혼자서도 잘해요, 검색 시스템 구축과 운영
신누리
2024-08-23
안녕하세요, 뉴넥스 AI 검색팀의 신누리입니다.
현재 팀 내 유일한 검색 담당으로서, 뉴넥스의 패션 커머스 플랫폼들 -브랜디, 하이버, 서울스토어, 셀피- 전체 검색 프로덕트를 책임지고 있습니다. 구체적으로는 검색 데이터 파이프라인 구축 및 유지보수, 검색엔진 관리, 검색 API 개발, 검색 사전 관리 등 검색과 관련된 모든 부분을 매니징하고 있습니다.
클라우드(AWS) PaaS 및 SaaS 환경에서 검색 시스템을 A부터 Z까지 설계하고 매니징하는 경험은 처음 이었지만, 이전에 온프로미스(On-Premise) 기반의 자바(Spring) 환경에서 검색 서비스를 개발하고 ElasticSearch를 활용한 경험이 있었기 때문에 운영과 관리가 용이한 검색 내재화를 목표로 시스템을 구축하게 되었고, 현재까지도 검색시스템을 안정적으로 운영하고 있습니다.
이 경험을 바탕으로, 이번 포스팅에서 최소한의 휴먼 리소스로 여러 서비스의 검색 시스템을 운영할 수 있도록 구축한 검색 시스템을 소개하려 합니다.

🤔 검색 시스템 구축 이전
브랜디와 하이버는 기존에 SaaS 형태로 제공되는 타사의 검색 솔루션을 사용하고 있었습니다. 이는 상품 데이터를 주기적으로 JSON 파일로 추출하여 검색 솔루션과 연계하고, REST API를 통해 검색 질의를 수행하는 방식이었습니다. 이러한 접근법은 단순하고 편리한 점이 있었으나, 뚜렷한 한계점이 있었습니다.
-
비즈니스 및 요구사항 변화에 대한 빠른 대응의 어려움
대표적으로 전시 정책 변경이 있습니다. 검색은 전시 정책과 밀접하게 연관되지만, 정책 변경 시 내부 시스템에는 즉시 반영되지만 외부 솔루션에는 적용이 지연되는 문제가 있었습니다. -
확장성 부족
새로운 서비스를 추가할 때, 비즈니스 특성을 빠르게 이해하고 도메인을 반영하기 위해서는 내부 인력의 긴밀한 협조가 필요했지만, 외부 솔루션 사용 시 이 과정이 더 어려웠습니다. -
증분 색인 주기
하루에 한 번 전체 색인 주기가 있었고, 30분마다 추가/수정/삭제된 상품들을 증분 색인을 통해 반영했습니다. 도메인에 따라 30분마다 충분할 수 있지만, 패션 커머스 플랫폼에서는 빠른 수정 사항 반영이 필요합니다.
이러한 문제점들을 해결하고자, 저희는 더 유연하고 효율적으로 시스템을 운영하기 위해 내부에서 직접 검색 시스템을 구축하고 관리하기로 했습니다.
🎈검색 파이프라인 도입기
데이터가 검색 결과로 노출되기까지는 대부분 아래와 같은 단계로 이루어 집니다.
데이터 추출 → 데이터 색인 → 검색 질의 및 응답
데이터를 분석하고 구조화하여 검색 엔진이 빠르게 검색 결과를 반환할 수 있도록 데이터베이스나 인덱스를 구축하는 것
앞으로 데이터추출과 데이터색인 과정을 편의상 ‘검색 파이프라인’이라고 부르겠습니다.
즉, 검색 데이터 파이프라인은 체계적으로 설계된 프로세스로 주기에 따라 운영됩니다. 이 과정에서 유효한 데이터를 정교하게 추출(Extract)하고, 비즈니스 인텔리전스를 적용하여 최적화된 형태로 변환(Transformation)합니다. 최종적으로 이렇게 가공된 데이터는 검색 시스템의 효율적으로 색인(Indexing)되어, 정확한 정보 검색을 가능하게 합니다.
