브랜디 ML팀의 Change Point Detection (CPD) 모델 도입기
최영준
2022-11-30
안녕하세요 데이터 최적화실 ML팀에서 데이터 분석가 최영준입니다.
오랜만에 브랜디 랩스의 포스팅인 것 같네요. 오랜만인 만큼 새로운 주제로 찾아왔습니다.
여러분 혹시 이런 형태의 그래프를 보신 적 있으신지요?
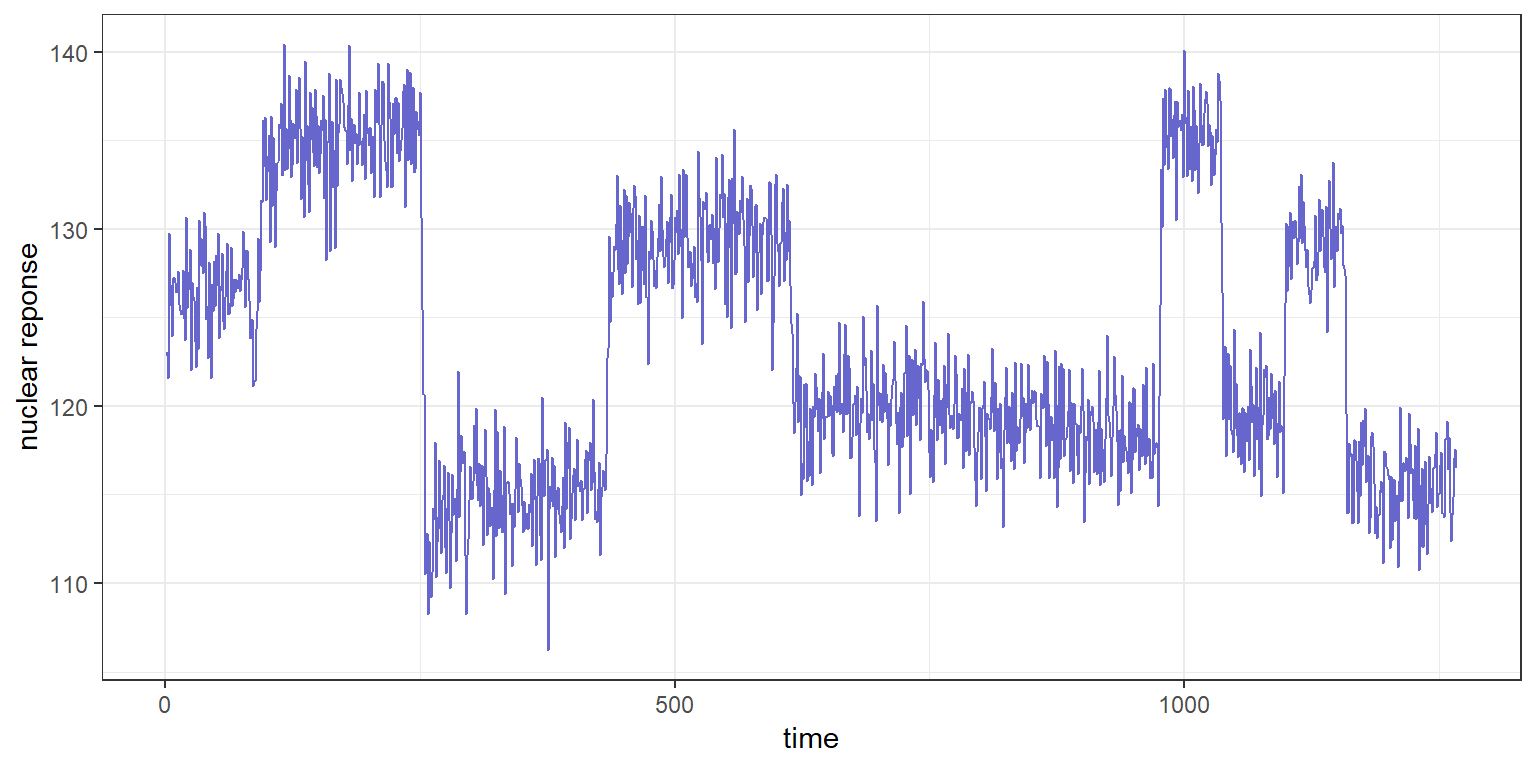
위 그래프처럼 심하게 왔다 갔다 하는 그래프가 아니더라도 갑자기 어떤 지표가 급락했다던가, 급등했던 경험을 해본 적이 있으실 겁니다. 운 좋게 빨리 찾아내면 원인을 규명하고 조치를 취할 수 있지만, 그렇지 않은 경우에는 보고 수준으로만 넘어갈 수밖에 없는 것이죠,,,
저도 지난 7월 말에 이런 경험을 한 적이 있습니다. 정확히 어떤 조닝에 사용되는 모델인지는 말씀드리기 어렵습니다만, 저희 팀에서 서빙하고 있는 모델 중 하나가 5월에 갑자기 성능이 올랐으며, 그 성능이 계속 유지되고 있었습니다. CTR로만 약 0.7~8%p가깝게 상승한 수준이었습니다. 이 정도의 성능이 상승한 것이라면 어떤 외부적인 요소가 영향을 끼친 것이라고 생각했습니다만, 별다른 분석 작업은 진행하지 않았습니다. 그도 그럴 것이 2달 전의 일이라서 원인 규명이 어려웠고, 성능 하락이 아닌 상승의 이슈라서 깊게 파고들 동기가 부족했습니다.
