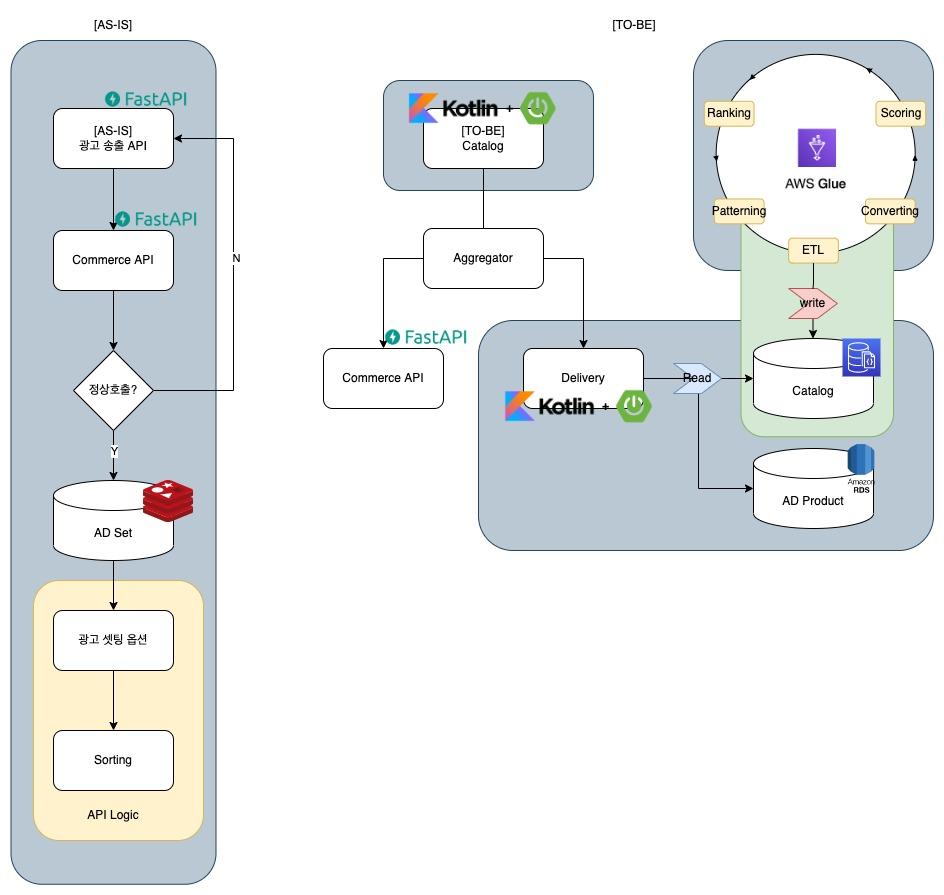
기존에 송출은 해야 할 일이 너무 많았습니다.
송출이 서비스가 나가려면 Commerce API를 호출하고, Redis에 있는 상품 데이터를 가져다가 송출 데이터 위치에 맞게 광고 catalog set을 직접 선정해야 했습니다. 하지만 고객은 서버의 작업을 기다려주지 않습니다. 데이터를 직접 선정하고 데이터를 위치에 맞는 노출을 지정하는 작업이 기존 delivery에는 무척 느리거나 중복 지면이 많이 생기는 고된 일이 돼버렸습니다. 성능도, 데이터의 정합성도 계속 의심할 수밖에 없었던 아주 칠흑 같은 시간이었습니다.

신규 데이터 송출은 역할을 위임합니다.
그래서 데이터를 Catalog Set을 만들어주는 역할을 ETL이라는 데이터 구조에 위임했습니다. 각자의 역할을 명확하게 분담해, 데이터를 만들어 주는 쪽에서 어떤 데이터가 각 지면에 위치해야 하는지 주기적으로 밸런스를 조정해 줍니다. 그래서 delivery는 ETL이 N개로 만든 가장 최신의 Catalog Set을 Mongo에서 조회해 RDB가 가지고 있는 Product Meta 정보를 조회하는 작업만 진행합니다. 이렇게 이쁘게 만들어진 데이터 규격은 Catalog가 송출은 데이터를 완성하는 데 큰 보탬이 됩니다.