이 파이프라인 중에 색인은 검색엔진의 성능에 좌우되기 때문에 클러스터를 늘리거나 쿼리를 간략화 하는 과정으로 성능 개선이 가능하지만, 데이터 추출 및 변환 부분이 핵심 과제였습니다. 브랜디의 경우 200만 건 이상의 상품 데이터를 빠르게 추출하고, 비즈니스 정책을 효과적으로 반영하는 데이터 변환 과정이 필요했기 때문입니다.
이 과정에서 빠른 데이터 추출을 위해 ML팀 리더 최성조님(현재는 AI검색팀 리더)께서 검색 데이터 파이프라인을 PoC로 구현하셨습니다. 덕분에 검색 파이프라인은 데이터 엔지니어링 원칙을 바탕으로 설계되었습니다.
먼저 아키텍처를 확인한 후, 데이터 관점에서 자세히 살펴보겠습니다.
전체색인 아키텍처 및 시퀀스
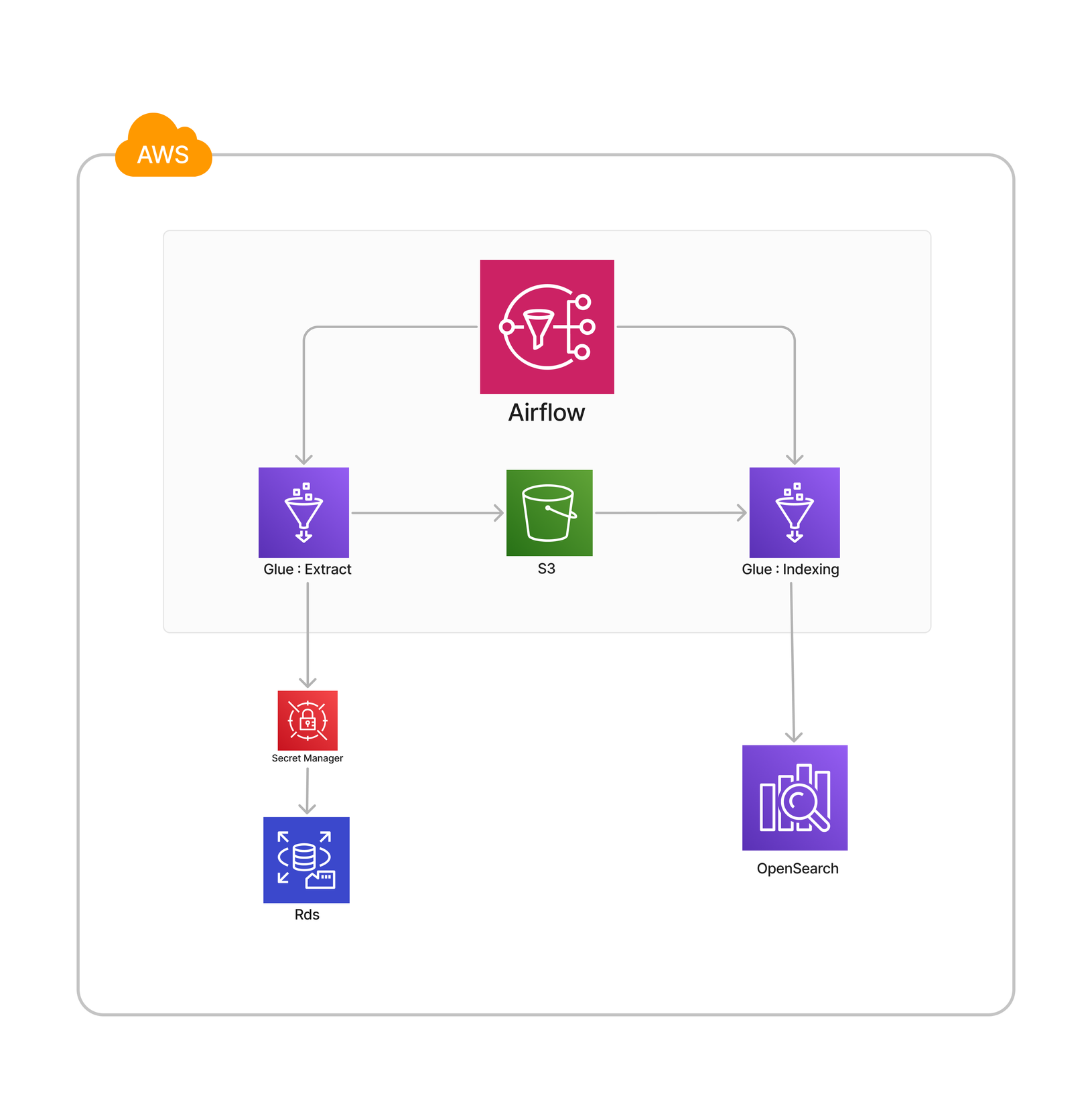
| Airflow (MWAA) |
AWS의 워크플로우 관리 도구(오케스트레이션) 서비스로, 스케줄링을 손쉽게 관리할 수 있으며, 작업 실행 시작부터 종료 시점까지 모두 관리 가능합니다. |
| Glue | AWS의 ETL(Extract, Transform, Load) 작업 서비스로, 수행 이력과 로그 확인이 가능하며, 스케줄링 없이 각 작업을 직접 수행할 수도 있어 매우 편리합니다. |
| S3 | AWS의 객체 스토리지 서비스 |
| Opensearch | AWS에서 제공하는 검색엔진 |
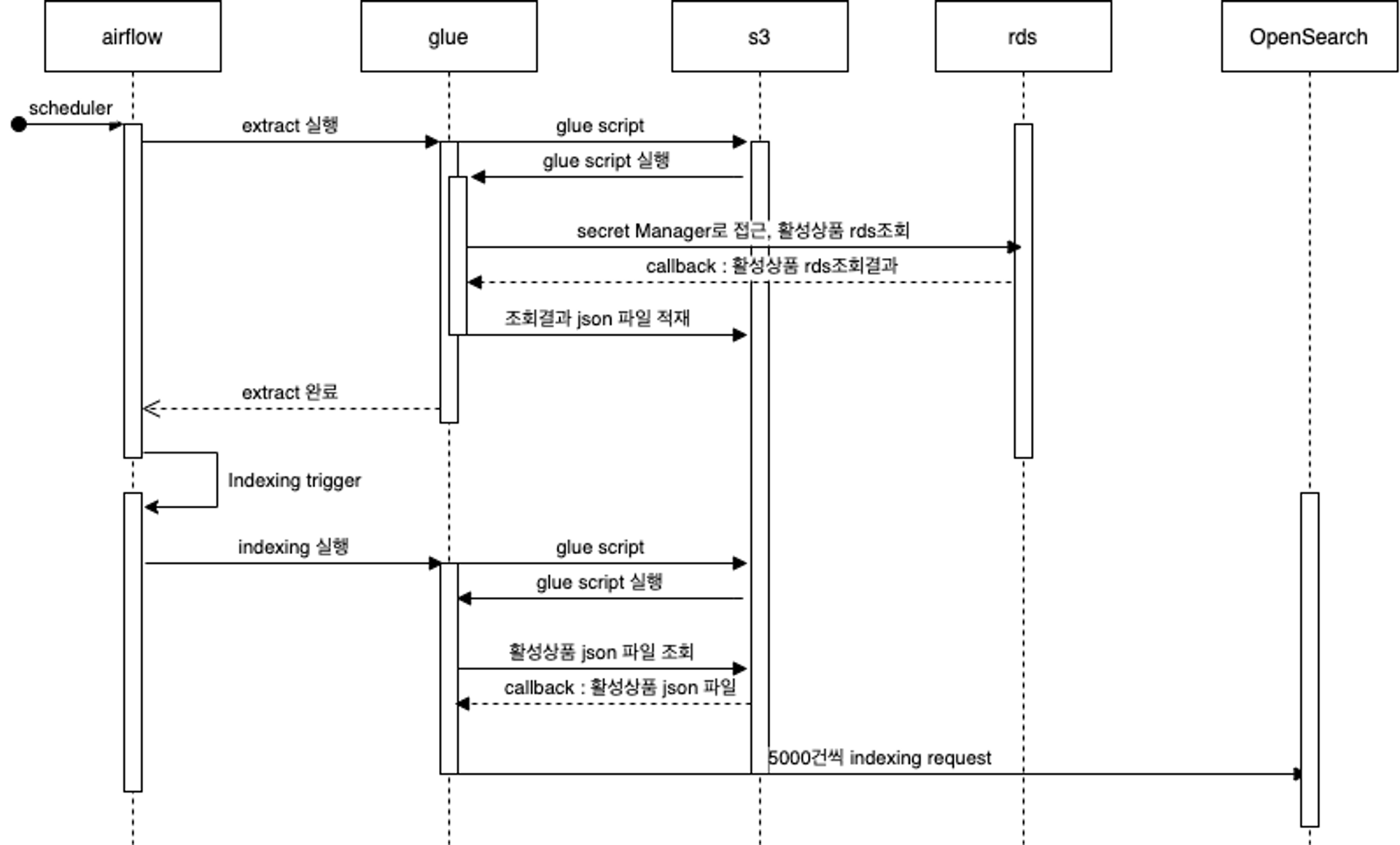
구성도에 따라 스케줄링 실행부터 색인 완료까지의 과정을 순서대로 살펴보겠습니다.
데이터 추출
- Airflow: 설정된 스케줄에 따라 데이터 추출을 위한 AWS의 ETL 도구인 Glue Job을 실행합니다.
- Glue: 활성 상품 정보는 데이터베이스(RDS)에 저장되어 있으며, 이 데이터를 Apache Spark를 사용해 추출합니다.
데이터 변환
- Glue: 추출된 데이터를 바탕으로 비즈니스 로직을 적용하여 JSON 형태의 칼럼방식으로 저장하는 Parquet 파일로 변환합니다.
- S3: 변환된 Parquet 포맷의 S3 버킷에 저장됩니다.
데이터 색인
- Airflow: 데이터 추출 Glue Job이 종료되면 트리거가 활성화되어 데이터 색인을 위한 Glue Job이 실행됩니다.
- Glue: S3 버킷에 저장된 데이터를 읽어 OpenSearch의 Bulk API를 통해 인덱싱 작업을 수행합니다.
💡설계 시 데이터를 빠르게 추출하고 정책을 효율적으로 반영할 수 있도록 추가로 고려한 점은 다음과 같습니다
-
스케줄링 및 스크립트 변경 용이성
스케줄링과 스크립트 변경이 용이해야 합니다. AWS Airflow는 워크플로우 관리 도구로, 스크립트에서 스케줄링과 트리거 설정이 간편하게 이루어질 수 있습니다. 콘솔 화면을 통해 모든 DAG 작업의 이력을 편리하게 확인할 수 있어, 검색 파이프라인 관리에 적합합니다.
-
수행 이력 및 로그 적재
수행 이력과 로그를 적절히 기록하고 관리할 수 있어야 합니다. AWS Glue는 수행 이력 확인이 가능하며, ETL 작업을 서버리스로 수행할 수 있어, 데이터 처리 과정에서 발생하는 로그와 이력을 효율적으로 관리할 수 있습니다.
-
자동화
전체 프로세스를 자동화하여 인적 오류를 줄이고, 일관성 있는 데이터 처리를 보장해야 합니다. Airflow와 Glue는 앞서 아키텍처에서 확인된 바와 같이 자동화된 데이터 파이프라인을 구축하는 데 효과적입니다.