이런 상황을 피하고자 지표들을 매일 확인하면서 변동사항을 체크하는 것이 일반적입니다. 그러나, 모든 지표를 매일 트래킹할 수 없을뿐더러 수학적인 근거 없이 변동사항을 육안으로만 체크해야 하는 단점이 있습니다. 이와 같은 일이 우리 팀에만 있는 일은 아닐 것이라는 생각이 들어, 모델을 도입하여 이런 문제를 해결하고자 했습니다.
브랜디에서도 다양한 부서의 사람들이 특정 지표를 매일매일 확인하여 해당 수치에 대한 증감 여부와 증감 폭에 대한 중요도 파악에 많은 시간을 쏟고 있었습니다. 수치 확인 같은 단순 작업에 쓰는 시간을 줄이고 보다 더 효율적인 업무를 위해 시작한 ML팀의 change point detection 모델 도입 프로젝트 시작합니다!
1. 모델 도입 요구사항 및 조건
시계열 데이터의 탐지모델을 생각하신다면, 대부분의 경우에 이상치 탐지 모델을 생각하실 것입니다. 그러나 브랜디의 경우에는 커머스 서비스인 만큼 요일별, 시간별 트래픽의 추세가 존재하여 최고점과 최저점의 폭이 어느 정도 있는 편입니다. 그러다 보니 데이터를 작은 시간 단위로 쪼갤수록 튀는 값들이 존재할 가능성이 큽니다. 이런 데이터의 경우 이상치 탐지 모델을 적용하게 되면 튀는 값들을 감지하게 됩니다. 모델의 감지 능력이 과도하게 민감해지는 것이죠. 감지 능력이 과도하게 민감하다면 detecting의 결과가 지저분해져서 모델 도입의 의미가 없는 결과를 낳게 될 수 있습니다.
그렇기 때문에 특정 포인트의 이상치 점수 탐지 보다는 데이터들의 평균이 바뀐다든지, 추세가 변하는 변동 사항에 대해서 감지하는 시스템이어야 합니다. 또한 점진적인 변화가 아닌 급작스러운 변화에 대응하기 위한 프로젝트이기 때문에 큰 변화에만 맞출 필요도 있구요.
그리고 다른 부서의 업무에도 도움이 되고자 이 프로젝트를 시작한 것이기 때문에 해당 알고리즘의 원리를 깊게 알지 못하는 사람도 추가적인 분석 없이 도입할 수 있는 모델이어야 합니다. 즉, 다양한 데이터에도 자유롭게 적용할 수 있어야 합니다. Alert 시스템으로서 당연한 것들인 ‘빠른 감지’와 ‘실시간 데이터 감지’는 설명은 생략하도록 하겠습니다.
2. 기존 방법과 맞지 않는 점 및 도입 모델 결정
2-1. 전통적인 ARIMA 기반 이상치 탐지 모델
시계열 데이터에 대한 alert 시스템을 얘기하면 제일 먼저 생각하는 것이 ARIMA기반 모델인데요. 시계열 예측 모델을 이용하여 특정 포인트에 대한 예측값을 계산하고, 실제 데이터와 얼마나 동떨어져 있는지에 대한 정도를 z score라는 점수로 계산합니다. 예측값에 대한 신뢰구간을 설정하고, 이 구간을 벗어나는 수준의 z score가 나온다면 이상치일 확률이 높다는 것입니다.