(출격 송출 준비 완료!)
데이터의 조립은 Catalog가 담당합니다.
데이터 생성은 ETL이, 데이터 조회는 Delivery가 해준다면, 데이터 생성의 마지막은 Catalog가 Commerce 데이터와 조립을 함으로써 완성합니다.
1. 인터페이스를 통일합시다.
기존 Commerce 데이터는 호출되는 Endpoint에 따라 데이터 규격 관리가 파편화되어있는 것을 확인했습니다. 똑같은 상품이지만, 어느 Endpoint를 호출하냐에 따라 구성하는 property들이 달랐습니다. 이렇게 되면, 서비스 관리할 때 공수가 커지게 되고, 추가되는 property가 발생할 때마다 각 지면별로 핸들링해야 하는 비효율성이 있었습니다. Catalog는 확장성과 관리적 측면을 고려해서 통합 상품 규격을 제작해 각각 API마다 흩어진 상품 규격을 일원화했습니다.
2. Coroutine으로 호출을 조율합니다.
Catalog는 Commerce로 호출하는 API 데이터를 하이재킹합니다. 그 과정에서 광고 API 호출 때문에 기존 API가 느려지면 안 되기 때문에, IO Thread를 Async로 각기 호출합니다. 호출된 데이터들이 Catalog로 도착하면 위에서 통합된 인터페이스를 기준으로 Commerce상품과 광고상품이 모두 같은 옷을 입고 송출합니다.

(우리 안에 치킨이 광고가 있어!)
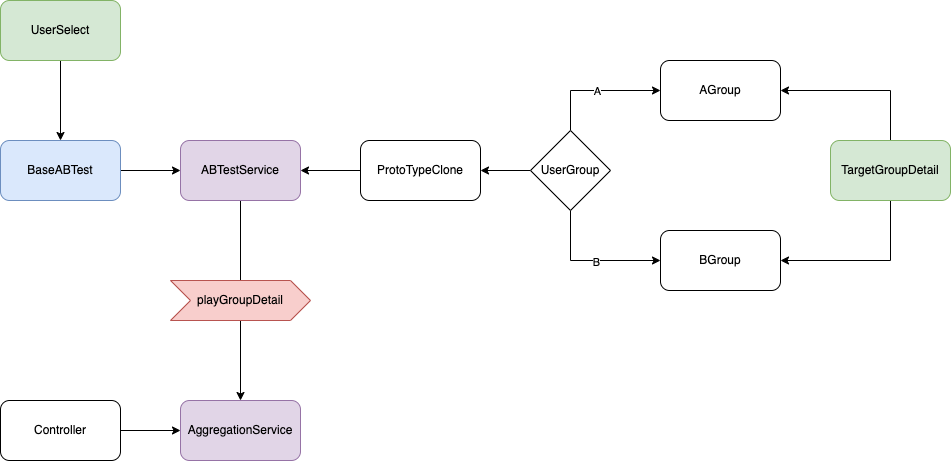
3. 미래의 Catalog는 A/B테스트를 위한 기반입니다.
Catalog를 구성하는 상품의 베이스 선정은 Catalog가 결정할 수 있죠. 추천 시스템을 위해 여러 개의 엔진을 테스트 베딩으로 삼고 싶다면,
- 노출하고 싶은 지면을 선정하고,
- 원하는 엔진을 골라,
- 테스터 선정 방식만 설정하면
다른 시스템에 별다른 작업 없이도 A/B 테스트 환경을 만들 수 있습니다. 추천 및 광고 서비스는 이런 구조를 통해 새로 사거나 또는 직접 만든 엔진이 진짜 효과적인지를 확인 할 수 있습니다.