-
데이터 병렬 처리
대규모 데이터 처리에서는 병렬 처리의 효율성을 최대한으로 끌어올리는 것이 핵심입니다. Spark는 데이터를 메모리 내에서 처리하며, 여러 노드에 분산하여 병렬로 작업을 수행할 수 있기 때문에 속도가 빠르고 안정성도 뛰어납니다. 테이블을 스캔할 때 직렬 처리(serial processing)를 사용하면 데이터 크기가 증가함에 따라 쿼리 처리 시간도 길어지게 됩니다. 특히 수백 기가바이트 이상의 데이터를 직렬로 처리할 경우 상당한 시간이 소요될 수 있습니다. 반면, AWS Glue에서 Spark를 사용해 데이터를 병렬로 분산 처리하면 코어 수에 비례해 처리 시간이 획기적으로 단축되며, 동시에 시스템의 안정성도 보장됩니다. 병렬 처리는 대용량 데이터 분석을 훨씬 빠르고 효율적으로 수행할 수 있는 중요한 방법입니다.
이러한 이유로 AWS Airflow와 AWS Glue를 선택하게 되었고 이처럼 AWS Managed Service를 적극 활용함으로써 효율적이고 관리가 용이한 파이프라인을 구축할 수 있었습니다.
데이터 엔지니어링의 관점에서 본 검색 데이터 파이프라인
앞서 소개한 아키텍처를 데이터 엔지니어링의 관점에서 살펴보겠습니다. 데이터 품질을 보장하고 시스템의 일관성, 확장성, 유지보수성을 높이기 위해서는 데이터 엔지니어링 라이프사이클(수명주기) 원칙이 중요합니다.
다음 그림을 살펴보겠습니다.
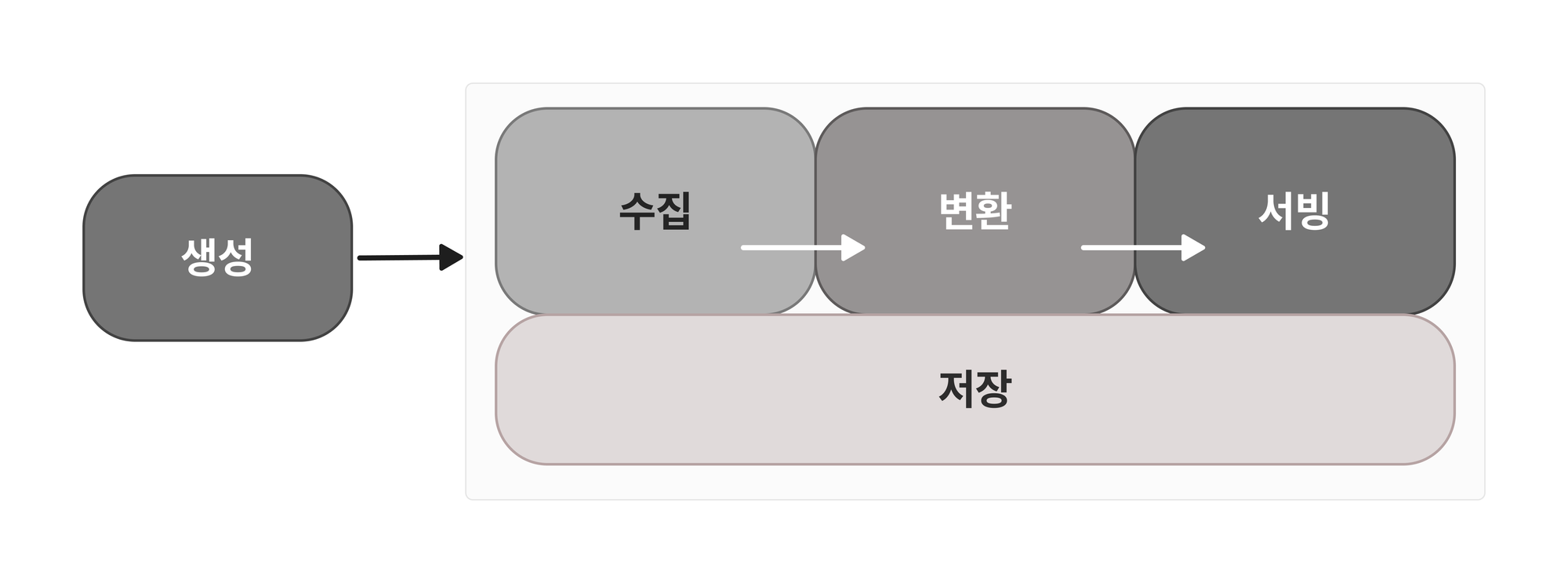
데이터 엔지니어링 라이프사이클(수명주기)의 각 단계를 검색 파이프라인에 적용해본다면, 다음과 같이 설명할 수 있습니다
- 데이터 생성, generation
- 정의 : 원천 시스템에서 데이터가 생성되는 단계입니다.
- 검색 파이프라인 : 상품 정보가 저장된 RDS가 해당합니다.
- 데이터 저장, storage
- 정의 : 모든 단계에서 중요한 역할을 하는 단계로, 원천 데이터가 수집, 변환, 서빙 등의 프로세스를 거치기 위해 사용되는 스토리지 시스템을 의미합니다.
- 검색 파이프라인 : S3가 이 역할을 수행하며, 데이터 레이크하우스로 기능합니다. 이 때 100GB 이상의 테이블에 적재된 데이터들은 1.5GB 가량의 S3 데이터로 간략하게 변환되어 저장됩니다.
- 데이터 수집, ingestion
- 정의 : 원천 시스템에서 데이터를 스토리지 시스템으로 이동시키는 과정입니다. 일반적으로 ETL 작업이 이 과정에 해당합니다.
- 검색 파이프라인 : RDS(원천 시스템)에 저장된 활성 상품 데이터를 수집하는 Extract Glue Job에서 이 역할을 합니다.
- 데이터 변환, transformation
- 정의 : 수집된 데이터에 비즈니스 로직을 적용하여 데이터 모델링을 수행하는 단계입니다.
- 검색 파이프라인 : Extract Glue Job에서 인덱싱에 적합한 데이터프레임을 생성한 후, 이를 S3(데이터 레이크하우스)에 적재하는 과정이 이에 해당합니다.
- 데이터 서빙, serving
- 변환된 데이터를 실질적인 비즈니스 목적으로 활용하는 단계입니다.
- 검색 파이프라인 : Indexing Glue Job이 S3에 저장된 Parquet 파일을 읽어 검색엔진에 인덱싱하는 과정이 이 단계에 해당합니다.
물론 데이터 수명주기와 검색 데이터 파이프라인이 완전히 일치하지는 않습니다. 검색엔진에 인덱싱된 데이터는 데이터 웨어하우스 역할도 수행하기 때문에, 검색 질의 과정을 서빙(Serving)으로 정의한다면 Indexing Glue Job을 데이터 변환(Transformation)으로 볼 수 있기 때문입니다.
이처럼, 데이터 엔지니어링 관점에서 데이터 품질을 보장할 수 있으며, 수명주기 별로 단계적으로 나눈 덕분에 하나의 단계에서 문제가 생겨도 모든 프로세스가 망가지는 일이 없습니다. 문제가 발생한 단계만 다시 실행하면 되기 때문입니다.
스크립트 예시
실제 사용하고 있는 코드를 간략화 하여 Airflow와 Glue 스크립트 예시를 살펴보겠습니다.
with DAG(
dag_id="dag_id",
tags=["tag1", "tag2"],
default_args={
'owner': 'brandi',
'start_date': datetime(2023, 9, 12, 13, 0, 0),
'on_failure_callback': slack_alert_bot.alert_fail_message,
'on_success_callback': slack_alert_bot.alert_success_message,
'retries': 1
},
catchup=False,
# cron 방식의 스케줄링 설정
**schedule_interval="0 20 * * SAT"**
) as dag:
task = trigger_glue_trigger_job(
group_id='group_1',
job_name="extract_job",
# 현재 작업 종료 시 실행되는 trigger job name
**trigger_dag_id="trigger_indexing_job",**
script_args={
'--arg_1': '1',
'--arg_2': '2',
'--arg_3': '3'
},
trigger_conf={
'trigger_params_1': '1',
'trigger_params_2': '2'
}
)
task
Airflow Dag Script
cron 방식의 스케줄링 설정과 해당 작업 종료 후 실행되는 트리거를 설정합니다.