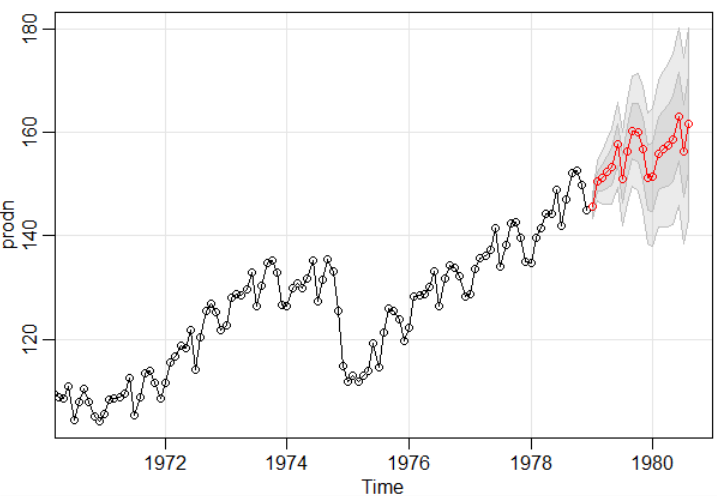
하지만, 이와 같은 방법은 우리의 요구사항에 맞지 않는 부분이 존재합니다.
-
특정 포인트의 이상치 점수 탐지 보다는 데이터의 평균이 바뀌거나 추세가 변하는 변동 사항 감지여야 한다.
전통적인 ARIMA의 경우에는 특정 포인트의 이상치 점수 탐지에 가깝습니다. 이는 브랜디의 데이터 성질과 맞지 않기 때문에 그대로 적용하기는 어렵습니다. 이 때문에 특정 포인트의 ARIMA 기반의 z score로 alert하게 되면 결과가 지저분해질 수 있습니다.
-
해당 데이터뿐만 아니라 다양한 데이터에도 적용할 수 있어야 함
가장 큰 이유인데, ARIMA 같은 모델은 데이터에 적용하기 전에 데이터에 요구되는 사항들이 많이 존재합니다. 데이터가 non-stationary 하면 안 되고, ACF, PACF 같은 그래프를 확인해서 파라미터들을 튜닝해야 합니다.
이런 점들로 인해 다양한 데이터에 빠르게 적용하는 것이 목표인 것에서는 맞지 않기 때문에 기각했습니다.
2-2. CPD - change point detection (offline detection)
이상치 탐지 분야를 넘어 CPD 분야에서는 트렌드의 변화를 인식하여 해당 데이터의 추세가 변화하는 것을 감지하는 방법이 존재합니다. 오프라인 detection의 경우에는 과거 데이터를 확인하여 어느 시점에서 추세가 변화했는지 인식하는 방법입니다.
그중에서 대표적인 파이썬 패키지가 ruptures로 존재하기 때문에 도입하기도 쉽고, 특정 포인트에 대한 이상치 탐지가 아닌 데이터의 추세가 변하는 부분을 확인할 수 있어서 이 프로젝트의 목적과도 부합합니다.
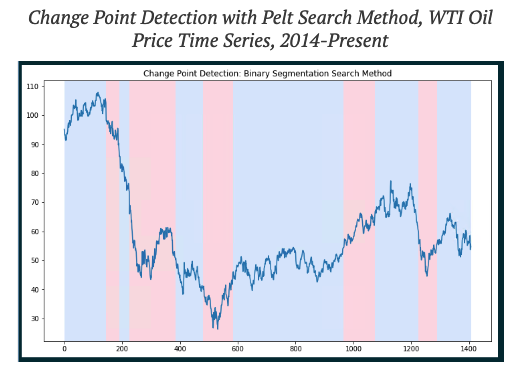
그러나 해당 모델의 경우에는
- 현재 시점에서 과거 데이터의 이상치 탐지를 하는 것이 아닌, 현재 시점에서 현재 데이터의 이상치를 탐지하는 것이 목표
를 충족하지 못합니다. 현재 시점에서 과거 데이터를 탐지하는 수준밖에 되지 않습니다. 이와 같은 경우는 실시간으로 Alert를 받고 싶은 프로젝트의 목적과 부합하지 않기 때문에 기각했습니다.
2-3. CPD - change point detection (online detection)
CPD 중에서도 현재 시점에서 현재 데이터의 이상치를 탐지할 수 있는 경우인 온라인 detection을 도입하기로 결정했습니다. 2-2의 모델과는 많은 부분이 비슷하지만, 발생하는 데이터를 즉각적으로 계산하여 해당 포인트의 이상치 수준이 어느 정도인지 확인할 수 있는 것이 다릅니다.