Log 수집기는 Kafka로 데이터를 서빙합니다.
사실 서비스가 분리된 건 송출만이 아닙니다. 로그 서비스도 구조 개편이 필요했습니다. 핸들링하는 데이터를 기반으로 서비스를 타노스 했.. 분리하게 됩니다.

1. Log가 Kafka로 데이터를 서빙하게 된 이유.
이렇게 마이크로 서비스로 시스템이 분리되면, 그 사이를 오가면서 데이터를 서빙하는 필연적으로 등장하는 존재가 있는데, 바로 Kafka입니다. 저희 역시도 분리된 시스템 사이로 데이터 서빙하는 역할을 Kafka에 맡기기로 했고, 브랜디에서는 최초로 Kafka 도입사례가 됐습니다.
Kafka란?
여러 대의 분산 서버에서 대량의 데이터를 처리하는 분산 메시징 시스템이다.
메세지를 받고, 받은 메세지를 다른 시스템이나 장치에 보내기 위해 사용된다.
-출처: 실전 아파치 카프카 중
2. 3개의 토픽이 오리라.

AS-IS Logger 서비스는 데이터가 들어오면 정제작업이 끝나고 정산이 모두 끝나야 프로세스가 완료되는 구조였습니다. 그렇다 보니 평소에는 괜찮지만 트래픽이 몰리는 시간에는 로그 수집기의 안정성이 흔들릴 수밖에 없었습니다.
TO-BE Logger 서비스는 Raw Data에 Message Producing하면 각 Consumer들이 데이터를 필요한 작업을 한 뒤, 다음 토픽으로 새로운 Message Producing 합니다. 3개의 토픽은 각각의 활용에 맞게 데이터가 정제되는데, 각각의 용도는 아래와 같습니다.
RAW_DATA : Amplitude 형태의 수집 데이터
Raw data는 amplitude로 집계될 때 데이터를 그대로 수집 받습니다.
이 데이터는 광고뿐 아니라 ML이나, 그로스에서 유저의 행동을 분석하는 베이스 데이터가 됩니다.
AD_CLEAN_DATA : Raw Data 중 광고에서 필요한 필수 데이터
Raw Data에 연결된 Consumer Group이 만들어 내는 데이터입니다.
광고 필수 데이터만 정제 후 Producing 합니다.
SPEND_REQUESTED : Clean Data에서 정제한 정산을 위한 데이터
Clean Data에 연결된 Consumer Group이 만들어 내는 데이터입니다.
광고 정산을 위한 가격계산과 클릭과 노출이 얼마 됐는지 집계를 위한
광고 필수 데이터만 정제 후 Producing 합니다.
로그 수집기 구성도 비교
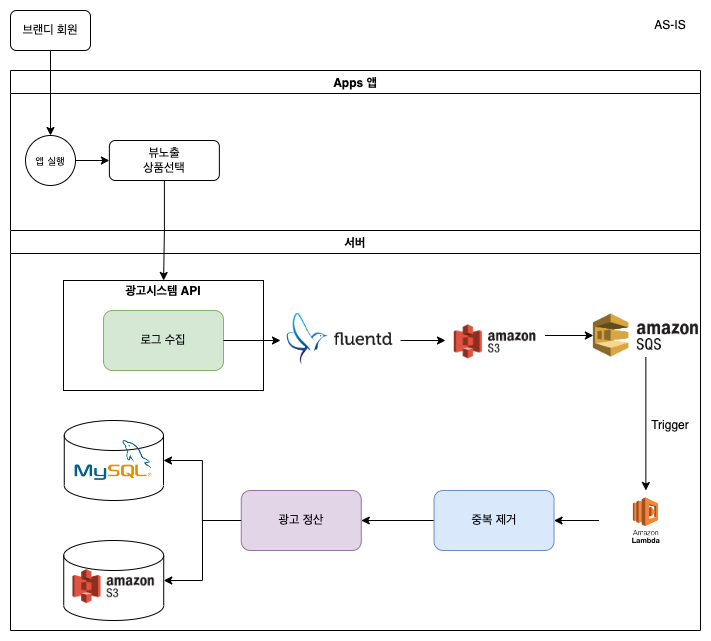
AS-IS. 로그 수집기 구성도
앱에서 Stream에 보낸 데이터를 S3에 업로드하고 SQS에 message를 발행하면 Lamda가 순차적으로 해당 데이터를 가져가는 것을 확인 할 수 있습니다. 이 과정에서 중복제거등을 하는 정제가 오류를 발생하게 되면 정산 서비스에도 필연적으로 영향을 미칠 수 있습니다.