# 데이터 병렬처리 시 읽어올 파티션 수를 설정하고 파티셔닝 될 때의 기준 열, 범위 설정
_products = _reader.option("dbtable", "스키마.테이블명") \
**.option("numPartitions", 10) \
.option("partitionColumn", "id") \
.option("lowerBound", _lower_bound) \
.option("upperBound", _upper_bound) \**
.load() \
.select(
col("ID"),
col("NAME"),
col("DISPLAY_TYPE")
)
# 비즈니스 로직을 추가한 데이터 변환
_product_df = _products \
.select(
col("ID").cast(StringType()).alias("id"),
col("NAME").alias("product_name"),
when(col("DISPLAY_TYPE") == '1', True).otherwise(False).alias("is_display") \
# 파티셔닝 설정
_product_df.repartition(128).write.mode('overwrite').parquet(_output_path)
Extract Glue Script
- 원천 데이터를 읽어올 때 파티션을 설정하여 데이터 병렬 처리
- 데이터 변환 후 데이터 프레임 생성
- 데이터 프레임을 128개로 파티셔닝 하여 output path(S3)에 저장
_products.rdd.repartition(300)
.mapPartitions(convert_to_json)
.coalesce(1)
.foreachPartition(partial(bulkApi_전송_메서드, host=검색엔진_호스트, index=인덱스명))
Glue Script (Indexing)
DataFrame을 RDD (Resilient Distributed Dataset)로 변환 후 300개의 파티션으로 분할하여
오픈서치에 벌크로 인덱싱 진행
스크립트를 간단히 살펴보면, Airflow DAG 스크립트에서 스케줄러와 작업(task)을 지정할 수 있다는 점을 확인할 수 있습니다. 또한, 데이터를 읽고 쓸 때 Glue에서 Spark를 활용해 데이터 파티셔닝을 수행하여 병렬 처리를 최적화할 수 있습니다. 인덱싱 단계에서는 검색엔진 클러스터의 사양에 맞춰 repartition 파라미터를 조정하여 벌크 인덱싱 작업의 배치 크기를 효율적으로 관리할 수 있습니다.
콘솔화면 예시
Airflow 콘솔
Dag들이 각각의 작업으로 나열되어 한눈에 파악
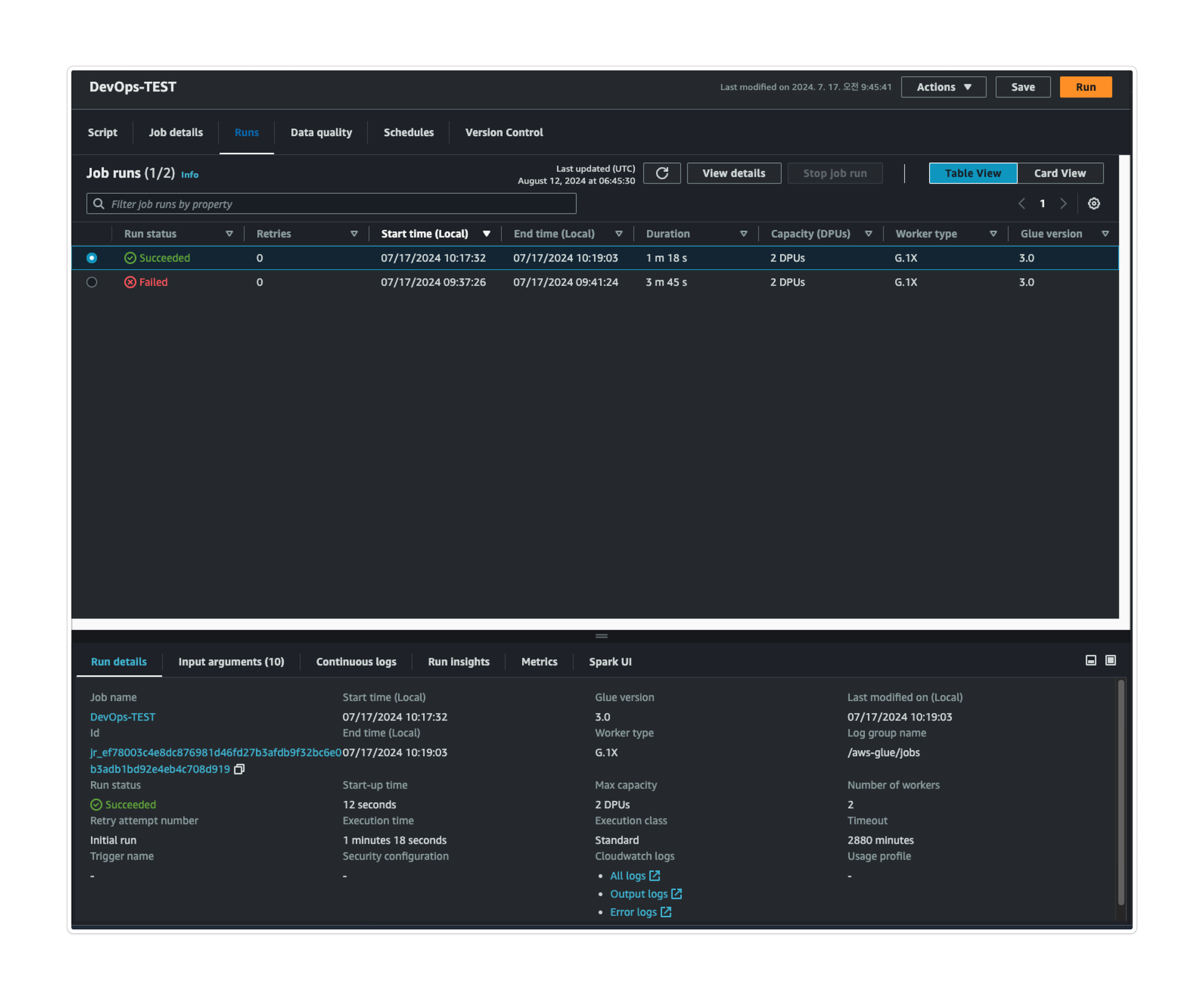
Glue 콘솔
각 작업 별 수행이력과 로그 확인 가능
검색 파이프라인은 효율적이고 편리한 관리를 통해 운영 리소스를 최소화하는 데 초점을 맞춰 설계되었습니다. 이 과정에서 데이터 처리에 대한 패러다임이 변화하는 것을 직접 체감하며 놀라운 경험을 했습니다. 개발자들에게는 ‘낯설지만 매우 효율적인’ 아키텍처로 평가될 수 있을 것입니다.
만약 AWS Managed Service를 사용하지 않았다면, 각 프로세스마다 별도의 구축 및 운영 인력이 필요했을 것입니다. 예를 들어 cron 배치 시스템, 빠르고 안정적인 데이터 추출 시스템, 검색엔진 클러스터링, 모니터링 등 다양한 요소를 직접 관리해야 했을 것입니다.
그러나 Airflow와 Glue를 활용한 ETL 파이프라인을 구성함으로써, 데이터 처리를 유연하게 조정할 수 있었고 모든 단계를 자동화해 관리 부담을 크게 줄일 수 있었습니다. 또한, 비즈니스와 요구사항이 변동될 때에도 신속하게 대응할 수 있다는 점이 큰 장점이었습니다. 스크립트를 바로 수정하고 테스트할 수 있어, 별도의 빌드 과정 없이도 빠르게 조정이 가능하다는 점이 매우 편리했습니다.