이 부분이 오프라인 detection이 아닌 온라인 detection으로 결정한 주요 이유입니다.
3. 도입하려는 모델의 특징
온라인 detection에서도 고려해야 하는 점이 존재하는데, “해당 데이터뿐만 아니라 다양한 데이터에도 적용할 수 있어야 함” 이 부분이 미지수였습니다. 시계열 데이터의 경우에는 statinary한 특성이 보장되어야 적용할 수 있는 알고리즘이 많기 때문에 이 부분은 꼭 짚고 넘어가야 했습니다.
그래서, 하나의 프레임 워크로 non-stationary한 데이터에도 감지를 진행할 수 있는 논문을 참고하여 추가적인 시계열 데이터 분석을 통한 파라미터 튜닝 등 추가 작업을 줄일 방법을 선택했습니다.
3-1. SDAR(sequential discounting AR model learning)
시간이 지날수록 데이터도 같이 변하고, stationary였던 데이터가 non-stationary한 데이터로 변할 가능성이 존재합니다. 그러다 보니, 데이터에 적합한 파라미터가 시간이 지날수록 업데이트되는 경우도 존재합니다.
SDAR 알고리즘은 이 문제를 2가지 방법으로 해결하는데요.
- On-line estimation: 모든 순간 데이터가 관측될 때마다 파라미터들이 업데이트된다.
- Discounting property: 파라미터 r이 시간이 지날수록 과거 데이터들의 영향을 지수적으로 감소시킨다. 이것으로 non-stationary 데이터 소스 문제를 해결 가능함
2번을 자세히 설명하면 다음과 같습니다.
결국에 이 알고리즘도 이상치 감지를 기반으로 하고 있기 때문에 평균과 분산이 중요한데요. x_{t}값에 대한 분포가 정규분포임을 가정한 확률밀도 함수를 기반하고 있습니다.
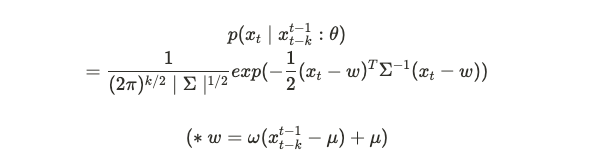
그렇다면, 여기서 평균과 표준편차에 대한 값을 나타내는 mu와 시그마는 시간이 지나면서 특정 범위를 넘는 데이터를 학습하면서 outlier detection에 둔감해질 수 있습니다. detection에 둔감해진다면 적절한 성능을 내지 못하기 때문에 해당 모델에 의미가 없어집니다.
그렇다면 해당 파라미터들을 과거 데이터에 영향을 시간이 지날수록 덜 받는 방향으로 학습해야 합니다. Discounting property인 r을 활용하여 시간이 지날수록 과거 데이터에 영향을 덜 받도록 할 수 있습니다.
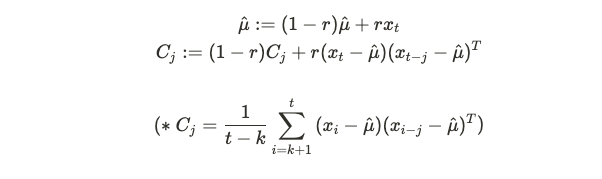
for each time t(=1,2,…,) 동안 반복하면서 과거 데이터의 영향을 줄이고 새롭게 받아들이는 데이터의 영향을 더 크게 만들 수 있습니다.
3-2. outlier detection과 change point detection을 moving averaged score로 연결
Outlier detection으로 계산된 점수들을 이동 평균해서 다시 Outlier detection과 동일한 방식으로 점수를 계산하는 방식으로 change point를 감지해냅니다.
- 이때 사용되는 T를 파라미터로 지정 가능, T’는 int(round(T/2.0))
약식으로 수식을 적으면 다음과 같습니다.
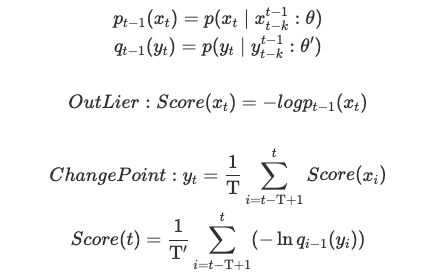
논문에서는 이를 통해 data stream 에서 change point 를 detecting할 수 있다고 언급했습니다.