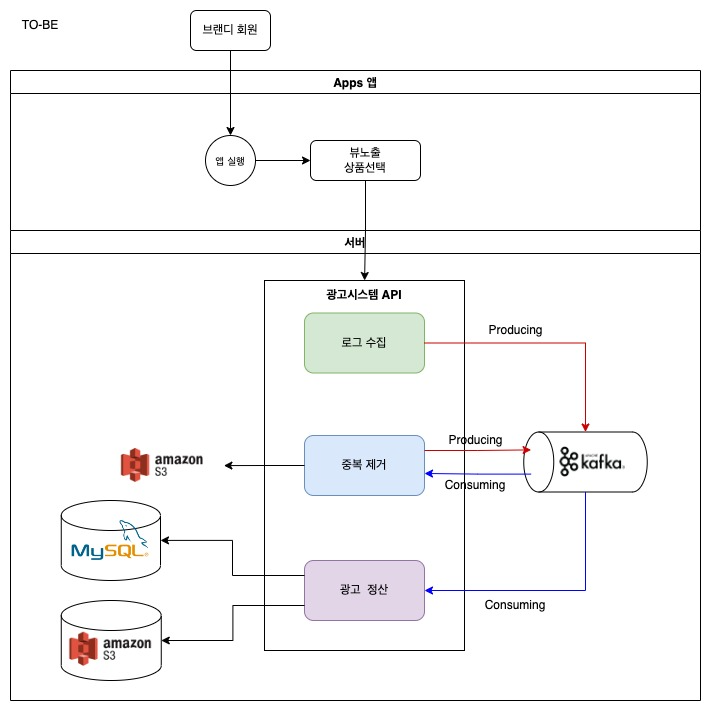
TO-BE. 로그 수집기 구성도
개선된 로그 수집기에서는 Stream으로 인입된 로그가 Kafka Topic에 신규 message를 Producing한다는 점에서는 기존과 비슷하지만, 정제와 정산도 독립된 Topic으로 관리가 되고 있어, 정제에서 오류가 발생하더라도 버그 픽스 후 신규 Consumer Group을 통해 서비스를 다시 시작할 수 있습니다. 각각의 서비스는 Consuming으로 연결되어 있지만, 각각 독립적으로 데이터를 처리하고 있습니다.
마무리하면서
저도 입사한 지 얼마 되지 않아서, 이렇게 큰 서비스를 급작스레 만들게 돼서 부족한 부분이 많았지만, 모두가 같이 노력한 결과로 광고 서비스가 무사히 정식 오픈이 됐습니다. “진짜 이게 만들어질 수 있나?”라는 의심의 시간도 있었지만, MVP 스펙에 큰 변동이 없어 끝까지 밀고 나갈 수 있었던 거 같습니다. 광고 서비스는 아직도 해야 할 과업이 많이 남아있습니다. 서비스 고도화는 물론이고, 서비스에 대한 확장성도 고려해야 합니다. 또 서비스가 빠르고 정확하게 운영될 수 있도록 검수에 대한 부분들도 고려 중입니다.
이후 저는 브랜디 기술 블로그에 로그 고도화에 대한 이야기와 블루프린트 고도화 이야기로 찾아오겠습니다.
김진실 | 광고실 광고개발팀