자동화와 편리성 뿐만 아니라 각 단계의 역할을 명확히 분리하여 속도를 보장하고 유지보수의 효율을 높였습니다. 이는 AWS Managed Service 환경에서 Spark 병렬 처리를 적극적으로 활용한 덕분입니다.
이처럼 자동화와 유연성을 기반으로 혼자서도 모든 서비스의 검색 데이터 파이프라인을 충분히 관리할 수 있습니다.

🎈증분색인 도입기
검색 색인 과정은 전체색인과 증분색인 두 가지로 나눌 수 있습니다. 모든 상품데이터를 추출하여 새로운 인덱스로 생성하는 과정을 ‘전체색인’이라 하고, 추가, 수정, 삭제된 상품 데이터를 인덱싱하는 과정을 ‘증분색인’이라고 합니다. 초기 구축 단계에서 중요한 목표 중 하나는 기존 검색 시스템의 주기와 결과의 일관성을 유지하여 운영에 혼란을 주지 않는 것이었습니다. 이를 위해 전체색인과 증분색인을 동일한 구조로 구현했고, ‘전체색인은 하루에 한 번, 증분색인은 특정 시간마다’ 수행했습니다. 이제는 검색 시스템이 안정적으로 내재화되었으니, 증분색인의 주기를 더욱 줄여야 할 때입니다. 완전한 실시간 색인은 아니지만, 몇 초의 주기를 가지는 near realtime을 구현할 준비가 되었습니다.
처음에는 Apache Kafka의 커넥터인 Debezium을 활용하는 것을 고려했습니다. Debezium은 CDC(변경 데이터 캡처) 기능을 지원하기 때문에 변경된 데이터를 바로 색인하는 데 적합하다고 생각했기 때문입니다.
두 번째 후보는 기존에 구현되어 있던 메시지큐 AWS SQS를 사용하는 것이었습니다. 메시지큐를 이용하면 변경되는 데이터를 거의 실시간으로 전달받을 수 있기 때문입니다.
결국, 저희는 AWS SQS를 선택했습니다. 이미 도입된 시스템이어서 추가 비용이 들지 않고, 관리 포인트가 적어 비용과 리소스를 모두 절약할 수 있다는 큰 장점이 있었기 때문입니다. 또한, SQS 이벤트가 발생할 때마다 AWS Lambda를 트리거하도록 설정해 데이터 추출과 색인을 한 번에 처리할 수 있도록 구성했습니다.
증분색인 아키텍처
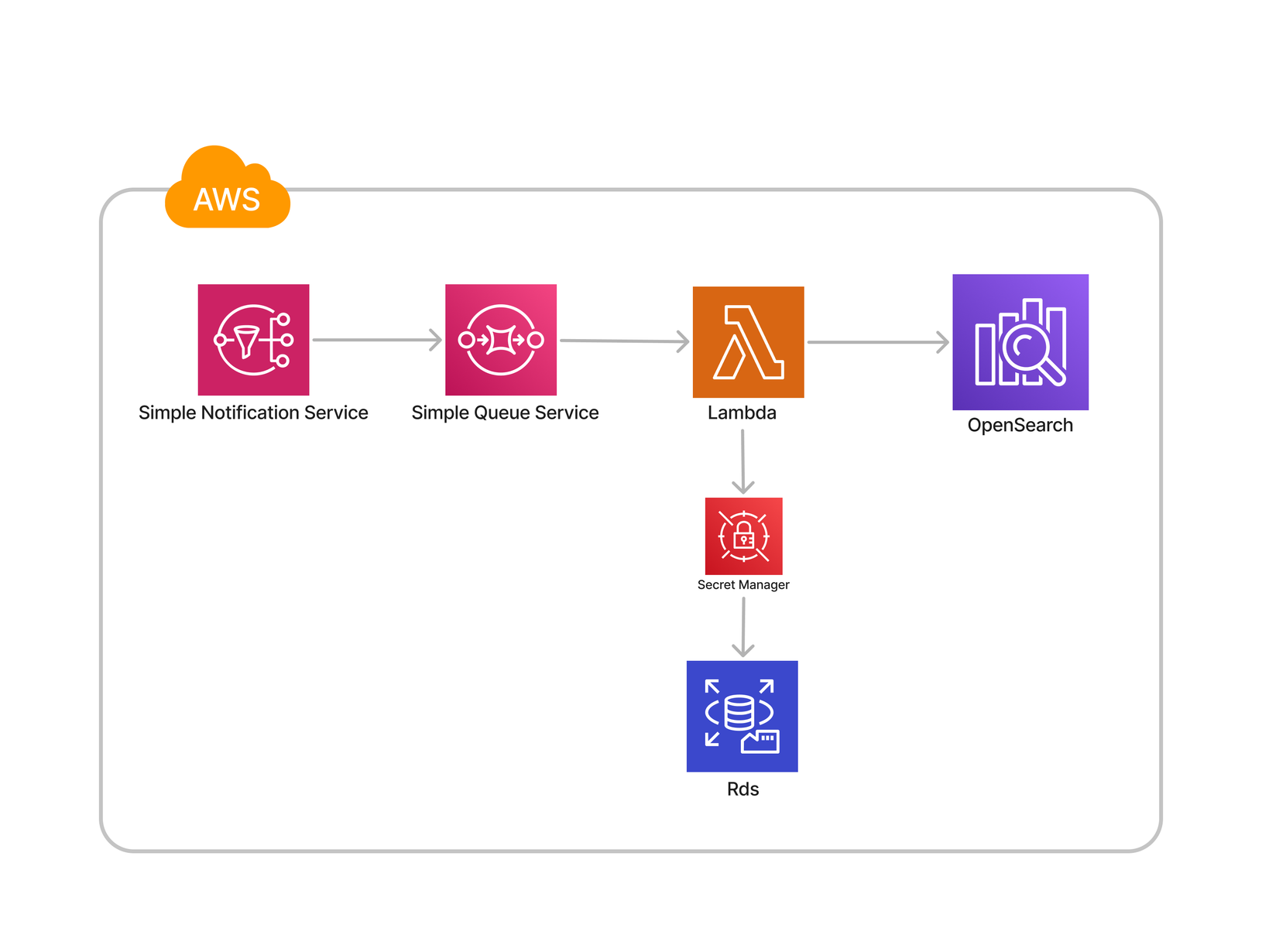
| SNS (Simple Notification Service) | application-to-application 메시징을 위한 완전관리형 게시/구독 AWS 서비스 |
| SQS (Simple Queue Service) | 마이크로서비스, 분산 시스템 및 서버리스 애플리케이션을 위한 완전관리형 메시지 대기열 AWS 서비스 |
| Lambda | 이벤트 기반 서버리스 컴퓨팅 AWS 서비스 |
이제 각 시퀀스를 따라가며 과정을 살펴보겠습니다.
상품변경 이벤트 발생 → SNS 이벤트 publishing → SQS queue → Lambda 실행
데이터 추출
-
SNS, SQS
변경된 상품 번호가 SQS에 메시지 큐 이벤트 형태로 추가됩니다.
-
Lambda
큐에 추가된 변경된 상품 번호를 감지하여 실행됩니다. Lambda 함수에서 RDS에 쿼리를 실행해 해당 상품 번호에 대한 정보를 읽어옵니다. Python과 Pandas를 사용해 추출된 정보로 데이터프레임을 생성합니다.
데이터 색인
-
Lambda
생성된 데이터프레임을 OpenSearch의 Bulk API로 전달해 색인 작업을 수행합니다.
이 구성에서 몇 가지 중요한 고려 사항이 있습니다.