즉,
1) x_{t_1}까지의 값들로 가우시안 분포 기반의 x_{t}의 아웃라이어 스코어를 계산하고
2) 그렇게 나온 값들을 윈도우 사이즈 T로 이동평균을 내어 y_{t}값을 계산하고
3) 그렇게 계산된 y_{t}를 이용해 다시 아웃라이어 스코어를 해당 윈도우 사이즈 T로 합하고, T’로 나누어 최종 스코어를 계산한다.
*Moving averaged를 사용하지만 사용하는 알고리즘 자체가 Outlier detection을 moving averaged하여 changepoint detection하는 것이기에 1) 너무 많은 이동평균을 이용하는 것이 아닌가 하는 의심과 2) 이동평균을 사용하면 변화에 둔감하여 빠르게 인지할 수 없을 것이라는 의심으로 인해 실험을 진행했고, 좋은 성능을 내는 것을 확인했습니다. 그러나 이 포스팅과는 성격이 맞지 않아 자세한 실험 세팅과 결과는 생략하였습니다.
4. Data ETL Pipeline Architecture
이렇게 어떤 알고리즘을 이용하여 CPD를 수행할지에 대해 결정했으니, 해당 모델을 이용하여 슬랙으로 Alert 받을 수 있도록 데이터 파이프라인 설계와 개발 작업에 대해 설명드리도록 하겠습니다.
해당 설계와 개발은 같은 ML팀의 데이터 엔지니어 양원석님께서 진행해주셨습니다. 현재 브랜디 ML팀은 AWS 클라우드 환경에서 데이터와 관련한 모든 작업을 진행하고 있는데요.
ML팀에서 사용하는 AWS의 주요 서비스는 아래와 같습니다.(이번 프로젝트에 사용된 서비스)
- EMR(Managed Hadoop Ecosystem)
- SageMaker(Managed Machine Learning)
- Glue(Managed Apache Spark)
- MWAA(Managed Apache Airflow)
changepoint를 detection하기 위해서는 조닝의 CTR 데이터가 필요합니다. CTR 데이터는 User Event Log의 Click과 Impression 데이터를 이용합니다. User Event Log는 AWS MSK(Managed Apache Kafka)를 통해 4~6초 간격으로 AWS S3에 JSON형식으로 적재됩니다.
User Event Log 데이터에는 브랜디 유저의 각종 이벤트와 관련된 데이터가 존재하는데, 이번 프로젝트에서는 아래의 데이터들을 사용합니다.
- 이벤트 발생 시점
- 이벤트 발생 영역(이하 조닝)
- 이벤트 형태(상품 Impression, 상품 Click 등)
- 유저 번호
- 상품 번호
4-1. ETL Pipeline Architecture
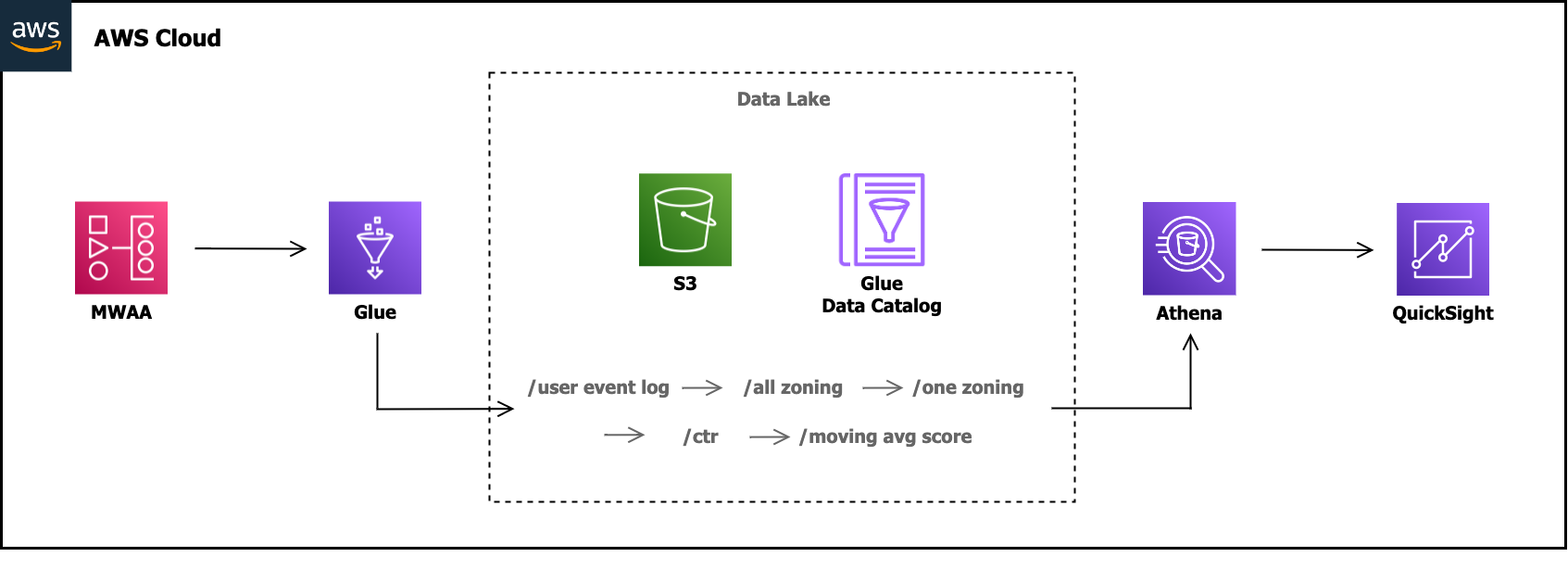
위 그래프는 abnormal detection ETL Pipeline Architecture 입니다. 최종 QuickSight로 시각화되기까지의 Glue Job의 ETL 작업은 아래와 같은 순서로 이루어집니다.