- 변경 데이터가 수천 건 이상 발생하는 경우
- Lambda 함수의 동시 실행 문제
변경된 데이터가 대량으로 발생하거나, Lambda 함수의 동시 실행 요청이 과도하게 많아질 경우, 데이터베이스가 과부하되어 대량의 쿼리를 처리하기 어려워질 수 있습니다. 특히 변경 데이터가 천 단위 이상으로 증가하는 경우, 기존의 구조보다는 CDC(Change Data Capture) 방식을 사용해 색인을 구성하는 것이 더 적합합니다. 브랜디는 이 문제를 해결하기 위해 Lambda 함수 내에서 메시지큐 이벤트를 청크 단위로 분할(chunking)하여 쿼리를 전송하도록 설계했으며, 동시에 Lambda의 동시 실행 옵션을 조정하여 이슈를 해결할 수 있었습니다.
증분 색인 아키텍처를 고도화하면서, 기존 30분이었던 주기를 1분 이내로 줄이는 성과를 달성했습니다. 주기가 단축됨에 따라 검색엔진의 활용 범위도 단순한 검색 메뉴를 넘어 다양한 영역으로 확장되었습니다.
이전에는 검색 기능에서만 사용되던 검색엔진이 이제는 여러 기능에서 핵심적인 역할을 담당하게 되었습니다. 실시간성을 갖추게 되면서 단순히 검색 메뉴뿐만 아니라, 카테고리 페이지에도 검색엔진을 도입해 성능을 향상시키고, 데이터베이스의 부담을 줄이는 중요한 개선을 이룰 수 있었습니다.
그렇다면, 관리포인트는 증가했을까요?

SNS, SQS는 기존에 사용하던 서비스를 그대로 활용하면서도, 람다함수만 추가했기 때문에 개선된 성과에 비해 추가된 리소스는 최소화되었습니다.
덕분에 여전히 혼자서도 잘하고 있습니다.
🎈검색 API
지금까지는 데이터 추출과 색인에 대한 검색 파이프라인에 대해서만 소개해드렸습니다.
하지만 검색 시스템은 여기서 끝나지 않고 검색 질의 및 결과 반환 과정까지 포함해야 완성됩니다. 일반적으로 검색엔진(Opensearch, Elasticsearch)들은 엔진에 직접 쿼리를 요청하여 결과를 받는 방식으로 운영됩니다.
엘라스틱 서치 API 가이드
저희 개발팀도 초기에는 검색엔진에 직접 쿼리를 요청하는 방식을 사용했지만, 이 방식에는 한 가지 큰 문제가 있었습니다. 색인 필드나 요구사항이 변경될 때마다 검색엔진을 사용하는 모든 팀이 각각 쿼리를 수정해야 한다는 점 이었습니다.
이러한 문제를 해결하기 위해, 검색 API를 개발하게 되었습니다. 검색 API를 도입하면서 얻게 된 장점은 매우 큽니다. 복잡한 쿼리를 추상화하여 제공함으로써 사용자의 편리성이 강화되었고, 시스템 확장성도 확보할 수 있었습니다. 또한 검색엔진을 변경해도 검색API의 client만 변경하면 되기 때문에 사용자가 이를 인지하거나 코드를 변경할 필요가 없습니다.
검색엔진 쿼리 vs 추상화된 검색 API
{
"from": 0,
"size": 10,
"sort": [
{
"time": "desc"
},
"_score"
],
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "원피스",
"fields": [
"index.text",
"index.keyword"
],
"operator": "and"
}
}
],
"filter": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"category_id": "1"
}
},
{
"match": {
"category_id": "2"
}
}
],
"minimum_should_match": 1
}
},
{
"range" : {
"price": {
"gte": 1000,
"lt": 20000
}
}
},
{
"match": {
"id": "11111"
}
}
]
}
}
}
}
}
검색쿼리
depth가 깊고 복잡합니다
{
"from" : 0,
"size" : 10,
"query": "원피스",
"filter" : {
"category": {
"id" : ["1", "2"]
},
"id" : "11111",
"price" : {
"min" : 1000,
"max" : 20000
}
},
"sort" : "time"
}
추상화된 검색 API
검색 API 파라미터가 추상화되어 사용자의 편리성 증대
대부분의 검색엔진은 언어별 SDK를 제공하기 때문에 개발 작업도 비교적 수월합니다.
Elasticsearch Java API Client [8.14] | Elastic
이로써 검색 API 개발이 완료됨에 따라, 전체 검색 시스템 구축이 완성되었습니다. 이제 요구사항이 추가 되더라도 검색 API만 수정하면 되기 때문에 시스템 운영은 훨씬 더 편리해졌습니다.
🎈모니터링
검색 파이프라인이 모두 자동화되었지만, 운영 중에는 항상 예기치 않은 상황이 발생할 수 있습니다. 따라서 기능 개선과 문제 해결을 위해 모니터링이 필수적입니다.
저희는 검색 시스템의 모든 서비스를 AWS 기반으로 구축하여 모니터링을 용이하게 하고, 이상 현상이 발생할 경우 빠르게 인식할 수 있도록 모든 알림을 Slack으로 통합하여 수신하도록 설정했습니다.
검색 데이터 파이프라인
전체색인 : Airflow는 워크플로우 관리 서비스이기 때문에, 실행 중인 작업에 이상이 발생하면 이를 감지할 수 있습니다. 오류가 발생할 경우, Airflow의 DAG 스크립트에 Slack을 연결해 두면, 작업이 정상적으로 종료되지 않았을 때 지정한 문구로 알림을 전송할 수 있습니다.
증분색인: Lambda 함수에서도 Slack과 연동할 수 있으며, 람다 함수가 정상 또는 오류 결과를 반환합니다. 오류 발생 시, 스크립트에서 지정된 Slack으로 알림을 송신할 수 있습니다.
Glue Job Fail를 경고하는 뉴진스님… Slack 알림 봇
검색엔진 클러스터 상태 및 검색 API
Datadog : 데이터독은 AWS Managed Service의 상태를 연동할 수 있습니다. 따라서 검색 질의가 정상적으로 들어오는지 확인할 수 있는 설정을 통해, 문제 발생 여부를 모니터링할 수 있습니다.
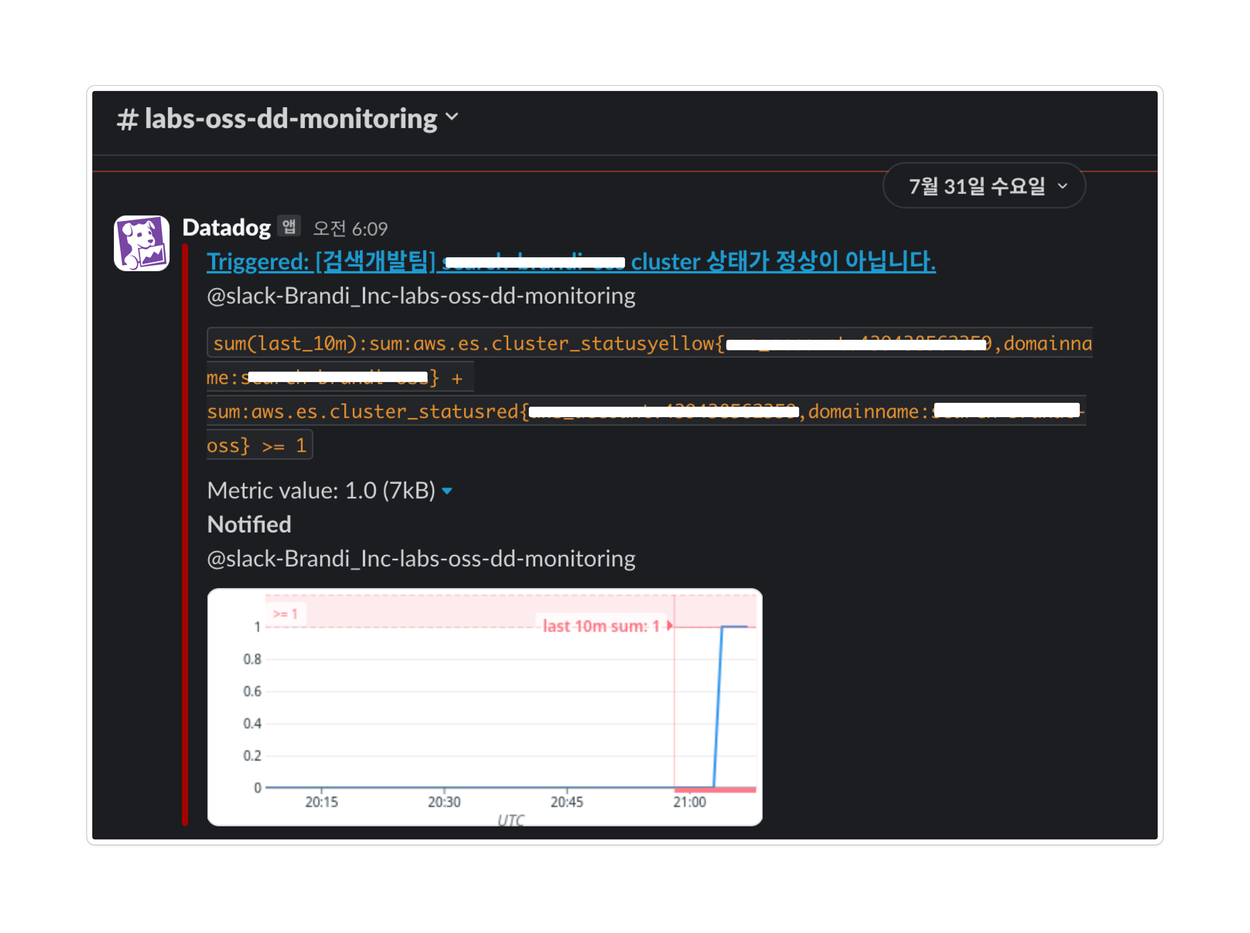
이렇게 모니터링과 이슈 발생 시 감지 및 대응이 편리하게 설정되어, Slack 메신저를 통해 문제를 빠르게 인식하고 조치할 수 있게 되었습니다.
🎈클라우드 vs 온프로미스
클라우드 환경에서의 데이터 파이프라인, 검색 API, 모니터링을 포함한 검색 파이프라인의 아키텍처를 살펴보았습니다. 이 중, 데이터 파이프라인 구성 시 온프로미스로만 구축했을 경우 ‘최소한의 관리’적인 측면에서 어떤 맹점이 있을지 비교해보도록 하겠습니다.
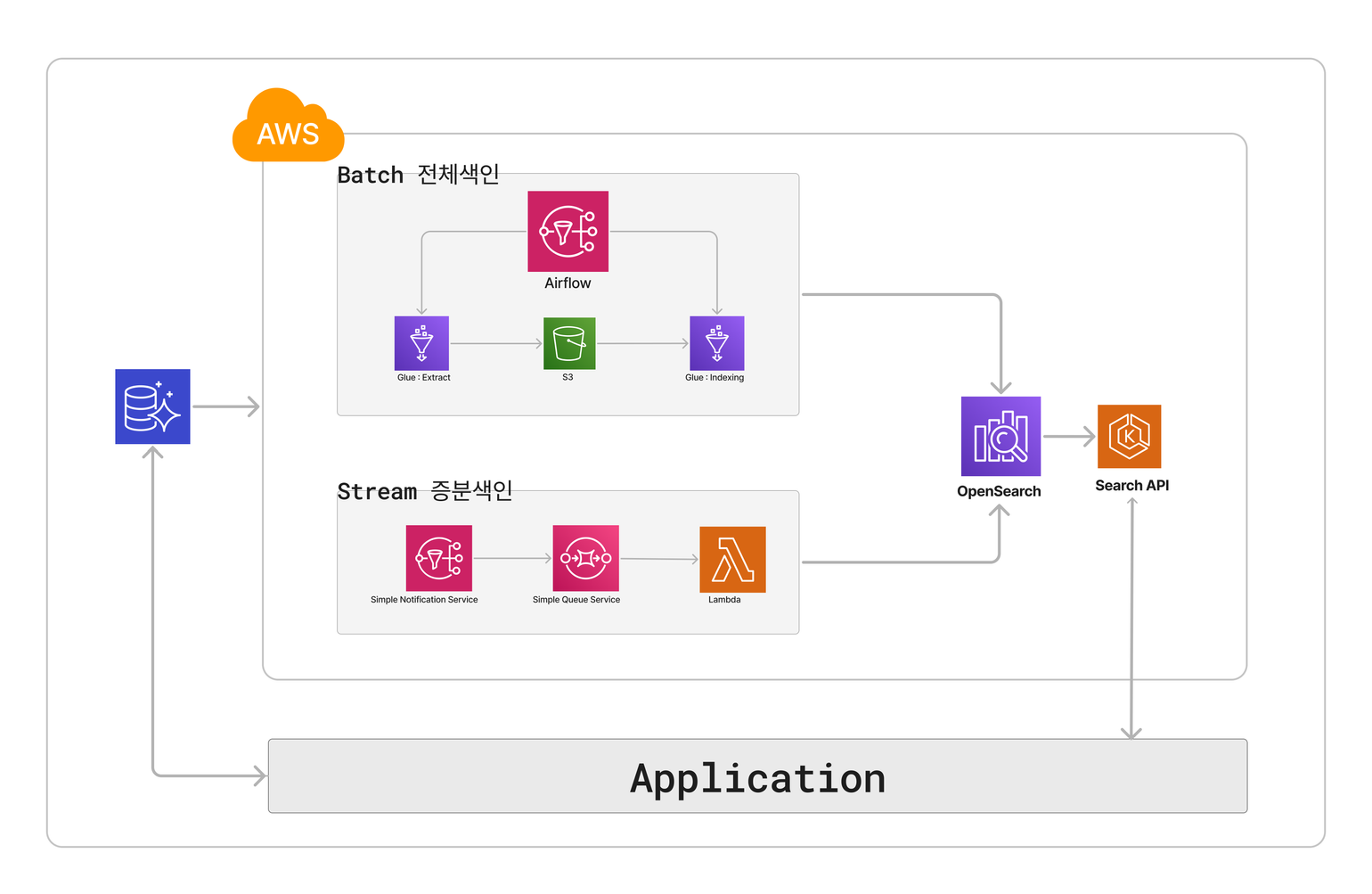
AWS 기반에서의 검색 파이프라인

온프로미스 환경에서의 검색 파이프라인
아래의 그림의 아키텍처 자체는 간단해 보이지만, 실제로는 상당한 노동력이 필요합니다. 데이터 추출 및 변환을 Spring Batch로 진행한다고 가정해 보겠습니다.
-
데이터베이스
100GB 이상의 데이터를 조회하는 동안 Spring Batch는 데이터베이스와 지속적으로 연결됩니다. 이를 통해 배치 작업의 시간을 조정하거나 데이터베이스의 사양을 고려하는 등의 추가적인 관리가 필요합니다.