- User Event Log(Raw Level Event Stream Data from Kafka)
- User Event Log에서 조닝과 관련된 데이터 적재(이하 All Zoning)
- All Zoning 데이터에서 changepoint detection하기 위한 조닝의 데이터만 적재(이하 One Zoning)
- One Zoning의 CTR을 적재
- One Zoning의 CTR 데이터를 통해 moving average score를 적재
위와 같은 프로세스로 적재된 moving average score는 임계치와 비교하여 만약 설정한 임계치를 초과하면 Slack으로 Alert Message를 전송합니다.
4-2. MWAA(Managed Airflow) DAGs
아래 이미지는 ETL 프로세스 중 User Event Log에서 조닝과 관련된 데이터만 추출하여 적재하는 Glue Job을 실행하는 Airflow DAG의 Graph입니다.

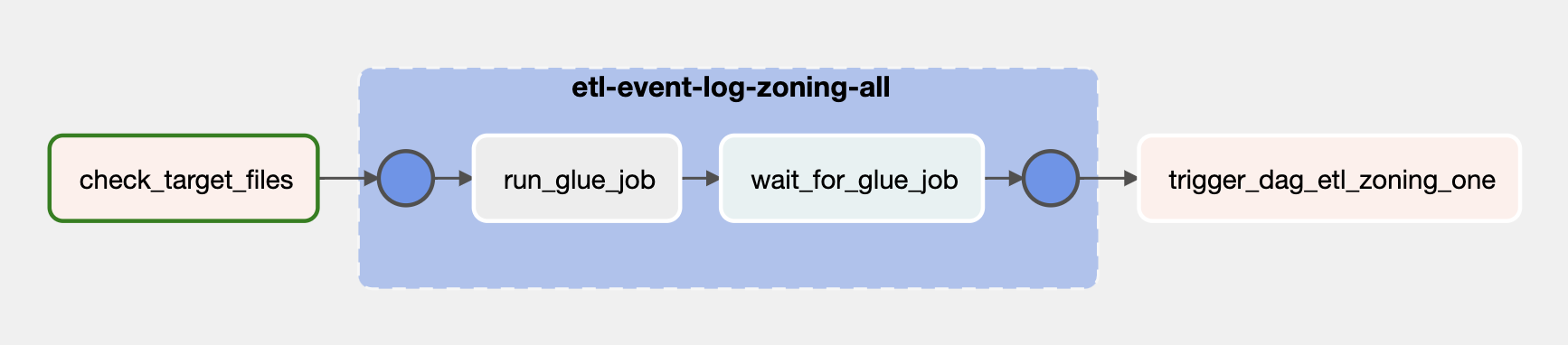
각 Task의 기능은 아래와 같습니다.
-
check_target_files: Python Operator
추출 대상이 되는 데이터를 선제적으로 확인하기 위한 Task입니다. 추출 대상 데이터는 최근 1시간 사이에 적재된 데이터이며, DAG가 실행될 때 Task Instance의 변수 중 data_interval_start와 data_interval_end 사이 S3에 적재된 데이터들의 유무를 확인합니다.(혹여 ETL에 필요한 데이터가 없는 경우 Glue Job을 실행하지 않기 위함)
- etl-event-log-zoning-all: Task Group
-
run_glue_job: AwsGlueJobOperator
전체 조닝에 대한 ETL 작업을 수행하는 Glue Job을 실행합니다.
-
wait_for_glue_job: AwsGlueJobSensor
앞서 실행된 Glue Job의 작업이 끝나면 Job의 Status를 Task의 Status에 반영합니다.
-
-
trigger_dag_etl_zoning_one: TriggerDagRunOperator
abnormal detection이 필요한 조닝의 ETL 작업을 수행하는 DAG를 실행합니다.
다음은 앞선 DAG의 마지막 Task인 trigger_dag_etl_zoning_one이 실행하는 DAG의 Graph입니다. 앞선 ETL 파이프라인을 통해 적재된 전체 조닝 데이터에서 abnormal detection이 필요한 조닝의 데이터를 따로 적재합니다. 또한 적재 시에 moving average score 계산에 필요한 CTR 데이터를 적재합니다.

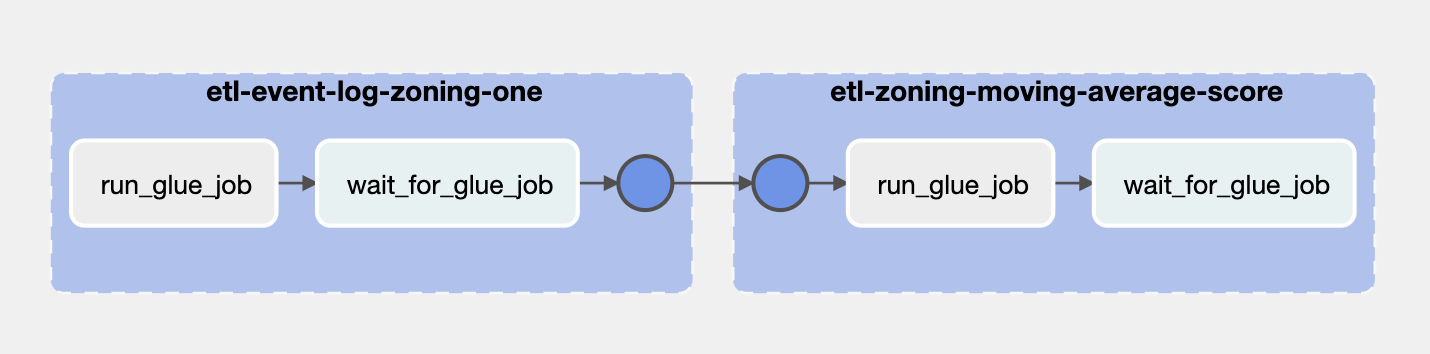
각 Task의 기능은 아래와 같습니다.
- etl-event-log-zoning-one: Task Group
-
run_glue_job: AwsGlueJobOperator
abnormal detection의 대상이 되는 조닝 데이터와 CTR을 적재하기 위한 ETL 작업을 수행하는 Glue Job을 실행합니다.
-
wait_for_glue_job: AwsGlueJobSensor
앞서 실행된 Glue Job의 작업이 끝나면 Job의 Status를 Task의 Status에 반영합니다.
-
- etl-zoning-moving-average-score: Task Group
-
run_glue_job: AwsGlueJobOperator
Upstream Task에서 적재한 CTR 데이터와 이전 3달 치 CTR 데이터를 Input으로 사용하여 moving average score를 계산합니다. 또한 도출된 moving average score가 임계치를 넘으면 현재의 모델이 좋지 못한 Output 데이터셋을 조닝에 송출한다고 판단하여 Slack에 Alert Message를 전송합니다.(추후 AWS Lambda + Slack으로 변경할 예정)
-
wait_for_glue_job: AwsGlueJobSensor
앞서 실행된 Glue Job의 작업이 끝나면 Job의 Status를 Task의 Status에 반영합니다.
-
4-3. 새로운 조닝 모델 도입에 대한 방안
현재 changepoint detection 적용한 조닝은 CB 알고리즘을 사용한 모델이 추천해주는 상품 조닝뿐입니다. 앞으로 ML팀은 각 조닝의 특성을 고려한 모델을 추가할 예정이며, 각 모델이 적용된 조닝에 changepoint detection 로직을 빠르게 적용하여 모델의 성능을 한시라도 빨리 파악할 수 있도록 Airflow DAG에서 parameter로 Glue Job에 변수를 전달하도록 설계하였습니다. 또한 다른 부서에서 특정 조닝의 CTR 지표나 다른 데이터 지표에 대한 변화 감지 필요성 및 요구를 염두하여 범용성에 대한 부분을 고려해 파이프라인을 설계하였습니다.