💡 Spark를 활용하면 모든 테이블을 메모리에 올린 후 처리할 수 있어 데이터베이스의 부담을 줄일 수 있습니다
-
Spring Batch
데이터 파이프라인 대부분의 작업이 Spring Batch에서 수행됩니다. 스케줄러 설정, 데이터 조회, 데이터 파싱, 비즈니스 로직 처리, 검색엔진 인덱싱 등이 포함됩니다. 간단한 예시 코드는 다음과 같습니다:
@Component public class BatchScheduler { @Autowired private JobLauncher jobLauncher; @Autowired private Job indexUserJob; // 매일 새벽 1시에 실행되는 스케줄링 설정 (CRON 표현식) @Scheduled(cron = "0 0 1 * * ?") public void runBatchJob() throws Exception { JobParameters params = new JobParametersBuilder() .addLong("time", System.currentTimeMillis()) .toJobParameters(); jobLauncher.run(indexUserJob, params); } }cron 형식으로 스케줄링을 설정합니다
@Configuration public class BatchConfig { @Bean public JdbcCursorItemReader<Product> reader(DataSource dataSource) { return new JdbcCursorItemReaderBuilder<Product>() .name("productItemReader") .dataSource(dataSource) .sql("SELECT id, name FROM products") .rowMapper((rs, rowNum) -> { Product product = new Product(); product.setId(rs.getLong("id")); product.setName(rs.getString("name")); return product; }) .build(); } }데이터베이스에서 Product 데이터를 읽어옵니다. 데이터 추출 과정입니다.
public class ProductProcessor implements ItemProcessor<Product, Product> { @Override public Product process(Product product) throws Exception { // 추가적인 파싱이나 데이터 처리 로직을 여기에 작성 return product; } }데이터를 변환하는 역할을 합니다.
@Component public class ElasticsearchItemWriter implements ItemWriter<Product> { @Autowired private RestHighLevelClient client; private static final ObjectMapper objectMapper = new ObjectMapper(); @Override public void write(List<? extends Product> items) throws Exception { for (Product product : items) { IndexRequest request = new IndexRequest("products_index") .id(product.getId().toString()) .source(objectMapper.writeValueAsString(product), XContentType.JSON); client.index(request, RequestOptions.DEFAULT); } } }변환한 데이터를 elasticsearch에 인덱싱 합니다
@Configuration @EnableBatchProcessing public class BatchJobConfig { @Bean public Job indexProductJob(JobBuilderFactory jobs, Step step1) { return jobs.get("indexProductJob") .incrementer(new RunIdIncrementer()) .flow(step1) .end() .build(); } @Bean public Step step1(StepBuilderFactory stepBuilderFactory, JdbcCursorItemReader<Product> reader, ProductProcessor processor, ElasticsearchItemWriter writer) { return stepBuilderFactory.get("step1") .<Product, Product>chunk(10) .reader(reader) .processor(processor) .writer(writer) .build(); } }배치 작업과 스텝을 정의합니다. 앞서 정의한 클래스들을 연결하여 추출-변환-색인을 처리합니다
아주 단순한 기본 코드임에도 불구하고 고려해야 할 요소들이 많습니다. 예시 코드에는 작성되지 않았지만, 병렬 처리를 위한 멀티스레딩 구성을 추가해야 하며, 트랜잭션 관리와 청크 크기 설정도 중요한 부분입니다. 작업별로 철저한 예외 처리를 수행하고, 오류 발생 시 문제 발생 단계와 원인을 정확히 파악할 수 있도록 로그를 체계적으로 관리하는 것도 필수적입니다. 모든 단계가 Spring Batch에서 실행되다 보니, 데이터 추출 로직과 비즈니스 로직을 명확하게 분리하기가 어렵습니다. 또한, 요구사항이 변경되면 빌드와 배포 과정을 다시 거쳐야 하며, 오류가 발생하면 모든 작업을 처음부터 다시 시도해야 하는 문제도 발생할 수 있습니다. 시간이 지남에 따라 코드가 블랙박스화될 가능성도 있으며, 관리해야 할 작업이 1n개 이상으로 늘어나면 추가적인 인력과 리소스가 필요할 것입니다.
💡Airflow와 Glue를 사용하면 스케줄링과 작업을 완전히 분리할 수 있습니다. 또한 데이터 조회와 비즈니스 로직을 각각 독립적인 작업으로 분리하면 복잡도가 줄어들고 코드가 간소화됩니다. 콘솔화면에서 작업을 확인할 수 있기 때문에 작업갯수가 확장되어도 인력이 필요하지 않습니다.
-
온프로미스 검색엔진
마스터 노드, 데이터 노드, 코디네이터 노드 등 클러스터의 노드 옵션을 직접 설정해야 합니다. 기본 콘솔 도구가 없기 때문에 Kibana에서 모든 옵션과 대시보드를 구성해야 합니다.
💡관리형 검색엔진 서비스를 사용하면 클러스터 성능을 모니터링하고 자동으로 최적화하여 성능 문제를 예방할 수 있습니다. 또한, 업그레이드와 패치를 자동으로 진행하여 관리 부담을 줄여줍니다
즉, 온프레미스 서비스 기반의 환경에서 코드 중심으로 설계를 진행하면 관리 포인트가 많아질 뿐만 아니라, 병렬 처리, 트랜잭션 관리, 예외 처리 등 고려해야 할 사항이 많아집니다. 이러한 복잡성으로 인해 상대적으로 더 많은 인력과 리소스가 필요하게 됩니다.
🙆♀️ 앞으로의 계획
앞서 구성도에서 확인하셨듯이, 현재까지 저희는 AWS Opensearch를 사용해왔습니다. Opensearch와 Elasticsearch는 처음에는 동일한 서비스였지만, 라이센스 이슈로 인해 현재는 완전히 분리되어 각기 다른 성능과 기능을 제공하고 있습니다.
Elasticsearch는 업데이트 주기가 짧고, 솔루션 기능 개선이 활발히 이루어집니다. 특히, Kibana의 다양한 기능 덕분에 별도의 모니터링 툴 없이도 효율적인 설정과 관리를 할 수 있습니다. 실제 테스트 결과, 같은 비용대비 클러스터의 처리량과 인덱싱 속도에서 더 우수한 성능을 보였고, 무엇보다 벡터 검색 기능을 지원하여 텍스트 임베딩을 통한 검색 정확도 향상이 가능하다는 장점이 있습니다. 따라서, 저희는 Elasticsearch의 Managed 서비스인 Elastic Cloud로의 전환을 검토하고 있으며, 현재는 테스트 단계에 있습니다.
Elastic Cloud로 교체된 후에는 벡터 검색을 통해 유사 검색어 추천, 개인화된 검색 결과 제공 등 보다 유용한 기능을 구현할 수 있을 것 같아 기대됩니다.
🐱 마치며
사실, 혼자서도 관리가 용이한 검색 시스템을 구축하려는 목표로 작성한 포스팅이지만, 처음부터 끝까지 전적으로 혼자 진행한 것은 아니었습니다.
앞서 말씀 드렸듯이, AI검색팀의 최성조 리더님이 POC를 비롯하여 여러 서비스의 설계를 함께 구성해주셨고, 생소한 데이터 엔지니어링 학습에 ML파트 동료들도 많은 도움을 주었습니다.
특히나 저의 많은 실수에도 불구하고 이해와 배려를 해주시는 테크조직 여러분들 덕분에 큰 이슈없이 운영하고 있어요…. 항상 감사합니다 👍 ❤️
그럼 이만 글을 줄이며, 앞으로도 더욱 비즈니스에 도움되는 개발자가 되기 위해 노력하겠습니다.

참조
- Amazon MWAA에서 DAG 작업 - Amazon Managed Workflows for Apache Airflow
- Query DSL Elasticsearch Guide [8.14] - Elastic
- Elasticsearch Java API Client [8.14] - Elastic
- 함수에 대해 예약된 동시성 구성 - AWS Lambda
- 알림 - Datadog
- 데이터 과학과는 다르다…데이터 엔지니어링이란?
- AWS Glue이란 무엇인가요? - AWS Glue
- Documentation - Apache Airflow
- Amazon SQS 대기열에서 Amazon SNS 주제 구독 - Amazon Simple NotificationService
- Amazon SQS에서 Lambda 사용 - AWS Lambda
신누리 | Tech Data AI검색 개발팀