5. 결론과 실제 적용 결과
이렇게 시계열 데이터에 대한 Alert 시스템을 구축하였는데요. 이 프로젝트를 시작하게 된 계기인 ML팀 내 모델의 성능 지표를 가지고 슬랙으로 어떻게 들어 오는지를 보여드리도록 하겠습니다.
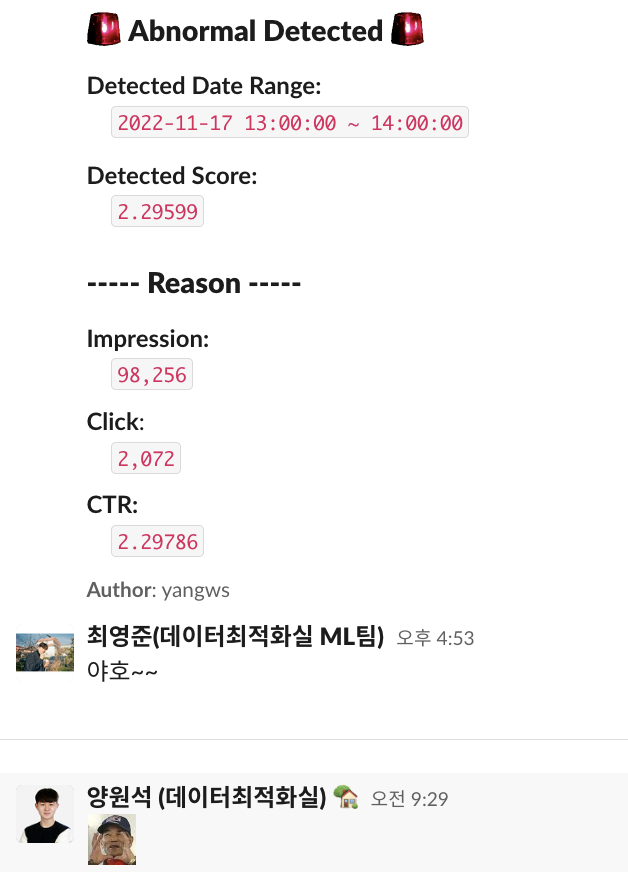
Detected Date Range는 감지된 change point의 시간대입니다. 이번 프로젝트에서는 한 시간 단위로 설정하였기에 시간 단위로 표출이 됩니다.
Detected Score는 이동평균과 모델 내의 계산을 거친 최종적인 스코어입니다. 저희는 테스트를 위해 특정 값으로 정하고 진행했는데요. 이는 얼마나 민감하게 반응하는가에 대한 정도이기 때문에 커스터마이징을 진행하고 해야 합니다.
또한 아래에 Reason에는 해당 시점에서의 지표들을 나열한 것인데요. 추후에 CTR뿐 아니라 다양한 지표들을 트래킹해야 할 경우가 존재하기에 다양한 지표들을 미리 달아 두었습니다.
이렇게 ML팀의 CPD 모델 도입기가 마무리되었습니다. 물론 해당 알고리즘이 모든 상황에 대비되는 것이고 모든 변화를 적절하게 감지하는 만병통치약 같은 모델은 아닙니다. 특히 점진적인 변화에 대해서는 감지하지 못하고 지나갑니다. 애초에 모델 자체가 그렇게 설계되었으니까요. 그러나 갑작스러운 변화에 대해서 감지하는 능력이 뛰어나고, 다양한 경우의 시계열 데이터에 대한 깊은 수학적 분석 없이도 적용 가능하다는 장점이 있습니다. 이번 프로젝트에 아주 알맞은 장점입니다.
이번 프로젝트가 브랜디 다양한 부서들이 성능 지표 체크에 쓰는 시간을 줄여 보다 더 효율적인 업무를 진행할 수 있기를 바라며 글을 마칩니다. 감사합니다.
참고 문헌 : Yamanishi, Kenji, and Jun-ichi Takeuchi. “A unifying framework for detecting outliers and change points from non-stationary time series data.” Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining . 2002.
Keković, G., Sekulić, S. Detection of Change Points in Time Series with Moving Average Filters and Wavelet Transform: Application to EEG Signals. Neurophysiology 51, 2–8 (2019).
최영준 | 데이터최적화실 ML팀 ML파트



